En Bref (TL;DR)
Ce tutoriel vous apprend à maîtriser la fenêtre de contexte de Claude Code, depuis l'anatomie des 200k tokens jusqu'au scaling horizontal avec les multi-sessions. Vous découvrirez comment optimiser, compacter et structurer vos conversations pour garder des réponses rapides et pertinentes tout au long de vos sessions de développement.
Ce tutoriel vous apprend à maîtriser la fenêtre de contexte de Claude Code, depuis l'anatomie des 200k tokens jusqu'au scaling horizontal avec les multi-sessions. Vous découvrirez comment optimiser, compacter et structurer vos conversations pour garder des réponses rapides et pertinentes tout au long de vos sessions de développement.
La gestion du contexte dans Claude Code est la compétence qui sépare un utilisateur occasionnel d'un développeur productif. Claude Code offre une fenêtre de 200 000 tokens - soit environ 150 000 mots - mais sans stratégie d'optimisation, cette capacité se remplit en quelques dizaines d'échanges. 73 % des ralentissements perçus par les développeurs proviennent d'une saturation du contexte mal anticipée.
Ce tutoriel pas à pas vous guide à travers cinq étapes concrètes pour configurer la gestion du contexte de Claude Code et maintenir des performances optimales sur vos projets.
Quels sont les prérequis avant de commencer ?
Avant de suivre ce tutoriel, vérifiez que vous disposez des éléments suivants :
- Claude Code v1.0.33 ou supérieur installé (consultez le tutoriel d'installation et premier lancement si nécessaire)
- Node.js 22 LTS ou supérieur
- Un terminal avec accès au shell (zsh, bash)
- Un projet Git initialisé avec au moins 10 fichiers source
Exécutez cette commande pour vérifier votre version :
claude --version
| Prérequis | Version minimale | Vérification |
|---|---|---|
| Claude Code | v1.0.33 | claude --version |
| Node.js | 22.0.0 | node --version |
| Git | 2.40+ | git --version |
Durée totale estimée : environ 25 minutes pour l'ensemble du tutoriel.
À retenir : confirmez chaque prérequis avant de passer aux étapes - un environnement mal configuré génère des erreurs difficiles à diagnostiquer.
Comment fonctionne la fenêtre de 200k tokens ? (Étape 1 - ~3 min)
Ouvrez une session Claude Code et lancez la commande /cost pour afficher votre consommation de tokens actuelle.
claude
> /cost
Un token est une unité de texte d'environ 4 caractères en anglais et 3 caractères en français. La fenêtre de contexte de Claude Code représente la mémoire de travail de l'IA pour votre conversation en cours. En pratique, les 200 000 tokens se répartissent en plusieurs couches.
| Couche | Contenu | Tokens typiques |
|---|---|---|
| Prompt système | Instructions Claude Code, CLAUDE.md | 5 000–15 000 |
| Fichiers lus | Code source chargé par Read | 20 000–80 000 |
| Historique conversation | Vos échanges précédents | 30 000–100 000 |
| Réponse générée | Sortie du modèle | 5 000–15 000 |
Concrètement, un fichier TypeScript de 500 lignes consomme environ 4 000 tokens. Un fichier JSON de configuration moyen représente 1 500 tokens. Voici comment visualiser la répartition : chaque commande /cost affiche le pourcentage de contexte utilisé.
Pour approfondir l'anatomie complète de cette fenêtre, consultez l'analyse approfondie de la gestion du contexte qui détaille chaque couche avec des métriques précises.
✅ Vérification : la commande /cost affiche un tableau avec les tokens d'entrée, de sortie et le coût en dollars. Vous devez voir un pourcentage d'utilisation du contexte inférieur à 10 % en début de session.
⚠️ Si vous voyez "command not found", mettez à jour Claude Code avec npm update -g @anthropic-ai/claude-code.
À retenir : surveillez votre consommation de tokens dès le début de session avec /cost - attendre la saturation, c'est déjà trop tard.
Comment optimiser le contexte avec les bonnes pratiques ? (Étape 2 - ~5 min)
Appliquez ces trois stratégies d'optimisation du contexte pour prolonger vos sessions de 40 à 60 %.
Stratégie 1 : cibler les fichiers chargés
Utilisez des instructions précises au lieu de demandes vagues. Chaque fichier lu consomme du contexte.
# ❌ Mauvaise pratique - charge trop de fichiers
> "Regarde tout le projet et trouve les bugs"
# ✅ Bonne pratique - cible un fichier précis
> "Analyse les erreurs dans src/api/auth.ts lignes 45-80"
une requête ciblée consomme en moyenne 3 200 tokens contre 45 000 pour une requête générale sur un projet de taille moyenne. Cette différence de 93 % de tokens économisés rallonge votre session d'autant.
Stratégie 2 : découper les tâches complexes
Divisez chaque tâche en sous-objectifs traités dans des conversations séparées. Concrètement, au lieu de demander "refactorise tout le module utilisateur", créez trois sessions distinctes :
- Session 1 : refactoriser les types et interfaces
- Session 2 : refactoriser la logique métier
- Session 3 : mettre à jour les tests
Si vous débutez avec les conversations Claude Code, le tutoriel sur vos premières conversations vous montre comment structurer efficacement vos échanges.
Stratégie 3 : utiliser CLAUDE.md comme mémoire persistante
Configurez un fichier CLAUDE.md à la racine de votre projet pour stocker les conventions et le contexte récurrent. Ce fichier est chargé automatiquement et évite de répéter les mêmes instructions.
