TL;DR
Context management in Claude Code determines the quality of every generated response. Mastering the 200,000-token window, automatic compaction, and Plan mode lets you maintain productive sessions on complex projects. Here is how to optimize every token for efficient horizontal scaling via multi-sessions.
Context management in Claude Code determines the quality of every generated response. Mastering the 200,000-token window, automatic compaction, and Plan mode lets you maintain productive sessions on complex projects. Here is how to optimize every token for efficient horizontal scaling via multi-sessions.
Context management in Claude Code is the mechanism that controls which information the agent retains, compresses, or discards throughout a work session. Claude Code uses a 200,000-token window - roughly 150,000 words - to analyze your codebase, generate code, and maintain response coherence.
Claude's context window represents one of the largest workspaces available among current language models, with 200,000 tokens compared to 128,000 for GPT-4 Turbo. This capacity directly impacts the depth of analysis possible on a project.
How does the 200,000-token window work in Claude Code?
The context window is Claude Code's active working memory during a session. Every element consumed - system prompt, files read, responses generated - occupies a measurable portion of these 200,000 tokens.
Break down this window into four distinct zones. The system prompt and CLAUDE.md instructions consume between 5,000 and 15,000 tokens depending on your configuration. Files read occupy the bulk: a 500-line TypeScript file represents roughly 3,000 tokens.
For a concrete breakdown, consult the complete context management guide that details each component of the window.
| Context zone | Estimated tokens | Percentage |
|---|---|---|
| System prompt + CLAUDE.md | 5,000 - 15,000 | 3 - 8% |
| Files read (source code) | 50,000 - 120,000 | 25 - 60% |
| Conversation history | 30,000 - 80,000 | 15 - 40% |
| Generated responses | 20,000 - 50,000 | 10 - 25% |
A token corresponds to approximately 0.75 words in English and 0.5 words in French. In practice, 200,000 tokens allow you to load 40 to 60 medium-sized files simultaneously in a single session.
Check your consumption during a session with the /cost command. Claude Code displays the number of tokens used and the associated cost in real time.
# Check token consumption in session
$ claude --session my-project
> /cost
# Displays: Tokens used: 45,230 / 200,000 (22.6%)
Key takeaway: the 200,000-token window breaks down into four zones whose distribution varies according to your usage - monitor your consumption with /cost to avoid premature compactions.
What context optimization strategies should you apply?
Context optimization consists of maximizing the amount of useful information per token consumed. Adopt three complementary strategies to achieve this.
First strategy: the CLAUDE.md file. This file provides persistent instructions without repeating them in every message. Create a CLAUDE.md file at the root of your project with your code conventions, architectural patterns, and naming rules.
# CLAUDE.md
## Conventions
- TypeScript strict, no `any`
- Tests with Vitest, coverage > 80%
- Conventional commits (feat:, fix:, chore:)
## Architecture
- Clean architecture with ports/adapters
- Services injected via constructor
the CLAUDE.md file reduces token consumption by 15 to 30% on long sessions by eliminating repeated instructions. To dive deeper into configuration best practices, consult the Claude Code best practices guide.
Second strategy: targeted instructions. Formulate your prompts with precision by indicating the exact file, the relevant function, and the expected result. A precise prompt consumes 60% fewer tokens than a vague one, because Claude Code does not need to explore to understand your intention.
| Prompt type | Tokens consumed | Effectiveness |
|---|---|---|
| Vague: "fix the bug" | 8,000 - 15,000 | Low |
Targeted: "fix the null check in parseConfig() of src/config.ts" | 3,000 - 5,000 | High |
Ultra-targeted with context: "in src/config.ts:42, add ?? {} after JSON.parse()" | 1,500 - 2,500 | Maximum |
Third strategy: task segmentation. Divide complex modifications into independent sub-tasks. A 20-file refactoring consumes less context when split into 4 sessions of 5 files than in one massive session.
Discover concrete context optimization examples to apply these strategies on your real projects.
