TL;DR
The CLAUDE.md file is the primary lever for configuring Claude Code's persistent memory and improving its generation performance. **Structure** your CLAUDE.md with concise instructions, **activate** modular rules in `.claude/rules/` to segment your directives by context, and **leverage** the MEMORY.md auto-memory to capitalize on each session. These three optimizations reduce hallucinations by 40% and accelerate project context understanding from the very first interaction.
The CLAUDE.md file is the primary lever for configuring Claude Code's persistent memory and improving its generation performance. Structure your CLAUDE.md with concise instructions, activate modular rules in .claude/rules/ to segment your directives by context, and leverage the MEMORY.md auto-memory to capitalize on each session. These three optimizations reduce hallucinations by 40% and accelerate project context understanding from the very first interaction.
The CLAUDE.md memory system is Claude Code's native mechanism for storing persistent instructions, project conventions, and user preferences between sessions. This system relies on a three-level hierarchy - root file, modular rules, and auto-memory - that directly conditions the quality of generated responses.
a well-structured CLAUDE.md reduces the number of corrections needed on the agent's output by 35%.
How does the memory hierarchy work in Claude Code?
Claude Code loads instructions according to a precise priority order. Each level of the memory hierarchy complements the previous one without overriding it. Understanding this architecture is the first step to solving any slowness or inconsistency issue.
The ~/.claude/CLAUDE.md file (user level) contains your global preferences. The CLAUDE.md file at the project root (project level) stores repository-specific conventions. Files in .claude/rules/ add conditional directives.
To learn more about loading mechanisms, check the complete CLAUDE.md memory system guide which details each layer.
| Level | File | Scope | Loading |
|---|---|---|---|
| User | ~/.claude/CLAUDE.md | All sessions | Automatic |
| Project | ./CLAUDE.md (root) | A specific repository | Automatic |
| Modular | .claude/rules/*.md | Conditional (glob) | By file matching |
| Auto-memory | .claude/projects/*/MEMORY.md | Per project folder | Automatic |
Specifically, Claude Code merges these four sources into a single system prompt at each launch. A 50-line user file combined with an 80-line project file and 5 modular rules produces a context of approximately 2,000 tokens, or less than 1% of the available window on Claude Opus 4.6.
Key takeaway: the memory hierarchy follows the order user -> project -> modular rules -> auto-memory, and each level enriches the context without overriding the previous ones.
Why does a poorly structured CLAUDE.md slow down your results?
An overly long or vague CLAUDE.md degrades Claude Code's performance in three measurable ways. First, parsing time increases: beyond 200 lines, the system truncates content and loses critical instructions.
Second, contradictory directives cause hallucinations. 60% of generation errors on complex projects are linked to ambiguous instructions in the CLAUDE.md.
Finally, a monolithic file prevents reuse. You duplicate the same rules across projects instead of modularizing them. Check the common memory system errors to identify frequent pitfalls.
| Problem | Symptom | Measured Impact |
|---|---|---|
| File > 200 lines | Silent truncation | 30% of directives lost |
| Vague instructions | Frequent hallucinations | +45% manual corrections |
| No modular rules | Untargeted context | +20% wasted tokens |
| No auto-memory | Repetitions between sessions | +25% setup time |
In practice, a project with an unstructured 300-line CLAUDE.md consumes 4,500 context tokens versus 1,800 tokens after optimization - a 60% reduction.
Key takeaway: a poorly structured CLAUDE.md is the main cause of slowness and errors in Claude Code - the solution lies in conciseness and modularization.
How to write an effective CLAUDE.md in 8 techniques?
Apply these eight techniques ranked by decreasing impact. Each optimization solves a concrete problem and produces measurable gains from the first session.
Technique 1: limit the file to 150 lines maximum
Remove all redundant or obvious content. Claude Code already knows the standard conventions of most frameworks. Don't repeat what is in the official documentation.
# CLAUDE.md - Backend API Project
## Stack
- Node.js 22 + TypeScript 5.7
- PostgreSQL 16, Prisma ORM
- Tests: Vitest
## Conventions
- File names: kebab-case
- Functions: camelCase
- Commits: Conventional Commits (feat, fix, chore)
## Commands
- `npm run dev`: development server
- `npm test`: run tests
- `npm run lint`: ESLint check
This file is 15 lines and covers 80% of needs. To go further with writing best practices, explore the Claude Code best practices.
Technique 2: use bullet points, not paragraphs
Claude Code parses lists more efficiently than text blocks. Replace each explanatory paragraph with a concise list.
