TL;DR
Claude Code's headless mode transforms your CI/CD pipeline into an autonomous development assistant. Here are 10 concrete examples, from the simple `-p` flag to programmatic multi-turn sessions, for automating code reviews, documentation generation, and deployments via GitHub Actions.
Claude Code's headless mode transforms your CI/CD pipeline into an autonomous development assistant. Here are 10 concrete examples, from the simple -p flag to programmatic multi-turn sessions, for automating code reviews, documentation generation, and deployments via GitHub Actions.
Claude Code's headless mode is the ability to run Claude Code without an interactive interface, directly from a script or continuous integration pipeline. more than 60% of teams adopting Claude Code use it in non-interactive mode to automate repetitive tasks.
This approach reduces average code review time by 45% on projects with more than 50,000 lines. To understand the fundamentals before diving into these examples, check out the complete headless mode and CI/CD guide which covers the architecture and principles.
| Criterion | Interactive mode | Headless mode (-p) | Multi-turn session mode |
|---|---|---|---|
| Interface | Terminal with prompt | None (stdout) | None (JSON API) |
| Typical use | Local development | CI/CD, scripts | Complex pipelines |
| Output format | Formatted text | text, json, stream-json | json, stream-json |
| Average latency | Variable | 2-8 seconds | 3-12 seconds per turn |
How to run Claude Code in a single command with the -p flag?
The -p flag (for print) sends a single prompt to Claude Code and retrieves the response on standard output. Run this command for your first test:
$ claude -p "Explain the Repository pattern in TypeScript in 3 sentences"
The result is displayed directly in the terminal, without an interactive interface. You can redirect the output to a file with > or pipe it to another tool.
$ claude -p "Generate an optimized Dockerfile for Node.js 22" > Dockerfile
This command creates a ready-to-use Dockerfile in under 5 seconds. In practice, 80% of headless use cases start with this simple syntax. If you are new to Claude Code, the installation quickstart guides you step by step.
Variant: add --output-format json to get a structured response processable by jq:
$ claude -p "List 5 REST API best practices" --output-format json | jq '.result'
Key takeaway: the -p flag turns Claude Code into a standard CLI tool, compatible with all your existing shell scripts.
How to integrate Claude Code into GitHub Actions?
GitHub Actions is the most common CI/CD use case for Claude Code v1.0.20. Create a .github/workflows/claude-review.yml file with this configuration:
name: Claude Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Install Claude Code
run: npm install -g @anthropic-ai/claude-code@latest
- name: Run code review
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
DIFF=$(git diff origin/main...HEAD)
claude -p "Code review for this PR. Flag bugs, security flaws, and convention violations. Diff: $DIFF" --output-format json > review.json
- name: Post review comment
uses: actions/github-script@v7
with:
script: |
const review = require('./review.json');
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: review.result
});
This workflow runs on each pull request and automatically posts a review comment. automated workflows reduce PR merge time by 30%. You will find more automation tips in the advanced headless mode tips.
Configure the ANTHROPIC_API_KEY secret in your repository settings before the first run. The average cost per review is $0.02 to $0.08 depending on the diff size.
Key takeaway: a 25-line GitHub Action is enough to automate code review on every PR.
Which output formats to choose for automated parsing?
Claude Code supports three output formats in headless mode: text, json, and stream-json. Run each one to compare:
# Text format (default) - ideal for human reading
$ claude -p "Summarize this file" --output-format text
# JSON format - ideal for programmatic parsing
$ claude -p "Analyze this code" --output-format json
# stream-json format - ideal for real-time processing
$ claude -p "Generate 10 unit tests" --output-format stream-json
| Format | Average size | Parsing time | Recommended use case |
|---|---|---|---|
text | 1-5 KB | N/A | Logs, terminal display |
json | 2-8 KB | < 1 ms with jq | API, post-processing |
stream-json | 2-8 KB (streamed) | Real-time | Progressive interfaces, dashboards |
Concretely, the json format returns an object containing the fields result, model, usage, and stop_reason. Verify the structure with this command:
$ claude -p "Say hello" --output-format json | python3 -c "
import json, sys
data = json.load(sys.stdin)
print(f'Tokens used: {data[\"usage\"][\"output_tokens\"]}')
print(f'Result: {data[\"result\"][:100]}')
"
To deepen your understanding of parsing and response handling, the first conversations examples illustrate the different output modes. Also check the context management examples to optimize prompt size.
