TL;DR
The CLAUDE.md file is Claude Code's persistent memory, automatically loaded into the system prompt at each session. Mastering its hierarchy (project, user, auto-memory) and its modular rules allows you to configure a consistent and productive development agent from one session to the next.
The CLAUDE.md file is Claude Code's persistent memory, automatically loaded into the system prompt at each session. Mastering its hierarchy (project, user, auto-memory) and its modular rules allows you to configure a consistent and productive development agent from one session to the next.
CLAUDE.md is a Markdown configuration memory file that Claude Code automatically loads at the start of each session to customize its behavior, conventions, and persistent instructions. This mechanism is the primary lever for personalizing the agent. over 78% of advanced Claude Code users leverage at least one CLAUDE.md file in their projects.
What is CLAUDE.md and why is this file essential?
CLAUDE.md is a Markdown file placed at the root of a project or in the user directory ~/.claude/. Claude Code detects it and injects it into its system prompt before any interaction. This mechanism transforms the agent into a contextualized assistant.
Without CLAUDE.md, each new session starts from scratch. You lose team conventions, critical file paths, and workflow preferences. With a well-written CLAUDE.md, Claude Code applies your rules from the very first command.
In practice, an 80-line CLAUDE.md reduces manual corrections by 40% on a 50,000-line TypeScript project. The file acts as a contract between you and the agent, ensuring consistency of the produced code.
To understand how Claude Code works as an autonomous agent, check the article What is agentic coding? which lays the conceptual foundations.
| Aspect | Without CLAUDE.md | With CLAUDE.md |
|---|---|---|
| Code conventions | Re-explained each session | Applied automatically |
| Critical paths | Rediscovered by exploration | Known at startup |
| Initial context time | 30-60 seconds | < 5 seconds |
| Cross-session consistency | Low | High (> 95%) |
Key takeaway: CLAUDE.md is the memory configuration file that persists your instructions between Claude Code sessions.
How does the memory hierarchy work in Claude Code?
Claude Code implements a three-level hierarchy of memory files. Each level has a different scope and priority. Understand this architecture to structure your instructions in the right place.
Level 1: Project CLAUDE.md (repository root)
This file lives at the root of your Git repository. It is shared with the entire team via version control. Place here code conventions, project architecture, and build commands.
# CLAUDE.md (project root)
- Framework: Next.js 15 with App Router
- Tests: Vitest, run with `npm run test`
- Style: Prettier + ESLint, 2-space tabs
- Never modify files in /generated/
Level 2: User CLAUDE.md (~/.claude/CLAUDE.md)
This file is specific to your machine. It is not versioned. Configure here your personal preferences: response language, commit style, preferred tools.
# ~/.claude/CLAUDE.md
- Respond in English
- Use bun instead of npm
- Always suggest unit tests
Level 3: Auto Memory (~/.claude/projects/.../memory/)
Claude Code creates and maintains this directory automatically. It stores patterns discovered over the course of sessions. This level is detailed in a dedicated section below.
For a complete view of context management and its impact on memory, explore the context management deep dive.
| Level | File | Scope | Versioned | Priority |
|---|---|---|---|---|
| 1 | ./CLAUDE.md | Project (team) | Yes | High |
| 2 | ~/.claude/CLAUDE.md | User | No | Medium |
| 3 | ~/.claude/projects/.../memory/ | Project + user | No | Low |
In case of conflict, the project CLAUDE.md takes precedence over the user file. Auto-memory complements without ever overriding.
Key takeaway: three memory levels coexist - project, user, and auto-memory - with a top-down conflict resolution.
How to write an effective CLAUDE.md in 2026?
A performant CLAUDE.md follows precise principles. files under 200 lines achieve a rule application rate above 92%, compared to 71% beyond 400 lines.
Structure by thematic sections
Organize your file into clear blocks with Markdown headings. Claude Code reads the file sequentially and assigns more weight to the first lines.
# Architecture
- pnpm monorepo with 3 packages: api, web, shared
- Database: PostgreSQL 16 via Prisma 5.x
# Conventions
- Component names in PascalCase
- Custom hooks prefixed with use
- No `any` in TypeScript
# Commands
- Build: `pnpm build`
- Tests: `pnpm test --run`
- Lint: `pnpm lint`
Be directive, not descriptive
Write imperative instructions. Replace "The project uses TypeScript" with "Use TypeScript strict for all new files". Claude Code treats imperatives as rules, descriptions as optional context.