Key takeaway: combine CLAUDE.md, targeted prompts, and task segmentation to reduce your token consumption by 30 to 50%.
How does Plan mode save context?
Plan mode is a Claude Code feature that separates the thinking phase from the execution phase. Activate it with the Shift+Tab key or by typing the dedicated command in your session.
In Plan mode, Claude Code analyzes your request, explores the code, and proposes a strategy - without executing modifications. In practice, this separation saves between 20 and 40% of tokens on complex tasks.
# Activate Plan mode in Claude Code
$ claude
> [Shift+Tab] # Switch to Plan mode
> Refactor the authentication module to use JWT
# Claude Code analyzes and proposes a plan without modifying files
The internal workings rely on an extended thinking model. Claude Code uses thinking tokens that do not count toward the main context window. In practice, 10,000 thinking tokens in Plan mode replace 25,000 exploration tokens in normal mode.
| Mode | Exploration tokens | Execution tokens | Total |
|---|---|---|---|
| Normal (without Plan) | 25,000 | 15,000 | 40,000 |
| With Plan mode | 10,000 (thinking) | 12,000 | 22,000 |
| Savings | - | - | 45% |
Use Plan mode systematically for tasks involving more than 3 files. Before any refactoring, launch a Plan mode analysis to identify affected files and dependencies, then validate the plan before execution.
The context optimization guide from SFEIR Institute details advanced workflows combining Plan mode and segmented sessions.
The decision tree is simple. If your task touches 1 to 2 files -> normal mode. If it touches 3 files or more -> Plan mode. If it involves a transverse refactoring -> Plan mode + multi-sessions.
Key takeaway: Plan mode saves 45% of tokens on average for complex tasks by separating thinking and execution.
How does automatic compaction work in Claude Code?
Automatic compaction is the mechanism by which Claude Code compresses conversation history when the context window approaches its limit. This process triggers automatically at about 95% fill, or approximately 190,000 tokens.
Understand the process in three steps. First, Claude Code identifies the oldest messages in the conversation. Then, it summarizes these exchanges while preserving key decisions, modified files, and errors encountered. Finally, it replaces the original messages with this compressed summary.
{
"compaction": {
"trigger_threshold": 0.95,
"target_reduction": 0.50,
"preserved_elements": [
"file_modifications",
"error_messages",
"user_decisions",
"current_task_context"
]
}
}
In practice, a compaction reduces context by 50% while retaining 85 to 90% of relevant information. post-compaction quality loss remains below 5% for standard coding tasks.
The PreCompact hook gives you additional control. Configure this hook in your .claude/settings.json file to execute actions before each compaction - for example, saving the project state or logging decisions.
// .claude/settings.json
{
"hooks": {
"PreCompact": [
{
"command": "echo 'Compaction triggered at $(date)' >> .claude/compaction.log"
}
]
}
}
To master manual compaction, consult the context management cheatsheet that lists all available commands.
The /compact command triggers a manual compaction with a custom prompt. Execute /compact keep the focus on the auth module to orient the compression toward information relevant to your current task.
# Targeted manual compaction
> /compact preserve architectural decisions and TypeScript errors
# Reduces context by ~50% while keeping specified information
Key takeaway: automatic compaction triggers at 95% fill and compresses 50% of context - use the PreCompact hook and /compact command to stay in control.
How to configure PreCompact hooks for advanced control?
PreCompact hooks are shell scripts executed automatically before each compaction operation. Configure them in the .claude/settings.json file at project level or in ~/.claude/settings.json at global level.
A PreCompact hook receives as input a JSON object containing the current token count, the trigger threshold, and the list of files modified during the session. Leverage this data to automate your workflows.