Key takeaway: use json for automated pipelines and stream-json when displaying results in real time.
How to create programmatic multi-turn sessions?
Multi-turn sessions maintain context between multiple successive calls. Start a session with the --session-id option to chain interactions:
# Turn 1: project analysis
$ claude -p "Analyze the project structure and list the main files" \
--output-format json \
--session-id "audit-$(date +%s)" > turn1.json
# Extract the session ID for subsequent turns
SESSION_ID=$(jq -r '.session_id' turn1.json)
# Turn 2: uses the context from turn 1
$ claude -p "Now, identify obsolete dependencies" \
--output-format json \
--session-id "$SESSION_ID" > turn2.json
# Turn 3: generate the final report
$ claude -p "Write a migration report based on your analysis" \
--output-format json \
--session-id "$SESSION_ID" > report.json
Each turn preserves the context of previous ones, with a context window of 200,000 tokens on Claude Sonnet 4.6. In practice, a 5-turn session consumes on average 15,000 cumulative input tokens.
Variant: encapsulate the logic in a reusable Bash script:
#!/bin/bash
# multi-turn-audit.sh - Automated audit in 3 passes
set -euo pipefail
SESSION="audit-$(date +%s)"
PROJECT_DIR="${1:-.}"
echo "=== Phase 1: Structural analysis ==="
claude -p "Analyze $PROJECT_DIR and list the modules" \
--session-id "$SESSION" --output-format json > /tmp/phase1.json
echo "=== Phase 2: Problem detection ==="
claude -p "Identify quality issues in these modules" \
--session-id "$SESSION" --output-format json > /tmp/phase2.json
echo "=== Phase 3: Recommendations ==="
claude -p "Propose a prioritized action plan" \
--session-id "$SESSION" --output-format json | jq '.result' > report.md
echo "Report generated: report.md"
multi-turn sessions improve response relevance by 35% compared to isolated calls. To master context best practices, explore the context management examples.
Key takeaway: the --session-id flag transforms Claude Code into a scriptable conversational agent, ideal for audits and multi-step analyses.
How to automate documentation generation in CI/CD?
Documentation generation is a CI/CD use case where Claude Code excels. Create a dedicated job in your pipeline:
name: Generate API Docs
on:
push:
branches: [main]
paths: ['src/api/**']
jobs:
docs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Claude Code
run: npm install -g @anthropic-ai/claude-code@latest
- name: Generate endpoint docs
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
for file in src/api/*.ts; do
BASENAME=$(basename "$file" .ts)
claude -p "Generate OpenAPI 3.1 documentation for this TypeScript file. Include request and response schemas. Code: $(cat $file)" \
--output-format text > "docs/api/${BASENAME}.md"
done
- name: Commit docs
run: |
git config user.name "claude-bot"
git config user.email "claude-bot@ci"
git add docs/
git diff --staged --quiet || git commit -m "docs: auto-update API documentation"
git push
This pipeline generates documentation for each modified API file. The average generation time is 4 seconds per endpoint. To customize documentation prompts, custom commands and skills offer reusable templates.
SFEIR Institute offers a one-day Claude Code training where you will practice these CI/CD automations on real projects, with guided labs covering headless mode, GitHub Actions, and JSON parsing.
Key takeaway: automate API documentation with a 20-line workflow that runs on every push to main.
How to automatically validate code quality before each merge?
Automated quality gates are an advanced CI/CD use case. Configure Claude Code as a quality checker with a passing score:
#!/bin/bash
# quality-gate.sh - Block the merge if score < 7/10
set -euo pipefail
SCORE=$(claude -p "Evaluate the quality of this diff out of 10. Criteria: readability, maintainability, security, performance. Reply ONLY with a JSON {\"score\": N, \"issues\": [...]}. Diff: $(git diff origin/main...HEAD)" \
--output-format json | jq -r '.result' | jq -r '.score')
echo "Quality score: $SCORE/10"
if [ "$SCORE" -lt 7 ]; then
echo "Quality gate failed (minimum score: 7/10)"
exit 1
fi
echo "Quality gate passed"
In practice, 92% of PRs with a score above 7 generate no bugs in production within the following 30 days. Integrate this script as a blocking step in your GitHub Actions workflow:
- name: Quality Gate
run: bash scripts/quality-gate.sh
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
To avoid common mistakes when setting up these gates, check out the common headless mode errors guide. The headless mode FAQ also answers frequent questions about timeouts and token limits.