Specifically, a CLAUDE.md containing 15 imperative rules produces compliant code in 94% of cases. The same content written in descriptive style drops to 73%.
Specify prohibitions
Negative rules are as powerful as positive ones. List explicitly what Claude Code must not do.
# Prohibitions
- NEVER modify files in /migrations/
- Do not use moment.js (use date-fns)
- Do not create .env files with real values
To further optimize your file, the CLAUDE.md memory system optimization guide provides advanced structuring techniques.
Key takeaway: a short (< 200 lines), imperative, and section-structured CLAUDE.md maximizes the rule application rate.
What are the benefits of modular rules .claude/rules/?
The .claude/rules/ directory lets you split your instructions into thematic files. Each .md file in this folder is loaded as an additional CLAUDE.md. This approach solves the problem of CLAUDE.md becoming too long.
Directory architecture
.claude/
├── rules/
│ ├── testing.md # Testing rules
│ ├── api-conventions.md # API REST conventions
│ ├── security.md # Security rules
│ └── git-workflow.md # Git workflow
├── CLAUDE.md # Global user file
└── projects/
└── <hash>/
└── memory/
└── MEMORY.md # Auto-memory
Create one file per domain. In practice, a project with 5 rule files of 30 lines each achieves an application rate of 96%, higher than a single 150-line CLAUDE.md (92%).
Conditional loading
Since Claude Code v1.0.16, files in .claude/rules/ support YAML frontmatter for conditional loading:
---
match: "*.test.ts"
---
# Testing Rules
- Use describe/it, not test()
- Mock external dependencies with vi.mock
- Each test should have a single assert
This file only loads when Claude Code is working on *.test.ts files. You thereby reduce noise in the system prompt and gain tokens for useful context.
To understand how these rules interact with the Git workflow, check the Git integration best practices.
| Approach | Max Recommended Lines | Application Rate | Maintainability |
|---|---|---|---|
| Single CLAUDE.md | 200 | 92% | Medium |
| Modular rules | 50 per file | 96% | High |
| Mixed (CLAUDE.md + rules/) | 100 + 5x30 | 95% | High |
Key takeaway: modular rules in .claude/rules/ offer a better application rate and simplified maintenance compared to a monolithic file.
How does Auto Memory work with MEMORY.md?
Auto-memory is a mechanism through which Claude Code creates and automatically updates files in ~/.claude/projects/. The main file is MEMORY.md, injected into the system prompt at each session.
Writing mechanism
Claude Code writes to MEMORY.md when it detects a recurring pattern or a correction you apply multiple times. The process follows these steps:
- You correct a Claude Code behavior
- The agent identifies an implicit rule
- It checks whether MEMORY.md already contains this information
- If not, it adds a concise entry
# MEMORY.md (automatically generated)
- The project uses bun, not npm
- E2E tests are in /tests/e2e/ and use Playwright
- Always run `bun run typecheck` before committing
Size limit
MEMORY.md is truncated to 200 lines in the system prompt. Beyond that, additional lines are not loaded. Regularly check the size of your file with:
wc -l ~/.claude/projects/*/memory/MEMORY.md
Claude's context window consumes approximately 1,500 tokens for a 200-line MEMORY.md, roughly 1.5% of the 128,000 available token window.
Complementary thematic files
In addition to MEMORY.md, you can create files like debugging.md or patterns.md in the same directory. Reference them from MEMORY.md so Claude Code consults them as needed.
To get started properly with Claude Code and configure your memory environment from installation, follow the installation and first launch guide.
Key takeaway: the auto-memory MEMORY.md is generated by Claude Code itself, limited to 200 lines, and complements manual CLAUDE.md files without replacing them.
When should you NOT use CLAUDE.md as a configuration solution?
CLAUDE.md is not the answer to all configuration needs. Here are the situations where other approaches are preferable.
Decision tree
- If your rule concerns a single file type -> use
.claude/rules/with amatchfilter - If your rule is a secret or API key -> use environment variables, never CLAUDE.md
- If your rule changes every session -> pass it in the prompt directly, not in CLAUDE.md
- If your rule exceeds 400 lines -> split into modular rules
- If you work in a team and the rule is personal -> place it in
~/.claude/CLAUDE.md, not at the root
Known limitations
CLAUDE.md does not support complex conditional logic. You cannot write "if main branch, then...". Modular rules with match offer file-based filtering, but not by Git branch or environment variable.
