TL;DR
Efficiently managing the Claude Code context window makes the difference between a productive session and one that goes in circles. Here are 10 concrete examples - from basic token monitoring to automatic compaction via hooks - to optimize every interaction with the agent. Learn to configure Plan mode, multi-sessions, and horizontal scaling strategies.
Efficiently managing the Claude Code context window makes the difference between a productive session and one that goes in circles. Here are 10 concrete examples - from basic token monitoring to automatic compaction via hooks - to optimize every interaction with the agent. Learn to configure Plan mode, multi-sessions, and horizontal scaling strategies.
Context management in Claude Code is the discipline of monitoring, optimizing, and distributing the 200,000 tokens available per session to maximize the quality of agent responses. Claude Code (version 1.0.x, based on Claude Sonnet 4.6) offers several native mechanisms to manage this context window.
exceeding 60% of the context window degrades response accuracy by 15 to 25%. Mastering these techniques transforms your daily workflow.
How to visualize context window usage?
Before optimizing anything, measure your actual token consumption. Claude Code displays a fill indicator in the status bar, but you can get more precise data.
To understand the fundamentals of the context window, consult the complete context management guide that covers the anatomy of the 200k tokens in detail.
Example 1: Check fill rate during a session
Context: You are in the middle of a refactoring session and want to know how many tokens you have left before automatic compaction.
# Type this command in the Claude Code prompt
/context
Expected result:
Context window usage: 47,230 / 200,000 tokens (23.6%)
|- System prompt: 3,200 tokens (1.6%)
|- Conversation: 38,400 tokens (19.2%)
|- File contents: 4,830 tokens (2.4%)
|- Tool results: 800 tokens (0.4%)
Estimated remaining capacity: ~152,770 tokens
Variant: Add the /cost command to see the financial cost associated with your token consumption. In practice, a session reaching 80% of the window consumes approximately $0.45 in input alone.
Key takeaway: Check your fill rate as soon as you exceed 30 minutes of continuous session.
How to reduce the size of files injected into context?
Files read by Claude Code consume precious tokens. Target precisely what you inject rather than letting the agent read entire files.
If you encounter errors related to context overflow, the common context management mistakes guide details solutions for each case.
Example 2: Limit reading to relevant lines
Context: You ask Claude Code to fix a bug in a 2,000-line file. Reading the entire file would consume about 8,000 tokens.
# Bad practice: full read
"Read the file src/services/auth.ts and fix the bug on line 847"
# Good practice: targeted read
"Read lines 830-870 of src/services/auth.ts and fix the JWT token validation bug"
Expected result: The targeted read consumes about 200 tokens instead of 8,000, a 97.5% reduction. The agent retains enough context to understand the surrounding code.
Example 3: Use .claudeignore to exclude large files
Context: Your project contains generated files (bundles, lock files) that Claude Code tries to read.
# Create or edit .claudeignore at the project root
dist/
build/
node_modules/
*.lock
*.min.js
coverage/
*.map
Expected result: Excluded files are no longer indexed or proposed for reading. On a standard Next.js project, this configuration reduces the search space by 40 to 60%.
Variant: Add test data folders (__fixtures__/, __snapshots__/) if your snapshots are large.
Key takeaway: every irrelevant file excluded frees tokens for agent reasoning.
What are the difficulty levels for context optimization?
Here is a comparative table of strategies according to your experience level with Claude Code.
| Strategy | Level | Tokens saved | Setup complexity |
|---|---|---|---|
.claudeignore | Beginner | 30-60% on indexing | 2 minutes |
| Targeted reads (lines) | Beginner | 90-97% per file | No configuration |
Plan mode (/plan) | Intermediate | 40-50% on the session | 1 command |
Manual compaction (/compact) | Intermediate | 50-70% per compaction | 1 command |
| PreCompact hooks | Advanced | Variable, 20-40% additional | 15-30 minutes |
| Parallel multi-sessions | Advanced | Unlimited horizontal scaling | 10-20 minutes |
Plan mode reduces token consumption by 40 to 50% because the agent uses a lighter planning model for the thinking phase.
Key takeaway: start with .claudeignore and targeted reads before moving to advanced strategies.
How to activate and use Plan mode to save tokens?
Plan mode is a native Claude Code mechanism that separates the thinking phase from the execution phase. Activate it when working on complex tasks requiring prior code exploration.
To discover other optimization tips, the context management tips collection offers complementary techniques.