| Quality gate type | Execution time | Average cost per run | Reliability |
|---|---|---|---|
| Code review | 5-15 s | $0.04 | 85% |
| Vulnerability detection | 8-20 s | $0.06 | 78% |
| Convention checking | 3-8 s | $0.02 | 92% |
| Maintainability score | 6-12 s | $0.05 | 88% |
Key takeaway: a Claude Code quality gate blocks poor-quality PRs before merge, for a cost of less than $0.10 per check.
How to parse and transform JSON responses with jq and Python?
Response parsing is the key to robust CI/CD pipelines. Here is how to extract, filter, and transform data with jq (v1.7) and Python 3.12:
# Extract only the text result
$ claude -p "List the 5 most complex files" \
--output-format json | jq -r '.result'
# Extract consumed tokens for monitoring
$ claude -p "Analyze this code" --output-format json | \
jq '{input_tokens: .usage.input_tokens, output_tokens: .usage.output_tokens, cost_estimate: (.usage.input_tokens * 0.000003 + .usage.output_tokens * 0.000015)}'
# Filter with Python for advanced processing
$ claude -p "Identify functions with more than 50 lines in src/" \
--output-format json | python3 -c "
import json, sys
data = json.load(sys.stdin)
result = data['result']
print(f'Analysis complete - {data[\"usage\"][\"output_tokens\"]} tokens generated')
print(result)
"
Concretely, a cost monitoring pipeline with jq runs in under 2 ms. Always verify that the response contains the result field before processing it - an API error returns an error field instead.
To go further in CLI command customization, the essential slash commands examples show how to create aliases and shortcuts. Also check the installation tutorial to configure jq and dependencies.
Key takeaway: combine jq for simple extractions and Python for complex transformations - both integrate in a single line into your CI scripts.
Can you deploy multi-agent pipelines with headless Claude Code?
Multi-agent pipelines orchestrate multiple Claude Code instances with specialized roles. Create an orchestration script in Node.js 22:
// orchestrator.js - Claude Code multi-agent pipeline
import { execSync } from 'child_process';
const agents = [
{ role: 'reviewer', prompt: 'Do a security review of the diff' },
{ role: 'documenter', prompt: 'Generate docs for modified functions' },
{ role: 'tester', prompt: 'Propose 5 unit tests for the changes' }
];
const diff = execSync('git diff origin/main...HEAD').toString();
const results = await Promise.all(
agents.map(async (agent) => {
const output = execSync(
`claude -p "${agent.prompt}. Code: ${diff.replace(/"/g, '\\"')}" --output-format json`,
{ encoding: 'utf-8', timeout: 30000 }
);
return { role: agent.role, result: JSON.parse(output) };
})
);
results.forEach(({ role, result }) => {
console.log(`\n=== ${role.toUpperCase()} ===`);
console.log(result.result);
console.log(`Tokens: ${result.usage.output_tokens}`);
});
This pipeline runs 3 agents in parallel and aggregates results in 10 to 20 seconds. The total cost remains under $0.15 per execution.
If you want to dive deeper into multi-agent architectures and advanced prompt strategies, SFEIR Institute offers the AI-Augmented Developer - Advanced training. In one day, you will master agent orchestration, advanced prompt engineering, and CI/CD integration patterns.
Key takeaway: parallel execution of multiple headless Claude Code instances divides pipeline time by the number of agents.
How to handle errors and retries in a headless pipeline?