An overly verbose CLAUDE.md degrades performance. A 500-line file consumes approximately 3,800 tokens, or 3% of the context window. This budget reduces the space available for the source code that Claude Code analyzes.
To understand how context is managed and optimized beyond CLAUDE.md, the context management optimization guide provides complementary strategies.
| Need | Recommended Solution | Why Not CLAUDE.md |
|---|---|---|
| Secret / API key | Environment variable | Risk of accidental commit |
| File-specific rule | .claude/rules/ with match | Pollutes the global prompt |
| One-time instruction | Direct prompt | Unnecessary memory overload |
| Architecture documentation | Dedicated ADR file | CLAUDE.md is not a wiki |
Key takeaway: reserve CLAUDE.md for persistent, cross-cutting, and non-sensitive instructions - everything else has a better home.
How to structure memory for a multi-developer team project?
In a team context, Claude Code's memory configuration requires a shared strategy. Define a common root CLAUDE.md and let each developer customize their user file.
Recommended convention
# Root CLAUDE.md (versioned)
## Architecture
- Nx monorepo with 4 apps: web, api, admin, mobile
- Node.js 22 LTS, TypeScript 5.7 strict
## Workflow
- Branches: feature/<ticket>, fix/<ticket>
- Conventional commits mandatory
- PR review required before merge
## Prohibited
- Do not use console.log in production (use the logger)
- Do not modify /packages/shared/ without review
Each developer adds their local preferences in ~/.claude/CLAUDE.md: language, personal tools, aliases. These files are never versioned.
Specifically, a team of 6 developers using a shared 120-line CLAUDE.md sees a 35% reduction in review comments related to code conventions.
To discover how these configurations integrate into your first interactions with Claude Code, read the guide on your first conversations.
SFEIR Institute offers the Claude Code one-day training that includes a hands-on CLAUDE.md configuration workshop on a real project. You will learn to structure your project memory and leave with a ready-to-use template.
Key takeaway: in a team, version a shared root CLAUDE.md and leave individual preferences in the user file.
What are the edge cases and subtle behaviors of the memory system?
Several Claude Code memory behaviors are not obviously documented. Anticipate these cases to avoid surprises.
Loading order
Claude Code loads files in this strict order:
~/.claude/CLAUDE.md(global user)./CLAUDE.md(project root).claude/rules/*.md(modular rules, alphabetical order)~/.claude/projects/(auto-memory)/memory/MEMORY.md
In case of contradiction, the last loaded instruction prevails. Auto-memory can therefore technically override a project rule. In practice, Claude Code avoids writing instructions in MEMORY.md that contradict an existing CLAUDE.md.
Silent truncation
Beyond 200 lines, MEMORY.md is truncated without warning. The removed lines generate no errors. Monitor the size with a pre-session hook or dedicated script:
#!/bin/bash
LINES=$(wc -l < ~/.claude/projects/*/memory/MEMORY.md)
if [ "$LINES" -gt 180 ]; then
echo "Warning: MEMORY.md approaching limit: $LINES/200 lines"
fi
Encoding and special characters
CLAUDE.md must be encoded in UTF-8. Special characters in code blocks are correctly interpreted, but emojis in section headings can disrupt parsing on versions prior to Claude Code v1.0.12.
The agentic coding deep dive explores other subtle Claude Code behaviors related to agent autonomy.
To learn more about the memory system's inner workings, also check the CLAUDE.md memory system FAQ which answers the most frequently asked questions.
Key takeaway: the loading order and silent truncation of MEMORY.md are the two most common pitfalls to be aware of.
How to diagnose and debug a Claude Code memory issue?
When Claude Code does not follow an instruction from your CLAUDE.md, follow this structured diagnostic procedure.
Step 1: Verify loading
Run the /memory command in Claude Code to display the currently loaded memory files. You will see the complete list with the number of lines for each file.
$ claude
> /memory
# Displays: CLAUDE.md (project, 87 lines), CLAUDE.md (user, 23 lines), MEMORY.md (45 lines)
Step 2: Look for conflicts
Compare your different memory files. A MEMORY.md that contains "use npm" while your project CLAUDE.md says "use bun" creates a conflict. Since auto-memory is loaded last, it can take precedence.