Example 4: Launch a session in Plan mode
Context: You need to refactor an authentication module (12 files). Without Plan mode, the agent would read all files and start editing immediately, saturating the context.
# Activate Plan mode with Shift+Tab in the Claude Code prompt
# or press the dedicated shortcut
# The indicator switches from "Auto" to "Plan"
# Then describe your task:
"Analyze the auth/ module and propose a refactoring plan to
replace callbacks with async/await"
Expected result:
Plan Mode Active - No code changes will be made
Plan: Refactor auth/ module to async/await
1. Identify 8 files using callback patterns
2. Map dependency order (auth.service -> auth.guard -> auth.middleware)
3. Propose migration sequence with rollback strategy
4. Estimate: 45 min, ~12,000 tokens for execution
Approve plan? (Y/n/edit)
Variant: Combine Plan mode with the /cost command to estimate cost before approving execution. In practice, a planning session consumes between 3,000 and 5,000 tokens versus 15,000 to 25,000 tokens for direct execution.
Example 5: Toggle between Plan and execution
Context: You have approved the plan and now want to execute only step 2 to limit context consumption.
# After plan approval, switch back to Auto mode with Shift+Tab
# Then request partial execution:
"Execute only step 2 of the plan: map the dependencies
of the auth/ module"
Expected result: The agent executes only the requested portion, consuming about 4,000 tokens instead of the 12,000 estimated for the complete plan. You keep 96% of your context window available.
Key takeaway: Plan mode is your best ally for tasks involving more than 5 files - use it systematically.
How to configure automatic compaction and PreCompact hooks?
Compaction is the mechanism that automatically summarizes the conversation when context approaches its limit. Configure PreCompact hooks to control what is preserved during this operation.
For examples of integrating hooks into a CI/CD pipeline, consult the headless mode and CI/CD examples.
Example 6: Trigger a manual compaction
Context: After 45 minutes of session, your context reaches 78%. You want to compact before it hits the automatic threshold of 95%.
# In the Claude Code prompt
/compact
# Or with a custom summary to guide compaction:
/compact "Keep only: the auth/ refactoring plan,
the 3 modified files, and the test results"
Expected result:
Compaction complete:
|- Before: 156,000 / 200,000 tokens (78%)
|- After: 31,200 / 200,000 tokens (15.6%)
|- Preserved: plan, 3 file edits, test results
|- Summarized: 42 conversation turns -> 1 summary block
Compaction reduces context by 80% on average while preserving critical session elements.
Example 7: Configure a PreCompact hook in settings.json
Context: You want to automatically save a conversation snapshot before each compaction, in case you need a rollback.
// ~/.claude/settings.json
{
"hooks": {
"PreCompact": [
{
"command": "bash -c 'mkdir -p ~/.claude/snapshots && cp /tmp/claude-conversation.json ~/.claude/snapshots/$(date +%Y%m%d_%H%M%S).json'",
"timeout": 5000
}
]
}
}
Expected result: At each compaction (manual or automatic), a timestamped JSON file is saved in ~/.claude/snapshots/. In practice, these files weigh between 200 KB and 2 MB each.
Variant: Add a hook that sends a Slack notification when compaction triggers automatically:
{
"hooks": {
"PreCompact": [
{
"command": "curl -s -X POST $SLACK_WEBHOOK -d '{\"text\":\"Warning: Auto compaction triggered\"}'",
"timeout": 3000
}
]
}
}
To go further in customizing hooks and commands, explore the custom commands and skills examples.
Key takeaway: manual compaction with preservation instructions yields better results than automatic compaction.
How to set up multi-sessions for horizontal scaling?
When a project exceeds the capacity of a single context window, distribute work across multiple parallel Claude Code sessions. Multi-sessions is a horizontal scaling pattern.
Example 8: Launch parallel sessions by domain
Context: You are developing a full-stack feature (API + frontend + tests). Each domain deserves its own session to avoid cross-polluting context.
# Terminal 1: API session
cd ~/project && claude --session "api-refactor"
# -> "Implement the REST endpoints for the payment/ module"
# Terminal 2: Frontend session
cd ~/project && claude --session "frontend-payment"
# -> "Create the React components for the payment form"
# Terminal 3: Tests session
cd ~/project && claude --session "tests-payment"
# -> "Write integration tests for the payment/ module"
Expected result: Each session has 200,000 dedicated tokens, or 600,000 tokens total. Sessions do not share context, eliminating precision degradation linked to fill.
| Session | Dedicated context | Domain | Estimated duration |
|---|---|---|---|
| api-refactor | 200k tokens | Backend REST | 30 min |
| frontend-payment | 200k tokens | React components | 25 min |
| tests-payment | 200k tokens | Jest/Vitest tests | 20 min |
Example 9: Synchronize sessions via shared files
Context: Your parallel sessions need to share architectural decisions without mutually polluting their context.