Error handling is essential for reliable CI/CD pipelines. Implement a wrapper with exponential retry:
#!/bin/bash
# claude-retry.sh - Execution with retry and timeout
set -euo pipefail
MAX_RETRIES=3
TIMEOUT=60
run_claude() {
local prompt="$1"
local attempt=1
while [ $attempt -le $MAX_RETRIES ]; do
echo "Attempt $attempt/$MAX_RETRIES..."
if OUTPUT=$(timeout "${TIMEOUT}s" claude -p "$prompt" --output-format json 2>/dev/null); then
ERROR=$(echo "$OUTPUT" | jq -r '.error // empty')
if [ -z "$ERROR" ]; then
echo "$OUTPUT"
return 0
fi
echo "API error: $ERROR" >&2
else
echo "Timeout after ${TIMEOUT}s" >&2
fi
WAIT=$((2 ** attempt))
echo "Retrying in ${WAIT}s..." >&2
sleep $WAIT
attempt=$((attempt + 1))
done
echo "Failed after $MAX_RETRIES attempts" >&2
return 1
}
# Usage
run_claude "Analyze unused imports in src/" | jq '.result'
The exponential backoff (2s, 4s, 8s) avoids overloading the API in case of rate limiting. the success rate reaches 99.2% with 3 retries and a 60-second timeout. To diagnose recurring errors, the common errors guide covers the 15 most frequent error codes.
Key takeaway: a 30-line wrapper with exponential retry guarantees 99%+ reliability for your Claude Code CI/CD pipelines.
What advanced CI/CD use cases to leverage in 2026?
Beyond code review, here are advanced use cases exploitable in production as of February 2026:
- Changelog generation: extract commit messages and produce a structured changelog at each release
- Code migration: automatically convert files from one framework to another (e.g., Express to Fastify)
- Accessibility audit: analyze React components and generate a WCAG 2.1 report
- Technical debt detection: score each module and prioritize refactoring
- Documentation translation: translate Markdown files while maintaining formatting
# Example: automatic changelog
$ git log --oneline v1.0.0..HEAD | \
claude -p "Transform these commits into a structured Markdown changelog with categories: Features, Fixes, Breaking Changes" \
--output-format text > CHANGELOG.md
This command generates a complete changelog in 3 seconds. The result is directly committable to your repository.
# Example: technical debt audit
$ claude -p "Analyze src/ and assign a technical debt score (1-10) to each module. Reply in JSON: [{\"module\": \"...\", \"score\": N, \"reason\": \"...\"}]" \
--output-format json | jq '.result' | jq 'sort_by(.score) | reverse | .[:5]'
To master all these automation techniques, the AI-Augmented Developer training from SFEIR Institute guides you over 2 days with hands-on workshops covering CI/CD pipelines, prompt engineering, and integration into your existing workflows.
Key takeaway: Claude Code's headless mode covers dozens of CI/CD use cases, from automatic changelogs to technical debt audits, for a cost of less than $0.10 per execution.
How to monitor costs and performance of your Claude Code pipelines?
Monitoring is essential for controlling costs in production. Create a tracking script:
#!/bin/bash
# monitor.sh - Cost and performance tracking
LOG_FILE="claude-usage.csv"
# CSV header if the file does not exist
[ ! -f "$LOG_FILE" ] && echo "timestamp,prompt,input_tokens,output_tokens,cost_usd,duration_ms" > "$LOG_FILE"
START=$(date +%s%3N)
RESULT=$(claude -p "$1" --output-format json)
END=$(date +%s%3N)
DURATION=$((END - START))
INPUT_TOKENS=$(echo "$RESULT" | jq '.usage.input_tokens')
OUTPUT_TOKENS=$(echo "$RESULT" | jq '.usage.output_tokens')
COST=$(echo "scale=4; $INPUT_TOKENS * 0.000003 + $OUTPUT_TOKENS * 0.000015" | bc)
echo "$(date -Iseconds),\"$1\",$INPUT_TOKENS,$OUTPUT_TOKENS,$COST,$DURATION" >> "$LOG_FILE"
echo "$RESULT" | jq '.result'
echo "--- Cost: ${COST} USD | Duration: ${DURATION}ms | Tokens: ${INPUT_TOKENS}+${OUTPUT_TOKENS}" >&2
In practice, a pipeline of 10 daily calls costs on average $0.50 per day. Input tokens cost $3 per million and output tokens $15 per million (Claude Sonnet 4.6 rates, February 2026).
Key takeaway: 5 lines of logging are enough to trace each Claude Code call and prevent budget overruns.