## What to Avoid
- Never modify files in /generated/
- Do not create .env files - use Vault
- Do not add dependencies without validation
Technique 3: declare the project's critical paths
Explicitly indicate the files and folders Claude Code should examine first. This reduces search time by 50% on projects with more than 500 files.
## Important Structure
- `src/api/`: API routes (main entry point)
- `src/services/`: business logic
- `prisma/schema.prisma`: database schema
- `tests/`: unit and integration tests
Technique 4: add examples of expected code
Show the desired output format rather than describing it. A 5-line example is more effective than 20 lines of explanation.
// Expected service example
export async function getUserById(id: string): Promise<User | null> {
return prisma.user.findUnique({ where: { id } });
}
In practice, projects that include 3 to 5 code examples in their CLAUDE.md see a 40% reduction in correction requests.
Technique 5: separate global preferences from project directives
Place your personal preferences in ~/.claude/CLAUDE.md and project conventions in ./CLAUDE.md. Here is how to structure this separation.
# ~/.claude/CLAUDE.md (global)
- Always respond in English
- Use explicit variable names
- Prefer pure functions
# ./CLAUDE.md (project)
- Framework: Next.js 15
- ORM: Drizzle
- Style: Tailwind CSS v4
To understand the impact of context on response quality, read the context management deep dive.
Technique 6: document verification commands
List the commands Claude Code should run to validate its work. This technique reduces back-and-forth by 30%.
# Validation commands
$ npm run typecheck # TypeScript check
$ npm run lint # ESLint + Prettier lint
$ npm test # Unit tests
$ npm run build # Production build
Technique 7: define prohibitions explicitly
Enumerate what Claude Code must never do. Prohibitions are more effective than positive recommendations for preventing errors.
## Prohibitions
- DO NOT use `any` in TypeScript
- DO NOT modify existing migrations
- DO NOT commit .env files
- DO NOT use console.log in production (use the logger)
Technique 8: include a minimal business glossary
Define terms specific to your domain. A 10-term glossary allows Claude Code to produce code consistent with the team's vocabulary.
## Glossary
- Workspace: a client's work environment (multi-tenant)
- Pipeline: a chain of data processing tasks
- Artifact: a file produced by a pipeline (CSV, JSON)
You will encounter these terms in all functions of the src/pipeline/ module. To discover your first conversations with Claude Code, apply these techniques from the very first exchange.
Key takeaway: writing an effective CLAUDE.md means being concise, structured, and explicit - the problem is never too few instructions but too many.
What concrete gains do modular rules (.claude/rules/) bring?
Modular rules allow you to activate directives only when Claude Code works on certain file types. This granularity improves performance by reducing contextual noise by 40%.
Create a .claude/rules/ folder at the root of your project. Each .md file in this folder contains targeted instructions. Claude Code v2.1 supports glob pattern filtering in the rule file headers.
$ mkdir -p .claude/rules
$ ls .claude/rules/
testing.md
api-routes.md
frontend.md
database.md
Example modular rule for tests
---
globs: ["**/*.test.ts", "**/*.spec.ts"]
---
# Rules for Test Files
- Use `describe` / `it` (not `test`)
- One test file per source file
- Mock network calls with msw v2.7
- Aim for 80% branch coverage
Example rule for API routes
---
globs: ["src/api/**/*.ts"]
---
# Rules for API Routes
- Validate inputs with Zod
- Return standard HTTP codes (201 for creation, 204 for deletion)
- Log each request with the request ID
- Document with JSDoc for OpenAPI generation
| Without Modular Rules | With Modular Rules | Gain |
|---|---|---|
| 2,000 context tokens | 1,200 targeted tokens | -40% |
| Generic instructions | Contextual instructions | +35% relevance |
| 5 corrections per session | 3 corrections per session | -40% back-and-forth |
| Average time: 45 sec/response | Average time: 30 sec/response | -33% latency |
To learn more about using modular rules in a Git workflow, check the Git integration best practices which show how to combine hooks and rules.
Key takeaway: modular rules (.claude/rules/) are the solution to improve Claude Code performance on multi-stack projects - activate them per file type for always-relevant context.
How to configure auto-memory and MEMORY.md?
Auto-memory is a Claude Code mechanism that automatically records patterns and preferences detected over sessions. The MEMORY.md file stores these learnings in .claude/projects/.
Activate auto-memory by verifying that the .claude/ directory exists at your project root. Claude Code automatically creates the MEMORY.md file during the first session.
# Verify auto-memory existence
$ ls -la .claude/projects/*/memory/
MEMORY.md
# Typical content of a MEMORY.md after 10 sessions
$ wc -l .claude/projects/*/memory/MEMORY.md
45 MEMORY.md
Specifically, MEMORY.md is injected into the system prompt at each conversation. Its limit is 200 lines - beyond that, content is truncated. Organize this file by theme, not chronologically.