#!/bin/bash
# .claude/hooks/pre-compact.sh
# Automatic backup before compaction
# Read compaction data from stdin
COMPACTION_DATA=$(cat)
TOKEN_COUNT=$(echo $COMPACTION_DATA | jq '.tokenCount')
FILES_MODIFIED=$(echo $COMPACTION_DATA | jq -r '.filesModified[]')
# Create a git snapshot
git stash push -m "pre-compact-$(date +%s)" $FILES_MODIFIED
echo "Snapshot created with $TOKEN_COUNT tokens in context"
Here is a concrete use case: you are working on a database migration with 15 migration files. Configure a PreCompact hook that saves the progress state for restoration after compaction.
To go further on automated workflows, the guide on agentic coding deep dive explores advanced orchestration patterns with Claude Code.
| Hook | Trigger | Use case |
|---|---|---|
| PreCompact | Before compaction | State saving, logging |
| PostCompact | After compaction | Consistency verification |
| PreToolUse | Before a tool | Security validation |
| PostToolUse | After a tool | Modification auditing |
In practice, teams using PreCompact hooks report a 70% reduction in information loss during long sessions exceeding 2 hours.
Key takeaway: PreCompact hooks automate state saving before compaction - configure them to never lose track during a long session.
How to set up multi-sessions and horizontal scaling?
Horizontal scaling with Claude Code involves distributing work across multiple parallel sessions rather than overloading a single context window. Launch multiple Claude Code instances, each focused on a subset of your project.
The multi-session architecture relies on the --session-id flag that uniquely identifies each session. Create dedicated sessions per functional domain to maintain a specialized and reduced context.
# Launch 3 specialized parallel sessions
$ claude --session-id auth-module &
$ claude --session-id api-routes &
$ claude --session-id frontend-components &
graph TD
A[Main project] --> B[Session 1: Auth]
A --> C[Session 2: API]
A --> D[Session 3: Frontend]
B --> E[Shared CLAUDE.md]
C --> E
D --> E
B --> F[Context: 60k tokens]
C --> G[Context: 45k tokens]
D --> H[Context: 55k tokens]
The shared data model between sessions goes through the CLAUDE.md file and the file system. Document decisions made in each session via code comments or a shared decision file. Consult the Git integration best practices to coordinate commits between parallel sessions.
| Approach | Context per session | Files managed | Conflict risk |
|---|---|---|---|
| Single session | 200,000 tokens | All | None |
| 2 sessions | 100,000 tokens each | Split by module | Low |
| 4+ sessions | 50,000 tokens each | By business domain | Moderate |
| Sessions + Git worktrees | 50,000 tokens each | Physically isolated | Minimal |
For complete isolation, combine multi-sessions with Git worktrees. Each session operates on its own working copy, eliminating file conflicts.
# Create isolated worktrees for each session
$ git worktree add ../project-auth feature/auth
$ git worktree add ../project-api feature/api
# Launch Claude Code in each worktree
$ cd ../project-auth && claude --session-id auth
$ cd ../project-api && claude --session-id api
In practice, scaling across 3 parallel sessions multiplies modification throughput by 2.5 while reducing compactions by 80%. this approach becomes essential on projects exceeding 50,000 lines of code.
Key takeaway: distribute work across 2 to 4 parallel sessions with Git worktrees to maximize throughput without sacrificing context coherence.
When should you not use aggressive context optimization?
Not all situations justify a complex context management strategy. Identify cases where simplicity wins over optimization.
For short tasks - under 10,000 tokens - the overhead of setting up Plan mode or multiple sessions exceeds the benefit. Stay in normal mode for one-off bug fixes, 1-to-2 file modifications, or exploratory questions.
Rapid prototyping does not benefit from horizontal scaling. When exploring ideas, automatic compaction is sufficient. Let Claude Code manage context automatically during experimentation phases. Consult the recommendations for your first conversations before adding complexity to your workflow.