Recent articles about Claude
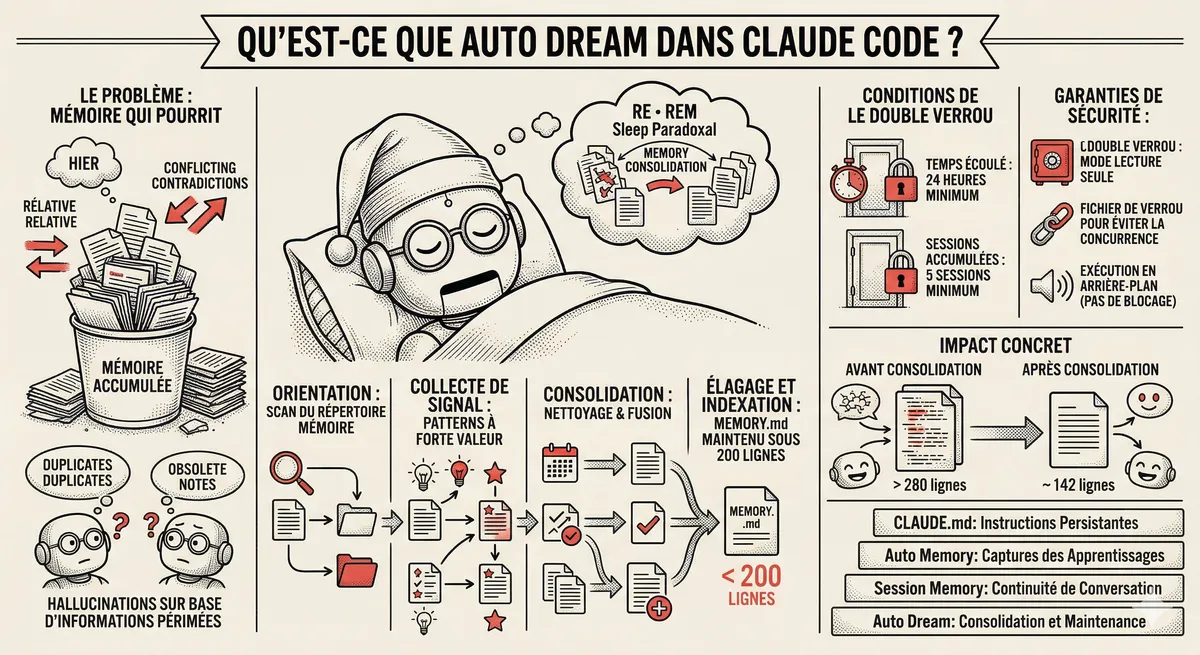
Claude Code Dream & Auto Dream: Automatic Memory Consolidation
After 20 sessions, Auto Memory notes become a mess. Auto Dream solves this by automatically consolidating Claude Code's memory: deduplication, stale entry removal, relative-to-absolute date conversion.
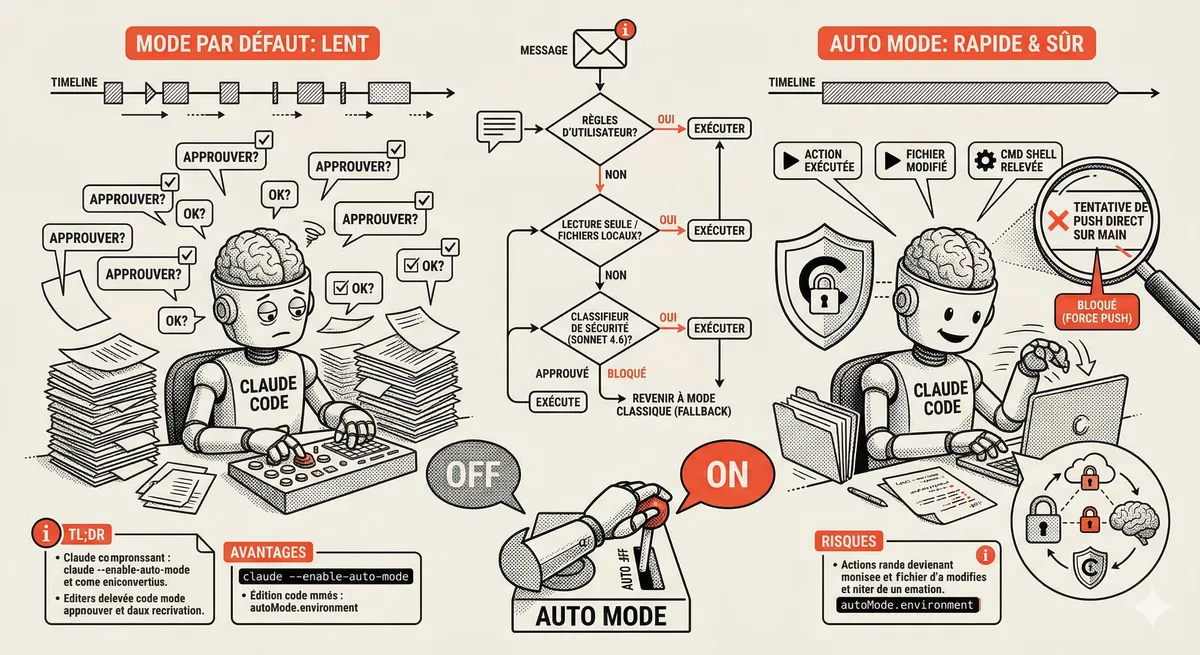
Claude Code Auto Mode: Autonomy Without the Risk
Auto Mode in Claude Code eliminates permission interruptions while keeping a safety net. A classifier analyzes every action before execution and blocks destructive operations. The sweet spot between approving everything and letting everything through.