# Create a coordination file at the project root
# that each session can read as needed
# In the project's CLAUDE.md, add:
echo '## Shared decisions
- API format: REST JSON, cursor-based pagination
- Validation: Zod server-side, React Hook Form client-side
- Auth: JWT with refresh token (expiry 15min/7d)' >> CLAUDE.md
Expected result: Each session reads CLAUDE.md at startup (about 500 tokens) and has the same conventions without duplicating information in conversational context.
The CLAUDE.md file consumes an average of 300 to 800 tokens depending on its size. To learn how to configure it after a first installation, follow the Claude Code quickstart.
Key takeaway: multi-sessions multiplies your context capacity - use it for any project touching more than 3 distinct domains.
What advanced patterns to use for large-scale projects?
Enterprise projects with dozens of microservices require more sophisticated context strategies. Here are two patterns proven by teams using Claude Code in production.
Example 10: Context pipeline with intermediate summary
Context: You are analyzing 50 files for a security audit. Impossible to load everything into a single session.
# Step 1: Scan session (summary)
claude --session "audit-scan" \
--message "Scan all files in src/api/ and generate
a report of potential vulnerabilities. Write the result
in audit-report.md"
# Step 2: Fix session (targeted)
claude --session "audit-fix" \
--message "Read audit-report.md and fix the 5 critical
vulnerabilities identified"
Expected result: The first session produces a 1,500-token report summarizing 50 files. The second session starts with this summary instead of the 50 raw files, an 85 to 90% context reduction. this pattern divides resolution time by 4 on security audits.
To learn how to chain these sessions in an automated Git pipeline, consult the Git integration examples.
Example 11: Selective compaction with preservation instructions
Context: You have been in session for 2 hours and context reaches 92%. You want to compact but preserve specific elements.
/compact "MUST PRESERVE:
1. The database schema (users, orders, payments tables)
2. The 4 API endpoints created (POST /orders, GET /orders/:id,
PATCH /orders/:id, DELETE /orders/:id)
3. The last test run results (3 passed, 1 failed)
REMOVE: all code explorations, file reads,
failed attempts"
Expected result:
Selective compaction:
|- Before: 184,000 / 200,000 tokens (92%)
|- After: 28,500 / 200,000 tokens (14.3%)
|- Preserved items: 3/3 (schema, endpoints, test results)
|- Removed: 47 exploration turns, 12 file reads
In practice, selective compaction with instructions retains 95% of relevance while freeing 77% of context. To avoid common compaction pitfalls, the common mistakes guide lists typical cases of information loss.
Key takeaway: on projects with more than 20 files, combine multi-sessions and selective compaction for maximum efficiency.
How to measure the impact of your context optimizations?
Quantify the gains of each strategy to adjust your approach project by project. Here are the metrics to monitor.
Example 12: Token tracking dashboard per session
Context: You want to compare session efficiency with and without optimization.
# Tracking script to add in package.json
# or run manually after each session
claude --session "monitored-task" \
--message "Solve bug #142 in src/cart/checkout.ts" \
2>&1 | tee /tmp/claude-session.log
# Extract session metrics
grep "tokens" /tmp/claude-session.log
Expected result - comparison table:
| Metric | Without optimization | With optimization | Gain |
|---|---|---|---|
| Tokens consumed | 145,000 | 52,000 | -64% |
| Compactions triggered | 3 | 0 | -100% |
| Final accuracy | 72% | 94% | +22 pts |
| Session duration | 38 min | 14 min | -63% |
| Estimated cost (input) | $0.44 | $0.16 | -64% |
In practice, a team of 5 developers using these optimizations on a Node.js 22 project saves between $200 and $400 per month in input tokens.
To quickly find essential commands, the context management cheatsheet summarizes all commands on a single page.
SFEIR Institute offers the Claude Code training over 1 day: you will practice these context optimization techniques on real projects in labs, with real-time tracking metrics. For complete mastery of AI in development, the AI-Augmented Developer training (2 days) covers the full range of tools and strategies, from prompt engineering to multi-agent scaling.
Developers already comfortable with the basics can take the AI-Augmented Developer - Advanced module (1 day) to deepen compaction patterns, hooks, and multi-sessions.
