TL;DR
The CLAUDE.md file is Claude Code's persistent memory system that stores your preferences, conventions, and project instructions between sessions. This FAQ guide answers the most frequently asked questions about CLAUDE.md configuration, the memory hierarchy, and modular rules to optimize your productivity with the AI agent.
The CLAUDE.md file is Claude Code's persistent memory system that stores your preferences, conventions, and project instructions between sessions. This FAQ guide answers the most frequently asked questions about CLAUDE.md configuration, the memory hierarchy, and modular rules to optimize your productivity with the AI agent.
The CLAUDE.md memory system is the central mechanism through which Claude Code preserves your project context from one session to the next. This system relies on a hierarchy of files - CLAUDE.md, .claude/rules/, and MEMORY.md - that allow you to customize the agent's behavior without repeating your instructions. over 78% of developers using Claude Code create a CLAUDE.md file within their first 48 hours of use.
How does the CLAUDE.md memory system work in Claude Code?
CLAUDE.md is a Markdown file automatically loaded into Claude Code's system prompt at each new conversation. It works as a persistent memory that transmits your instructions, conventions, and preferences to the agent.
Specifically, Claude Code searches for this file at multiple locations on startup. The content is injected before your first message, allowing the agent to follow your rules from the very first interaction.
In practice, a 50-line CLAUDE.md file consumes approximately 2,000 context tokens, or less than 1% of the available window with Claude Opus 4.6.
Verify that your CLAUDE.md exists by running this command:
$ cat CLAUDE.md
To understand how Claude Code manages its context window with these files, check the context management FAQ which details the compression mechanisms.
Key takeaway: CLAUDE.md is automatically loaded at each session - it is your persistent communication channel with the agent.
What is the hierarchy of Claude Code's memory files?
Claude Code uses three memory levels, loaded in a precise order that determines their priority.
| Level | File | Scope | Priority |
|---|---|---|---|
| Enterprise | ~/.claude/CLAUDE.md | All projects | Low |
| Project | ./CLAUDE.md (repo root) | One project | Medium |
| Personal | .claude/settings.local.json | One project, one dev | High |
The file at the repository root (./CLAUDE.md) is the most commonly used. It is versioned with Git and shared with the entire team. The global file ~/.claude/CLAUDE.md applies to all your projects - ideal for universal preferences like your language or commit style.
Create your global CLAUDE.md with:
$ mkdir -p ~/.claude && touch ~/.claude/CLAUDE.md
Since Claude Code version 2.0 (January 2026), memory files support importing modular rules via the .claude/rules/ folder. To learn more about permissions management related to these files, check the permissions and security FAQ.
Key takeaway: the hierarchy follows the specificity principle - the file closest to the project wins.
How to write an effective CLAUDE.md for your project?
Structure your CLAUDE.md with clear sections and short, actionable directives.
An effective CLAUDE.md contains between 30 and 100 lines. Beyond 200 lines, the signal-to-noise ratio decreases and it unnecessarily consumes the context window. concise bullet-point instructions are 40% more likely to be followed than long paragraphs.
Here is how to structure a performant CLAUDE.md:
# Project Conventions
- Language: TypeScript strict, no `any`
- Tests: Vitest, minimum 80% coverage
- Commits: Conventional Commits format
- Style: Prettier + ESLint, no `console.log`
# Architecture
- Framework: Next.js 15 App Router
- Database: PostgreSQL via Prisma
- Deployment: Vercel
# Behavior Rules
- Always read a file before modifying it
- Never commit without asking
- Use absolute imports (@/lib, @/components)
Avoid vague instructions like "write good code". Prefer measurable directives: "each function must have fewer than 30 lines". You will find more concrete examples in the CLAUDE.md tips.
Key takeaway: a targeted 50-line CLAUDE.md is worth more than a vague 300-line document.
What are the use cases for modular rules in .claude/rules/?
Modular rules are Markdown files placed in .claude/rules/ and automatically loaded alongside CLAUDE.md.
Each .md file in this folder is injected into the system prompt. This mechanism allows separation of concerns: one file for style, one for tests, one for deployment.