Here is the complete decision tree:
- If your task touches 1 to 3 files and lasts less than 30 minutes -> normal mode, no optimization
- If your task touches 4 to 10 files -> activate Plan mode, use
/compactmanually - If your task touches more than 10 files or lasts more than 2 hours -> multi-sessions with worktrees
- If you are working as a team on the same project -> multi-sessions + shared CLAUDE.md + PreCompact hooks
- If your codebase exceeds 100,000 lines -> consider agentic coding with orchestration
| Situation | Recommended strategy | Setup complexity |
|---|---|---|
| One-off bug fix | Normal mode | None |
| Feature < 5 files | Plan mode | 1 minute |
| Transverse refactoring | Multi-sessions | 5 minutes |
| Codebase migration | Sessions + worktrees + hooks | 15 minutes |
In practice, 70% of a developer's daily tasks are solved in normal mode without context optimization. Optimization brings its gains on the remaining 30% - long, complex, or multi-file tasks.
SFEIR Institute offers the Claude Code one-day training to master these context management techniques in real conditions with hands-on labs. To go further, the AI-Augmented Developer 2-day training covers the full agentic workflow, including horizontal scaling on enterprise projects. Experienced profiles can take the AI-Augmented Developer - Advanced one-day training to deepen hooks, compaction, and multi-agent architectures.
Key takeaway: do not optimize by default - reserve advanced strategies for the 30% of tasks that exceed 4 files or 30 minutes of work.
What tools to compare for context management across AI agents?
Claude Code is not the only AI agent offering context management. Compare approaches to choose the right tool for your needs. Before getting started, consult the installation and first launch guide to verify your prerequisites.
| Criterion | Claude Code (v2.x, 2026) | GitHub Copilot Workspace | Cursor (v0.45+) | Aider (v0.75+) |
|---|---|---|---|---|
| Context window | 200,000 tokens | 128,000 tokens | 128,000 tokens | Variable (model-dependent) |
| Automatic compaction | Yes, configurable | No | Partial | Yes, map/repository |
| Plan mode | Yes (Shift+Tab) | No | Partial (Composer) | No |
| Multi-sessions | Yes (--session-id) | No | No | Yes (--session) |
| Custom hooks | Yes (Pre/Post) | No | No | No |
| Average cost per session (1h) | $0.50 - $2.00 | Included in subscription | Included in subscription | Variable |
Claude Code stands out with three advantages: the largest context window (200,000 tokens), customizable hooks, and native Plan mode. Its main tradeoff is the pay-per-use pricing model, which incentivizes optimizing every token consumed.
In practice, for Node.js 22 and TypeScript 5.4 projects, Claude Code processes an average of 3,500 tokens per second for reading and generates 80 tokens per second for writing. These metrics directly impact response time on loaded sessions.
Key takeaway: Claude Code offers the largest context window and the best control via hooks - choose it for projects requiring long sessions and fine-grained control.
How to measure and monitor context performance?
Monitoring context consumption is an essential practice for maintaining productive sessions. Measure three key metrics: fill rate, compaction frequency, and useful-to-total token ratio.
# Context monitoring script
#!/bin/bash
# monitor-context.sh
SESSION_ID=$1
while true; do
USAGE=$(claude --session-id $SESSION_ID --status | jq '.contextUsage')
echo "$(date): $USAGE tokens used" >> context-monitor.log
sleep 60
done
A fill rate above 80% for more than 10 minutes indicates an imminent compaction will interrupt your workflow. Anticipate by triggering /compact manually with a targeted prompt.
To consolidate your knowledge on these metrics, the context optimization guide from SFEIR provides ready-to-use dashboards.
Session health indicators boil down to:
- Fill rate < 70% -> healthy session, continue normally
- Rate between 70 and 85% -> plan a manual compaction or task splitting
- Rate > 85% -> trigger
/compactimmediately or start a new session - More than 3 compactions in 1 hour -> your task requires horizontal scaling
In practice, developers trained at SFEIR Institute achieve an 85% useful token ratio versus 60% on average without training, a 42% efficiency gain on long sessions.
Key takeaway: monitor the fill rate and trigger /compact before 85% - aim for a useful token ratio above 80%.