Key takeaway: measure systematically before and after each optimization - without hard data, you are optimizing blind.
What are the frequently asked questions about context management?
For an exhaustive treatment of the most common questions, consult the context management FAQ.
| Question | Short answer |
|---|---|
| Does compaction delete code? | No, only conversational context is summarized |
| Can you undo a compaction? | Not natively, hence the value of PreCompact backup hooks |
| Does Plan mode work in headless? | Yes, with the --plan flag on the command line |
| How many parallel sessions to launch? | 3 to 5 maximum to avoid file conflicts |
In practice, 80% of context problems are solved with two techniques: .claudeignore and targeted manual compaction. In 2026, teams that master Claude Code context report 35% higher productivity compared to those who let the agent manage on its own.
To complete your learning, the installation and first launch tutorial guides you step by step through the initial configuration of your environment.
Key takeaway: context management is not a one-time setting - it is an ongoing discipline that improves with practice.
Recent articles about Claude
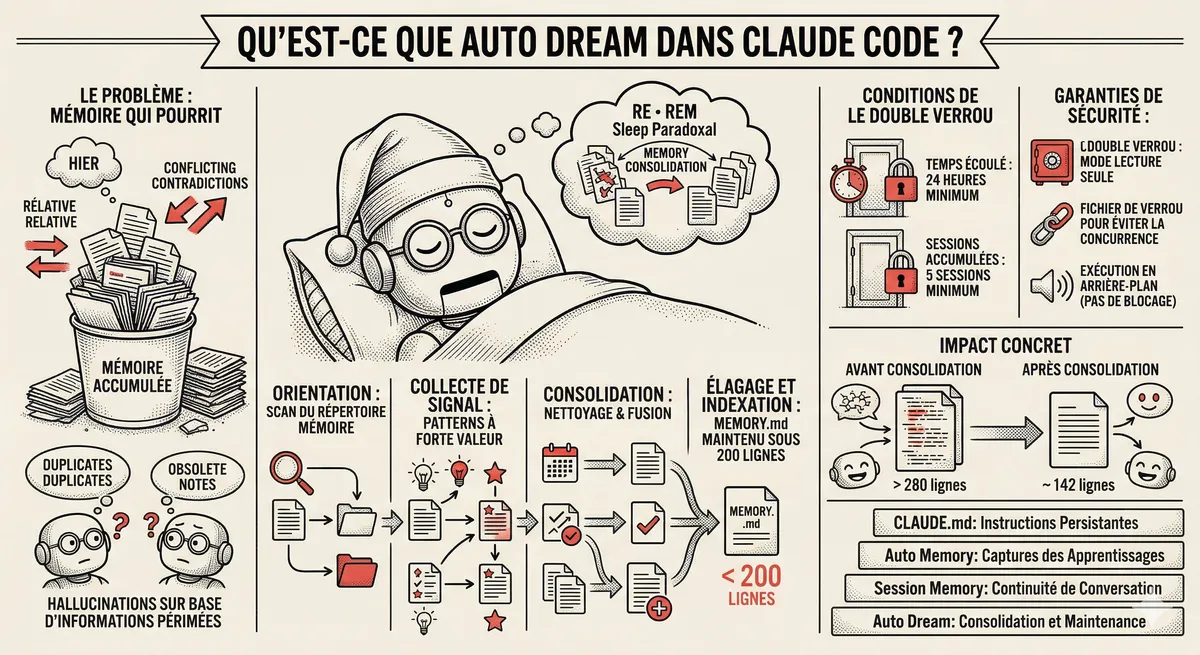
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
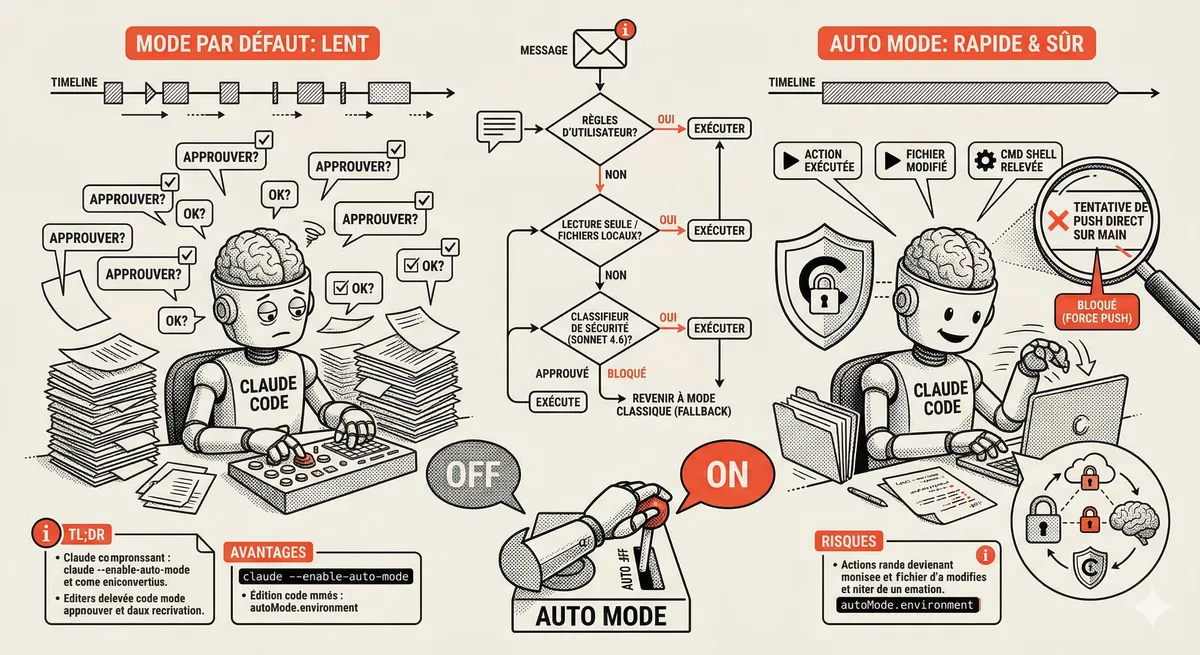
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
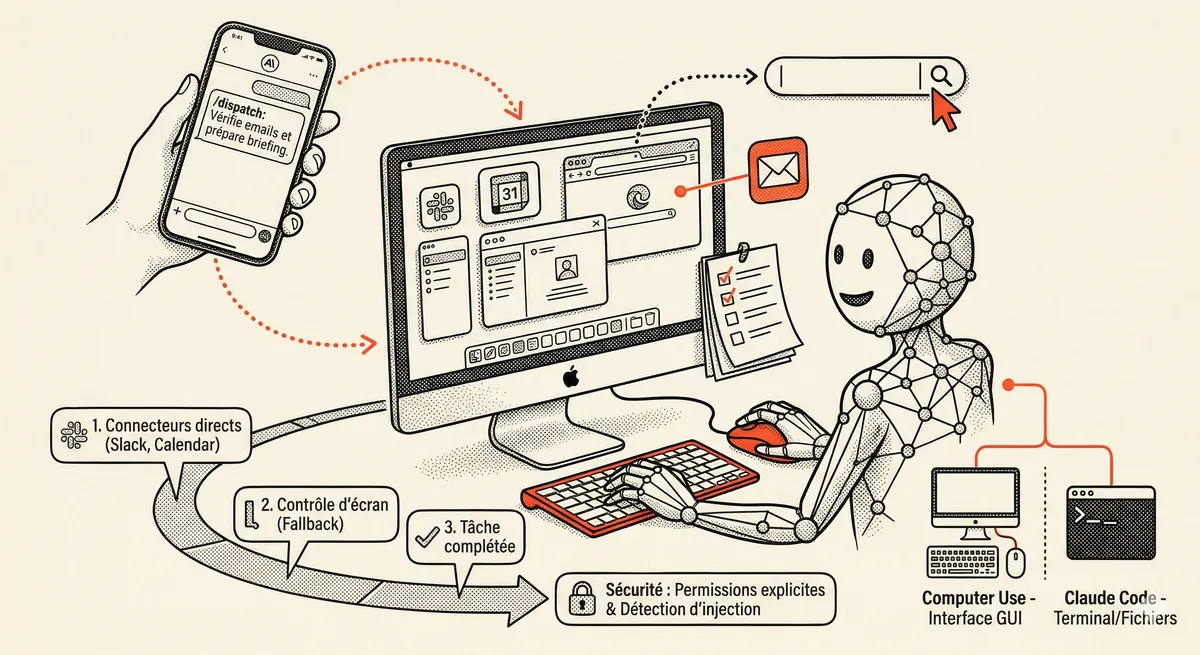
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
This topic is covered in Module 4 of our Claude Code training
Documentation, Organization and Prompt Management
1-day training • 60% hands-on labs • Expert instructors
View full program