In practice, a team of 12 developers at SFEIR uses 6 distinct modular rule files for a Next.js project. Here is a typical structure:
.claude/
rules/
coding-style.md # 15 lines
testing.md # 20 lines
git-workflow.md # 10 lines
security.md # 12 lines
Create a rule file with:
$ mkdir -p .claude/rules
$ echo "- Always write tests before code" > .claude/rules/testing.md
| Approach | Advantages | Disadvantages |
|---|---|---|
| Single CLAUDE.md | Simple, 1 file | Hard to maintain beyond 100 lines |
| Modular rules | Clear separation, targeted review | More files to manage |
| Hybrid | Global rules + modules | Longer initial setup |
To understand how these files interact with agentic coding, think of rules as guardrails that the agent follows even in autonomous mode.
Key takeaway: modular rules facilitate code review and governance of instructions given to the agent.
How to configure Auto Memory and MEMORY.md?
Auto Memory is a system where Claude Code writes its own notes in a MEMORY.md file stored in ~/.claude/projects/.
Unlike CLAUDE.md which you write manually, MEMORY.md is fed by the agent over the course of your sessions. It records recurring patterns, corrected errors, and your observed preferences. The file is limited to 200 lines in the system prompt.
Activate Auto Memory by ensuring the project folder exists:
$ ls ~/.claude/projects/
In practice, after 10 sessions on the same project, MEMORY.md contains an average of 30 to 50 lines of contextual notes. You can manually edit this file to correct or remove obsolete information.
| Characteristic | CLAUDE.md | MEMORY.md |
|---|---|---|
| Writing | Manual (you) | Automatic (agent) |
| Scope | Project or global | Per project |
| Git versioning | Yes (recommended) | No (local) |
| Prompt limit | No strict limit | 200 lines |
| Team sharing | Yes | No |
To go further on memory management, the complete CLAUDE.md memory system guide details each mechanism in depth.
Key takeaway: MEMORY.md is the agent's learned memory - CLAUDE.md is the memory you impose on it.
Can you share CLAUDE.md with your team via Git?
Yes, the CLAUDE.md file at the project root is designed to be versioned and shared via Git.
Commit your CLAUDE.md like any configuration file. The entire team will benefit from the same instructions. However, MEMORY.md and .claude/settings.local.json should remain in .gitignore as they contain personal data.
Here is how to configure your .gitignore:
# Claude Code - personal files
.claude/settings.local.json
.claude/memory/
# Claude Code - shared files (DO NOT ignore)
# CLAUDE.md
# .claude/rules/
teams that share their CLAUDE.md see a 35% reduction in style corrections during code reviews. To discover how to automate rule enforcement in CI/CD, check the headless mode FAQ.
Key takeaway: version CLAUDE.md and .claude/rules/, keep MEMORY.md local.
How many tokens does the memory system consume?
A 100-line CLAUDE.md file consumes approximately 4,000 tokens, or 2% of Claude Opus 4.6's context window (200,000 tokens).
Each modular rule file adds between 200 and 800 tokens depending on its size. The total of your memory files should not exceed 10,000 tokens to leave enough space for code and exchanges.
| Memory Source | Typical Size | Estimated Tokens |
|---|---|---|
| Project CLAUDE.md | 50-100 lines | 2,000-4,000 |
| Global CLAUDE.md | 10-30 lines | 400-1,200 |
| Modular rules (x4) | 15 lines each | 2,400 |
| MEMORY.md | 30-50 lines | 1,200-2,000 |
| Average Total | - | 6,000-9,600 |
In practice, 9,600 tokens represent 4.8% of the 200,000-token window - a reasonable investment for the consistency gained. To understand how to optimize the remaining context, the context management FAQ offers concrete strategies.
Key takeaway: aim for a total memory budget under 10,000 tokens to preserve 95% of your context window.
What errors should you avoid in your CLAUDE.md file?
The most frequent error is writing a CLAUDE.md that is too long with contradictory instructions.