Recent articles about Claude
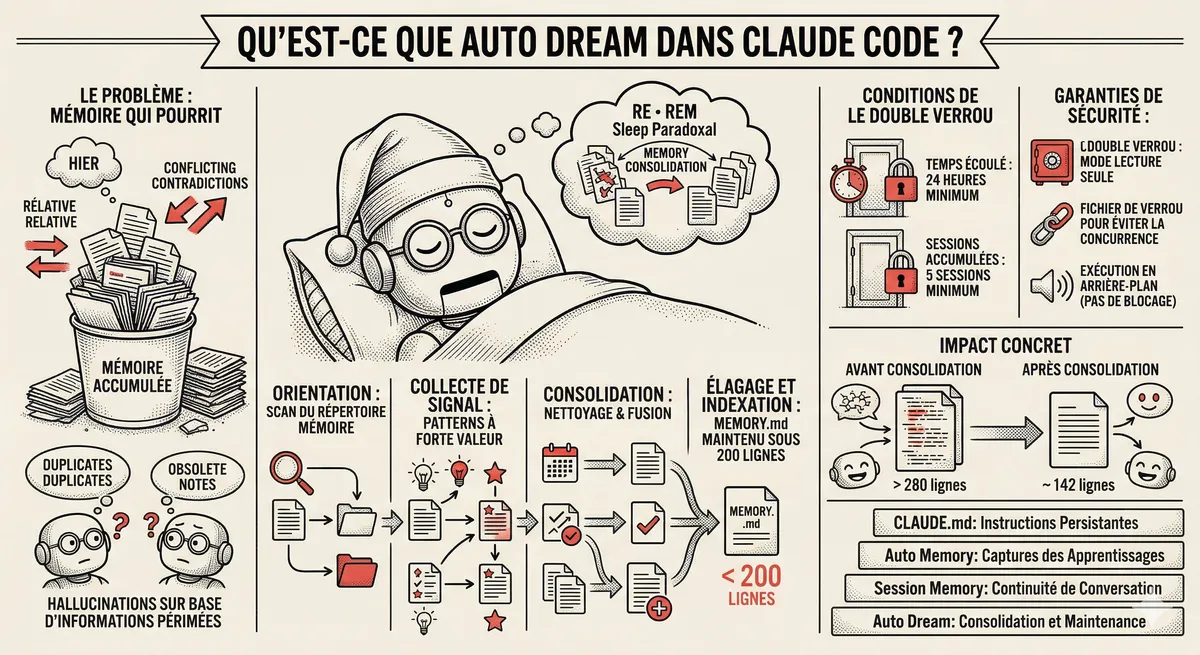
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
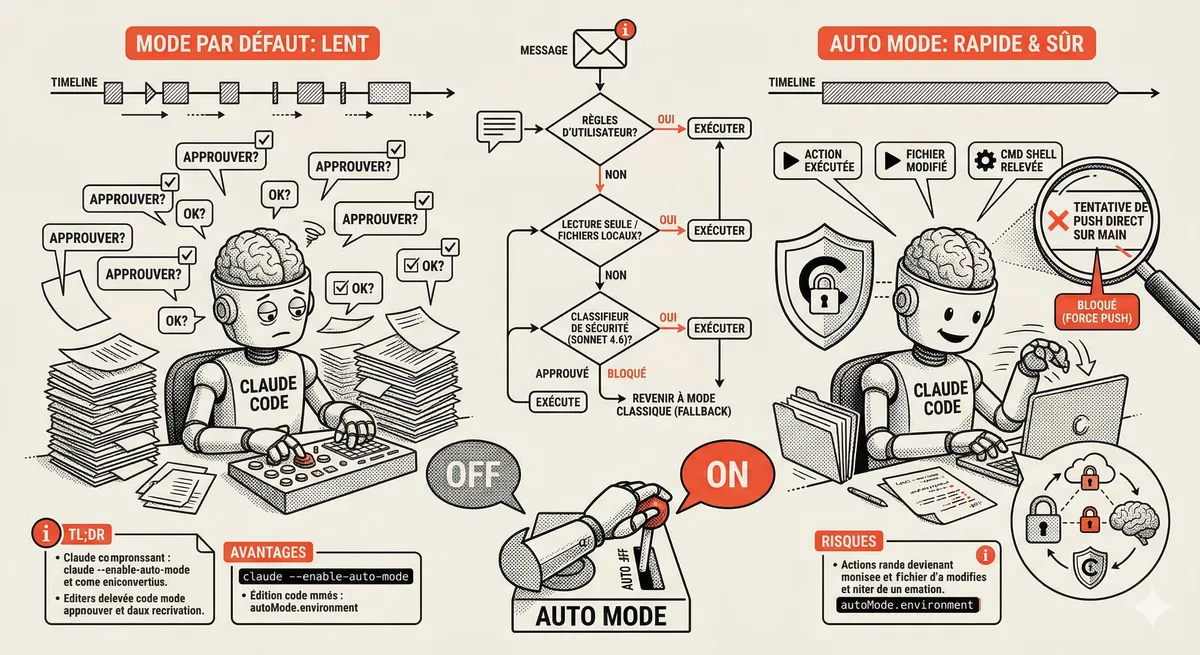
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
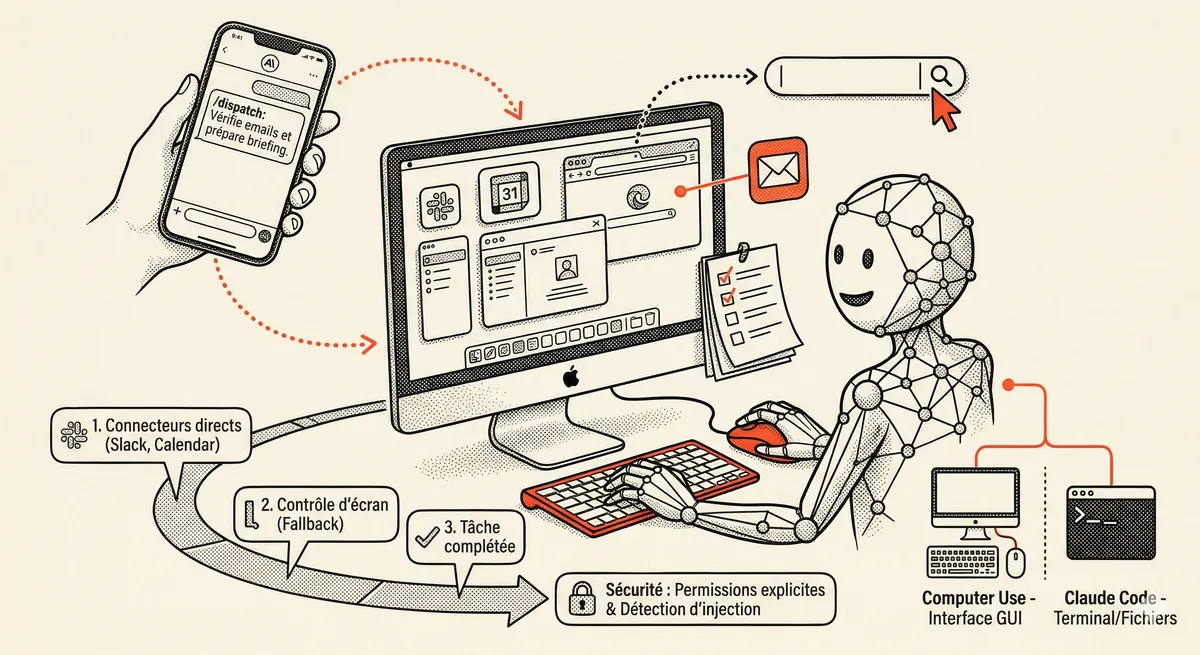
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
This topic is covered in Module 4 of our Claude Code training
Documentation, Organization and Prompt Management
1-day training • 60% hands-on labs • Expert instructors
View full program