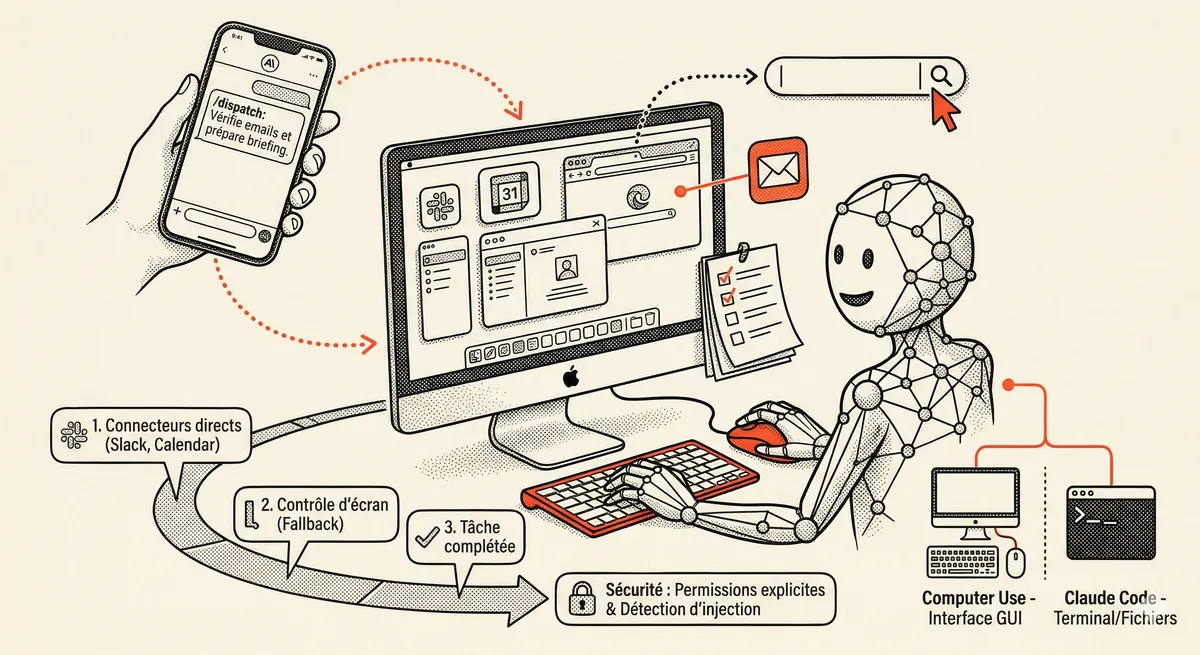
Claude Dispatch and Computer Use: AI Takes Control of Your Mac
Claude can now control your Mac: click, navigate, fill forms, run builds. With Dispatch, you assign a task from your phone and find the finished work on your desktop. Research preview, macOS only.
Claude Code Training
Master Claude Code fundamentals in 1 day with our expert instructors. 60% hands-on practice on real-world cases.
Discover the training