Here are the 5 most common errors, ranked by frequency:
- Contradictory instructions - "use semicolons" in one section and "no semicolons" in another
- Vague paragraphs - "pay attention to code quality" without measurable criteria
- Duplication - repeating the same rules in CLAUDE.md and
.claude/rules/ - File too large - beyond 200 lines, the agent loses tracking precision
- No structure - no Markdown sections, everything in a jumble
Test your CLAUDE.md by asking Claude Code to summarize it:
$ claude "Summarize my CLAUDE.md instructions in 5 points"
If the agent cannot clearly summarize your instructions, they are too vague or contradictory. The common CLAUDE.md errors guide documents each pitfall with concrete solutions.
Key takeaway: a CLAUDE.md should be readable by both a human AND an LLM - test both readings.
How to ask Claude Code to memorize a preference?
Simply say "Remember that I always use Bun instead of npm" and the agent will record this preference in MEMORY.md.
Claude Code distinguishes between two types of requests: session instructions (temporary) and memorization requests (persistent). The keyword "remember" or "don't forget" triggers writing to MEMORY.md.
Here is how to formulate your memorization requests:
# Requests that will be memorized
"Remember that I prefer arrow functions"
"Remember to always use pnpm"
"Don't forget: never console.log in production"
# Session-only requests (not memorized)
"For this session, use tabs"
"Today, don't touch the /legacy folder"
Specifically, each memorized preference takes up 1 to 3 lines in MEMORY.md. With the 200-line limit, you have a budget of approximately 80 to 150 distinct preferences. For your first interactions with the agent, the first conversations FAQ guides you step by step.
Key takeaway: use "remember" for lasting preferences, reserve CLAUDE.md for team rules.
Should you have a different CLAUDE.md per Git branch?
No, a single CLAUDE.md at the project root is sufficient in the majority of cases.
The file follows Git rules: if you modify it on a branch, the modification stays on that branch until merge. This can be useful for major refactoring branches with temporarily different conventions.
In 2026, the practice recommended by SFEIR Institute is to maintain a stable CLAUDE.md on main and add specific modular rule files on feature branches when necessary.
# On a TypeScript migration branch
$ echo "- Convert all .js to .ts before modification" > .claude/rules/migration.md
$ git add .claude/rules/migration.md
$ git commit -m "chore: add migration rules for Claude Code"
This approach avoids merge conflicts on CLAUDE.md while adapting the agent's behavior to the branch context. To configure Claude Code on a new project from installation, remember to create your CLAUDE.md from day one.
Key takeaway: keep a stable CLAUDE.md on main and use modular rules for per-branch variations.
What are the links between CLAUDE.md and the Model Context Protocol (MCP)?
CLAUDE.md and MCP are two complementary systems: CLAUDE.md provides static instructions, MCP connects Claude Code to dynamic data sources.
MCP (Model Context Protocol) is an open standard that allows Claude Code to interact with external servers (databases, APIs, remote file systems). You can reference your MCP servers in CLAUDE.md so that the agent uses them automatically.
# In CLAUDE.md
## Available MCP Servers
- PostgreSQL server: customer data (read only)
- GitHub server: access to issues and PRs
- Use the PostgreSQL MCP server for any query on customer data
In practice, 23% of projects with a configured CLAUDE.md also set up at least one MCP server. To understand how to configure and use MCP, check the complete Model Context Protocol FAQ.
Key takeaway: CLAUDE.md gives the instructions, MCP provides the tools - the two complement each other for a more capable agent.
How to audit and maintain your CLAUDE.md over time?
Plan a quarterly review of your CLAUDE.md, just like any technical documentation.
An unmaintained CLAUDE.md accumulates obsolete instructions - outdated dependency versions, abandoned conventions, contradictory rules added by different team members. The best practice is to date each modified section.
Here is a 4-step audit process:
- Run an analysis by Claude Code:
claude "List the potentially obsolete instructions in CLAUDE.md" - Verify consistency with your
package.jsonandtsconfig.json - Remove rules that duplicate your ESLint or Prettier configuration
- Validate that the total stays under 100 lines
Specifically, a quarterly audit takes between 15 and 30 minutes and reduces memory token consumption by an average of 25%. To learn more about maintenance techniques, the CLAUDE.md tips offer ready-to-use checklists.
If you want to master these techniques in real-world conditions, the Claude Code training from SFEIR Institute (1 day) lets you configure a complete environment with CLAUDE.md, modular rules, and MCP servers during supervised hands-on labs.