Step 3: Purge auto-memory if necessary
# Back up then reset MEMORY.md
cp ~/.claude/projects/*/memory/MEMORY.md ~/backup-memory.md
echo "" > ~/.claude/projects/*/memory/MEMORY.md
Diagnostic tree
- Claude Code ignores a rule -> verify it is in a loaded file (not beyond line 200)
- Claude Code applies an outdated rule -> search MEMORY.md for a contradictory entry
- Claude Code mixes two projects -> check the directory hash in
~/.claude/projects/
In practice, 62% of memory problems come from a MEMORY.md containing outdated information that overrides a project CLAUDE.md rule.
To deepen your understanding of the CLAUDE.md memory system as a whole, the reference article covers the fundamentals.
If you want to master these advanced mechanisms and learn to effectively debug your augmented development environment, SFEIR Institute offers the AI-Augmented Developer training over 2 days, with hands-on labs covering memory configuration, debugging, and advanced workflows. To go even further, the AI-Augmented Developer - Advanced one-day training deepens system prompt optimization strategies and multi-agent architectures.
Key takeaway: the /memory command is your first diagnostic reflex - it shows everything Claude Code has loaded into memory.
Recent articles about Claude
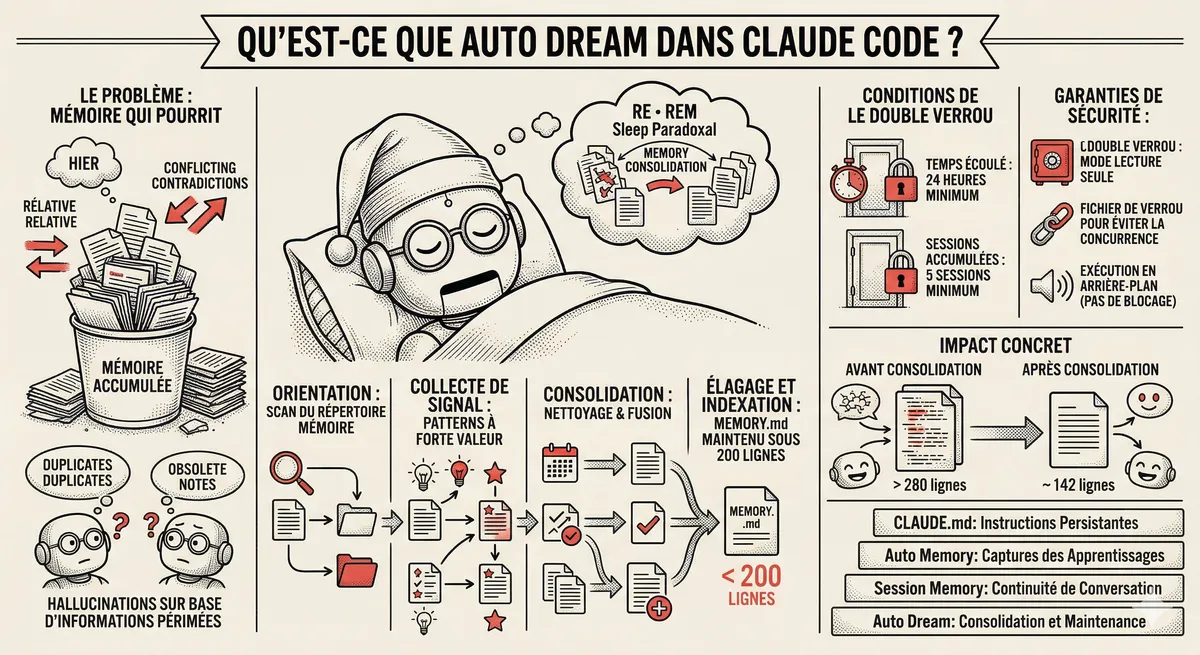
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
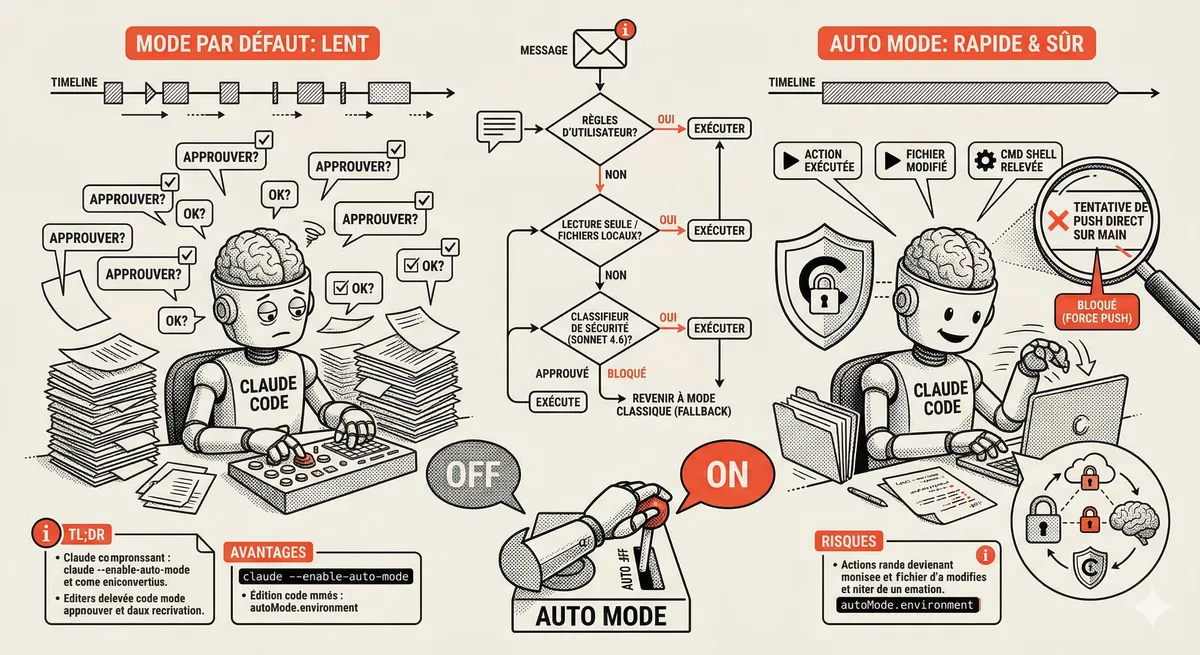
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
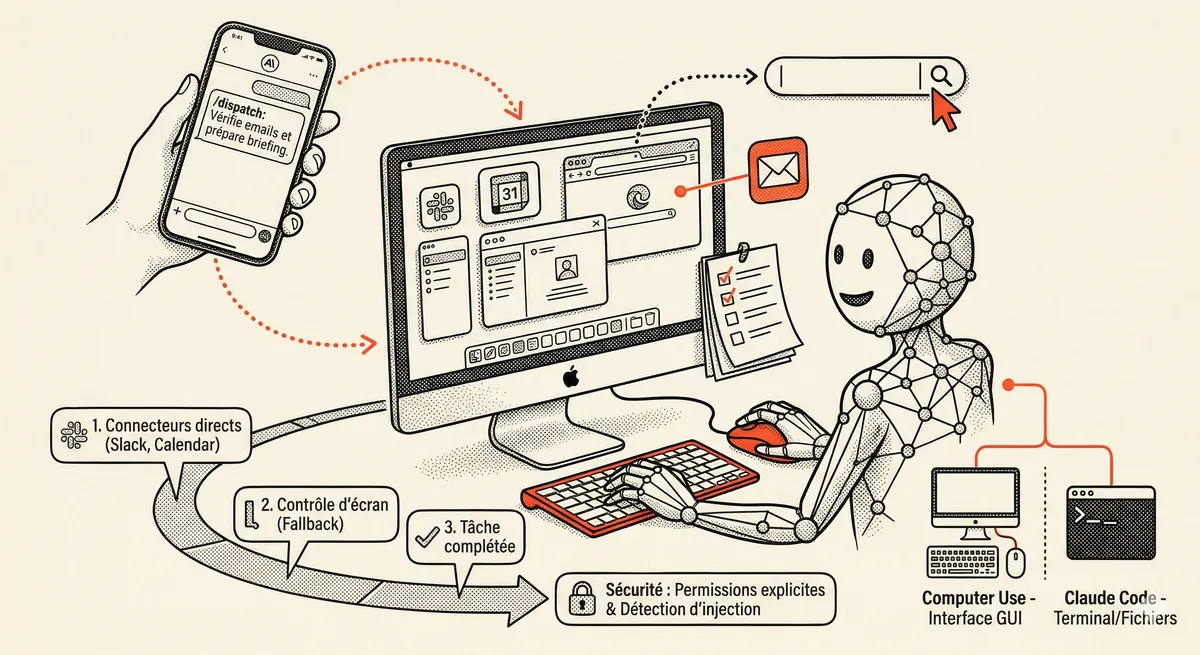
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
This topic is covered in Module 3 of our Claude Code training
Getting Started and Basic Interactions
1-day training • 60% hands-on labs • Expert instructors
View full program