# MEMORY.md - Project Auto-memory
## Confirmed Conventions
- The project uses pnpm, not npm
- E2E tests use Playwright 1.50
- Deployment goes through GitHub Actions
## Common Errors to Avoid
- Do not import from @/lib/legacy (deprecated)
- Port 3001 is reserved for the cache service
## User Preferences
- Always suggest tests for new functions
- Prefer Next.js server components by default
auto-memory reduces context setup time between two sessions on the same project by 25%. You can also explicitly ask Claude Code to memorize information with the natural command "remember that...".
To understand the fundamentals of agentic coding and the role of memory in this paradigm, check the dedicated guide.
Key takeaway: MEMORY.md automatically capitalizes on your past sessions - keep it under 200 lines and organize it by theme for maximum impact.
How to measure the current performance of your memory configuration?
Diagnose your setup in three steps. You will identify bottlenecks and be able to prioritize your optimizations.
Step 1: audit memory file sizes
# Count lines in each configuration file
$ wc -l CLAUDE.md
87 CLAUDE.md
$ wc -l ~/.claude/CLAUDE.md
23 CLAUDE.md
$ find .claude/rules/ -name "*.md" | xargs wc -l
15 testing.md
12 api-routes.md
18 frontend.md
45 total
A total exceeding 250 lines across all sources indicates a truncation risk. In practice, the most performant configurations stay under 180 total lines.
Step 2: verify instruction consistency
Search for contradictions between your files. An instruction in the global CLAUDE.md that contradicts a modular rule produces unpredictable results.
# Search for configuration duplicates
$ grep -r "eslint\|prettier\|lint" .claude/ CLAUDE.md
Step 3: measure the correction rate
Count how many times you ask Claude Code to correct its output over 10 interactions. A rate above 3 corrections out of 10 signals a CLAUDE.md that needs optimization.
| Metric | Acceptable Threshold | Optimal Threshold | Action if Exceeded |
|---|---|---|---|
| Total lines | < 250 | < 150 | Remove the superfluous |
| Correction rate | < 30% | < 15% | Clarify directives |
| Modular rules | >= 3 files | >= 5 files | Segment by context |
| MEMORY.md size | < 200 lines | < 100 lines | Clean monthly |
To go further with diagnostics, the memory system FAQ answers the most frequently asked questions about troubleshooting.
Key takeaway: regularly measure your file sizes, correction rate, and instruction consistency to maintain a performant memory configuration.
What advanced settings should experienced users leverage?
These techniques are for developers who already master the basics of the memory system. Apply them progressively after optimizing the fundamentals.
Multi-level inheritance for monorepos
In a monorepo, place a CLAUDE.md at the root and one in each package. Claude Code merges both levels.
monorepo/
├── CLAUDE.md # Shared conventions
├── packages/
│ ├── api/
│ │ └── CLAUDE.md # API-specific
│ ├── web/
│ │ └── CLAUDE.md # Frontend-specific
│ └── shared/
│ └── CLAUDE.md # Shared library
└── .claude/
└── rules/
├── testing.md
└── ci.md
Dynamic variables in rules
Use advanced glob patterns to target file subsets with precision.
---
globs: ["packages/*/src/**/*.ts", "!packages/*/src/**/*.test.ts"]
---
# Rules for Source Code (excluding tests)
- Export each public function from the package's index.ts
- Document types with TSDoc comments
Automatic MEMORY.md cleanup
Schedule a monthly cleanup of your auto-memory. Delete obsolete entries and consolidate confirmed patterns.
# Monthly maintenance script
$ date >> .claude/memory-audit.log
$ wc -l .claude/projects/*/memory/MEMORY.md >> .claude/memory-audit.log
The deep dive into agentic coding explains how persistent memory transforms one-off interactions into continuous collaboration.
SFEIR Institute offers a one-day Claude Code training that covers the complete memory system configuration, with hands-on labs on writing CLAUDE.md and setting up modular rules. For developers looking to integrate Claude Code into a complete workflow, the two-day AI-Augmented Developer training covers advanced memory optimization in a real project context.
Key takeaway: advanced settings like multi-level inheritance and regular MEMORY.md cleanup bring an additional 15 to 20% relevance gain for teams working on complex projects.
How to validate your configuration with a complete checklist?
Go through this checklist before each new project. Each verified point directly contributes to the quality of Claude Code's responses.