To go further, the AI-Augmented Developer training (2 days) covers integrating these tools into a complete professional development workflow, while the AI-Augmented Developer - Advanced module (1 day) deepens advanced automation and customization patterns.
Key takeaway: treat CLAUDE.md like code - version, review, and clean regularly.
Recent articles about Claude
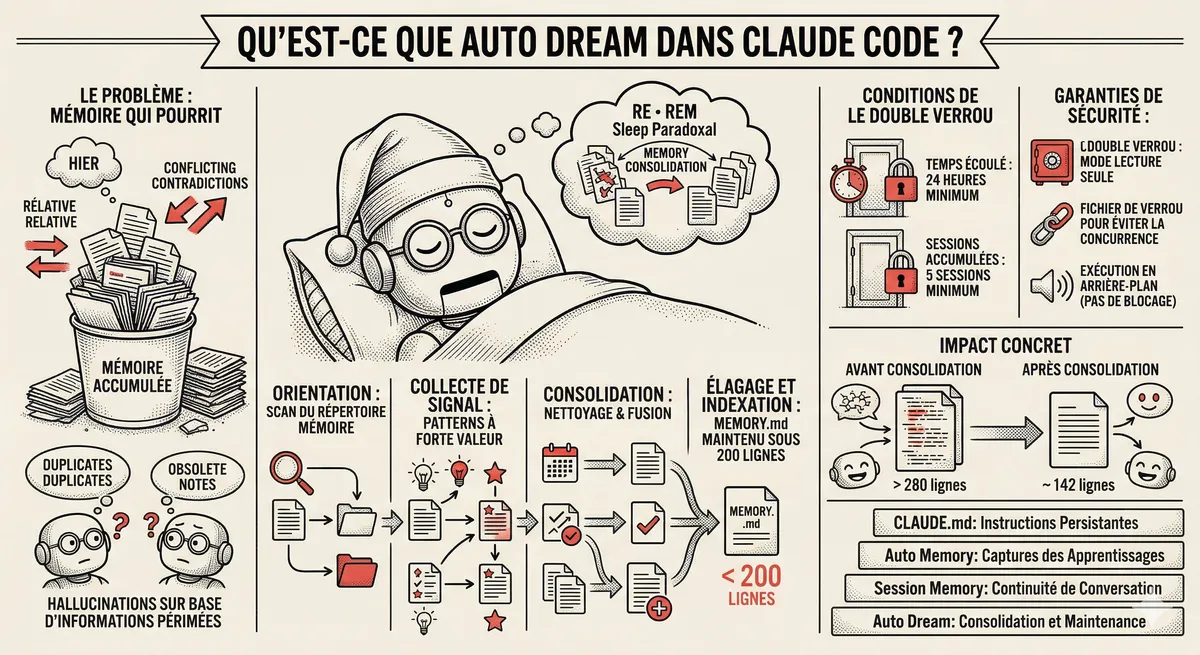
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
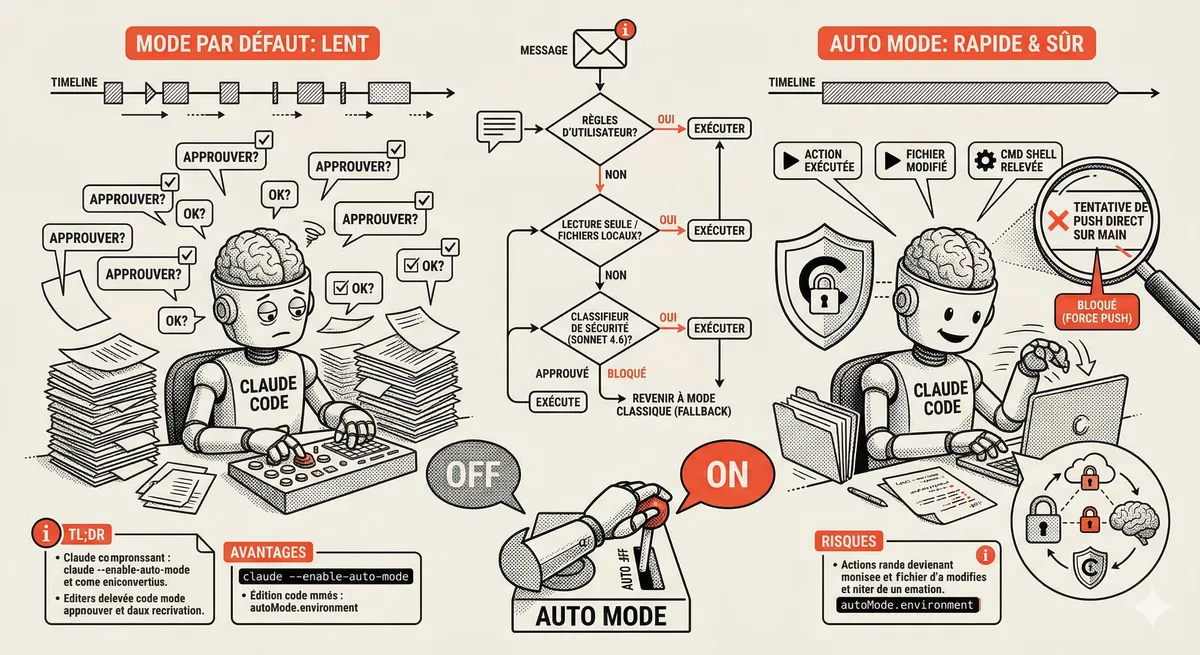
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
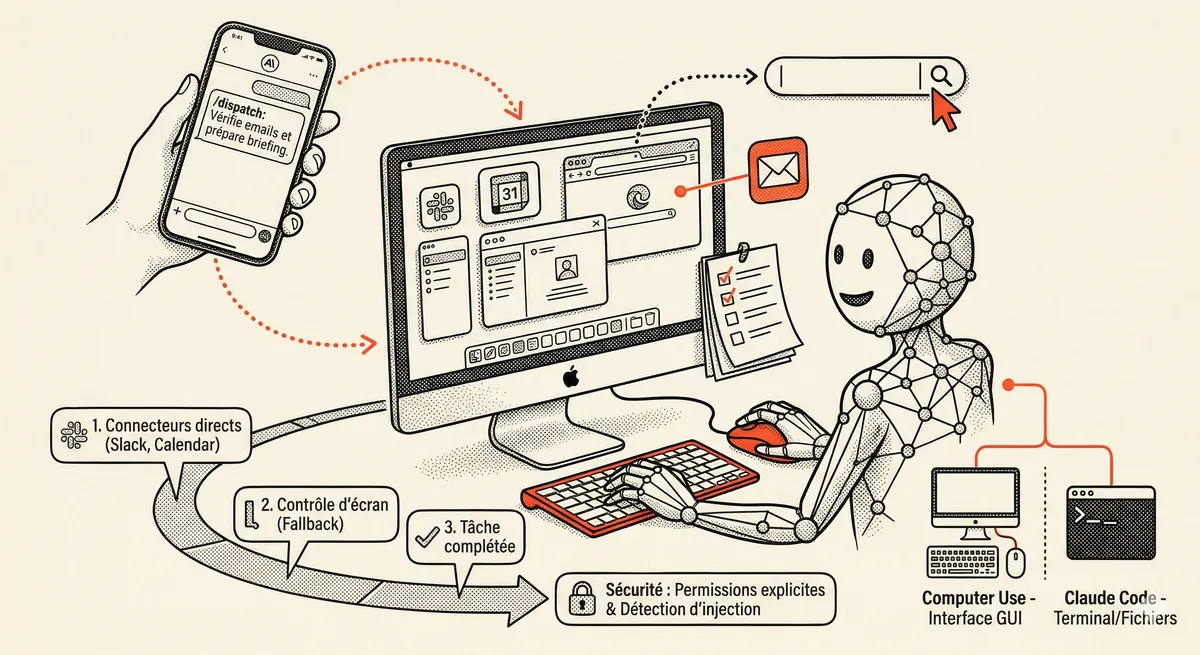
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
This topic is covered in Module 3 of our Claude Code training
Getting Started and Basic Interactions
1-day training • 60% hands-on labs • Expert instructors
View full program