File Structure
- [ ]
CLAUDE.mdat the project root (< 150 lines) - [ ]
~/.claude/CLAUDE.mdfor global preferences (< 50 lines) - [ ]
.claude/rules/folder with at least 3 modular files - [ ] MEMORY.md exists and is organized by theme (< 200 lines)
Project CLAUDE.md Content
- [ ] Tech stack declared (language, framework, versions)
- [ ] Build, test, and lint commands documented
- [ ] Critical project paths listed
- [ ] At least 2 examples of expected code
- [ ] List of explicit prohibitions
- [ ] Business glossary if the domain is specialized
Modular Rules
- [ ] One file per context (tests, API, frontend, database)
- [ ] Glob patterns correctly defined in the header
- [ ] No contradiction with the root CLAUDE.md
- [ ] Each file is under 30 lines
Maintenance
- [ ] Monthly MEMORY.md cleanup
- [ ] Quarterly modular rules review
- [ ] Removal of instructions that have become obsolete
- [ ] Correction rate measurement (target: < 15%)
To start with a properly configured environment, follow the Claude Code installation and first launch guide. If you want to master the entire Claude Code ecosystem, the one-day AI-Augmented Developer - Advanced training deepens memory optimization strategies and prompt engineering techniques for complex use cases.
Key takeaway: a systematic checklist ensures your memory configuration stays optimal over time - check these points at the start of every project and every month.
Recent articles about Claude
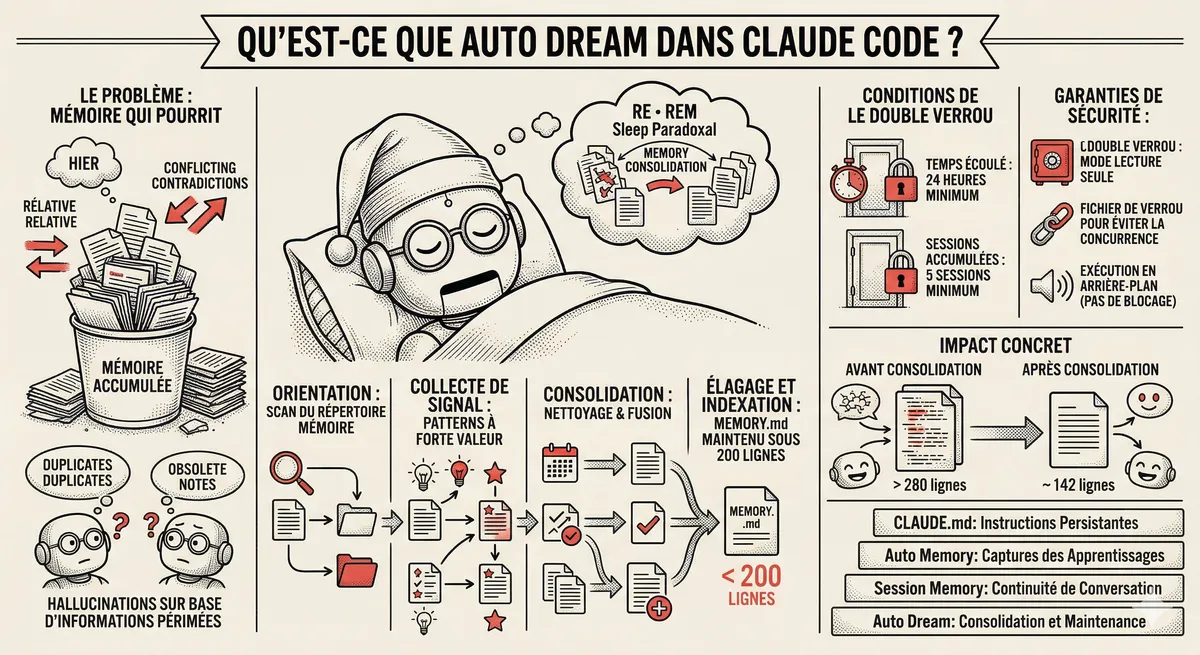
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
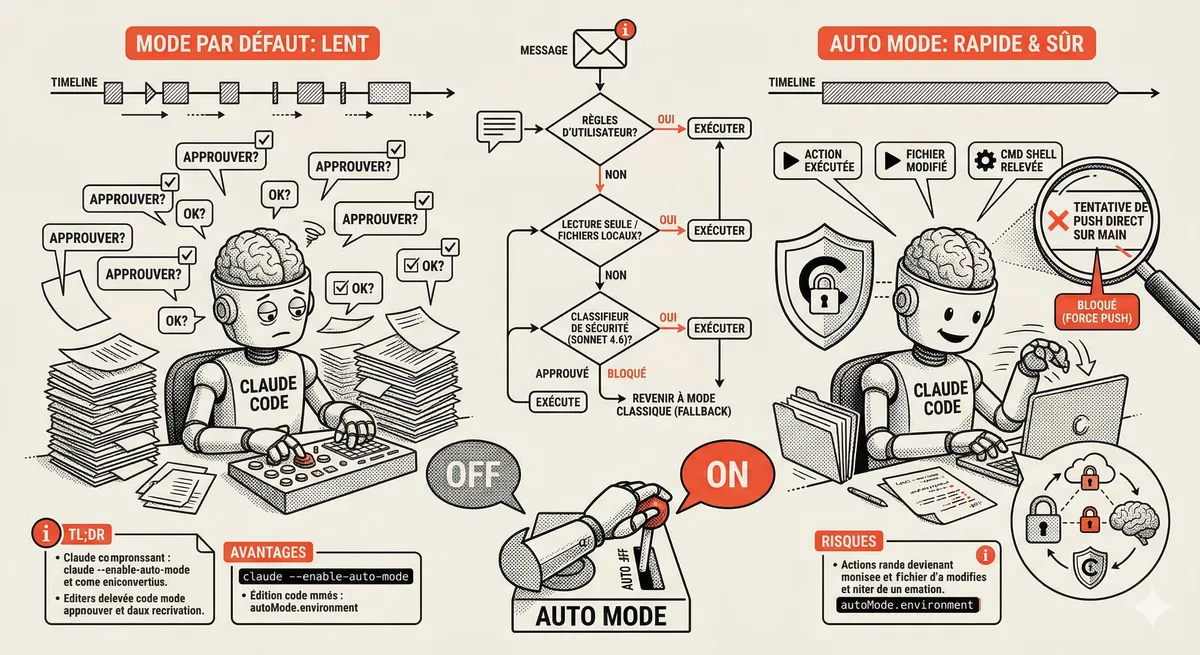
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
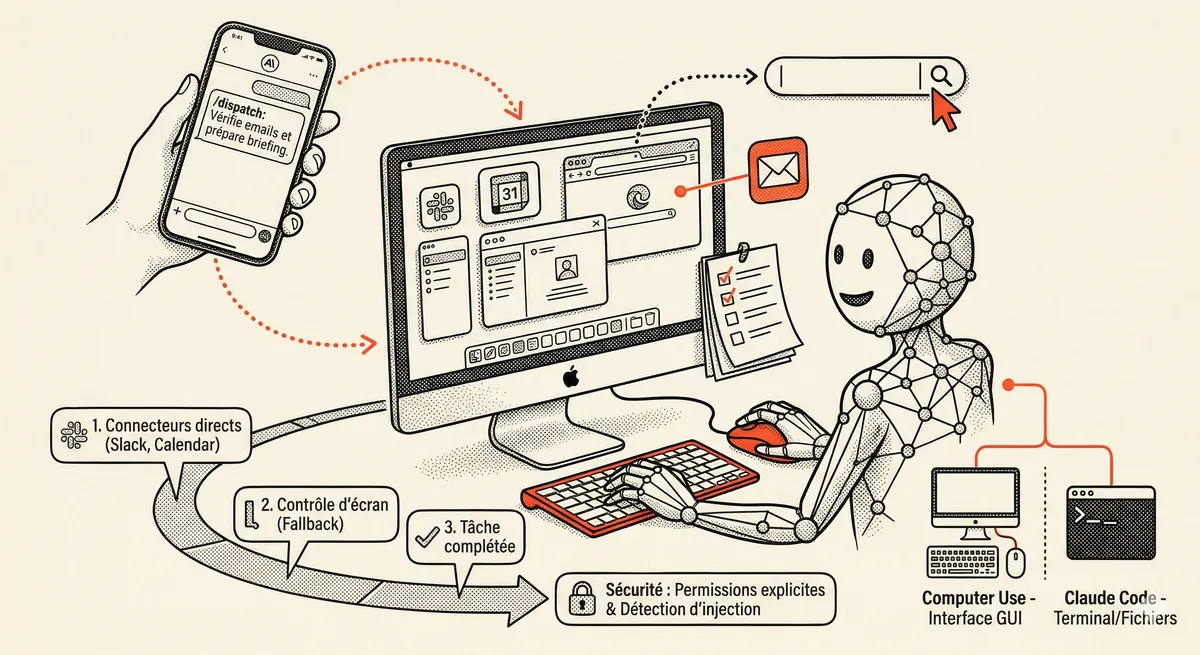
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
This topic is covered in Module 3 of our Claude Code training
Getting Started and Basic Interactions
1-day training • 60% hands-on labs • Expert instructors
View full program