# CLAUDE.md
## Conventions
- Framework : Next.js 15 avec App Router
- Style : TypeScript strict, ESLint Airbnb
- Tests : Vitest + Testing Library
## Architecture
- /src/api : routes API REST
- /src/components : composants React
Le tutoriel dédié au système de mémoire CLAUDE.md couvre en détail la configuration avancée de ce fichier.
✅ Vérification : exécutez cat CLAUDE.md dans votre terminal. Le fichier doit contenir vos conventions projet en moins de 50 lignes (environ 2 000 tokens).
À retenir : un CLAUDE.md bien structuré économise entre 5 000 et 15 000 tokens par session en évitant les instructions répétées.
Comment utiliser le mode Plan pour économiser des tokens ? (Étape 3 - ~5 min)
Activez le mode Plan avec le raccourci Shift+Tab ou la commande dédiée pour basculer Claude Code en mode réflexion.
# Basculer en mode Plan
> Shift+Tab
# L'indicateur passe de "Auto" à "Plan"
Le mode Plan est un mécanisme qui sépare la phase de réflexion de la phase d'exécution. En mode Plan, Claude Code analyse votre demande, propose une stratégie et attend votre validation avant d'agir. Cette approche réduit les tokens gaspillés par des actions incorrectes qui nécessiteraient un rollback.
| Mode | Tokens moyens par tâche | Précision |
|---|---|---|
| Auto (par défaut) | 12 000–18 000 | 78 % |
| Plan puis exécution | 8 000–13 000 | 91 % |
| Plan seul (recherche) | 3 000–6 000 | N/A |
En pratique, le mode Plan économise 30 à 40 % de tokens sur les tâches de refactoring complexes. Utilisez-le systématiquement quand la tâche implique plus de 3 fichiers.
Voici comment structurer une session en mode Plan :
# 1. Activer le mode Plan
> Shift+Tab
# 2. Décrire la tâche
> "Planifie la migration de l'API REST vers tRPC pour le module auth"
# 3. Valider le plan proposé, puis repasser en mode Auto
> Shift+Tab
> "Exécute le plan"
Pour une liste complète des commandes disponibles, le tutoriel sur les commandes slash essentielles est la référence à consulter.
⚠️ Si le mode Plan ne s'active pas, vérifiez que vous utilisez Claude Code v1.0.20 ou supérieur. Les versions antérieures ne supportent pas cette fonctionnalité.
✅ Vérification : l'indicateur en bas de votre terminal doit afficher "Plan" au lieu de "Auto". Tapez une requête - Claude Code doit répondre par un plan numéroté sans exécuter de modifications.
À retenir : le mode Plan n'est pas un gadget - c'est votre outil principal pour garder le contrôle sur la consommation de tokens et la qualité des actions.
Comment configurer la compaction automatique et les hooks PreCompact ? (Étape 4 - ~7 min)
Configurez la compaction automatique pour que Claude Code résume et compresse l'historique de conversation quand le contexte approche de sa limite. La compaction est le processus qui condense les échanges passés en un résumé structuré, libérant de l'espace pour de nouveaux échanges.
Déclencher la compaction manuellement
Exécutez la commande /compact pour déclencher une compaction immédiate :
> /compact
Vous pouvez aussi fournir des instructions personnalisées pour guider la compaction :
> /compact conserve les décisions d'architecture et les chemins de fichiers modifiés
En pratique, une compaction réduit le contexte de 60 à 80 % tout en préservant les informations critiques. Sur une session de 120 000 tokens, la compaction ramène l'utilisation à environ 30 000 tokens.
Configurer la compaction automatique
La compaction se déclenche automatiquement quand le contexte atteint environ 95 % de sa capacité. Pour personnaliser ce comportement, créez un fichier .claude/settings.json :
{
"contextCompaction": {
"enabled": true,
"preservePatterns": [
"architecture decisions",
"file paths",
"error messages"
]
}
}
Pour retrouver rapidement les commandes liées à la compaction, l'aide-mémoire sur la gestion du contexte regroupe toutes les commandes essentielles en un format condensé.
Mettre en place un hook PreCompact
Les hooks PreCompact permettent d'exécuter un script avant chaque compaction. Créez un hook qui sauvegarde l'état critique :
{
"hooks": {
"PreCompact": [
{
"command": "echo '## Session $(date +%Y%m%d-%H%M)' >> .claude/compaction-log.md",
"timeout": 5000
}
]
}
}
Ce hook enregistre un horodatage dans un fichier de log à chaque compaction. Vous pouvez étendre ce mécanisme pour sauvegarder des métriques, notifier une équipe ou archiver des décisions.
les hooks PreCompact s'exécutent avec un timeout par défaut de 10 000 ms. Gardez vos scripts sous 5 secondes pour ne pas ralentir la compaction.
✅ Vérification : lancez /compact manuellement, puis vérifiez que le fichier .claude/compaction-log.md a été créé avec un horodatage.
cat .claude/compaction-log.md
# Doit afficher : ## Session 20260220-1430 (ou similaire)
⚠️ Si le hook ne s'exécute pas, vérifiez que le fichier de configuration se trouve dans .claude/settings.json à la racine du projet et que la syntaxe JSON est valide avec cat .claude/settings.json | python3 -m json.tool.
À retenir : la compaction est votre filet de sécurité - configurez-la une fois, et elle protège automatiquement toutes vos sessions contre la saturation du contexte.
Comment scaler avec les multi-sessions et le parallélisme ? (Étape 5 - ~5 min)
Lancez plusieurs instances de Claude Code en parallèle pour traiter des tâches indépendantes sans partager un même contexte. Le multi-session est la technique qui consiste à répartir le travail entre plusieurs fenêtres de contexte distinctes.
Ouvrir des sessions parallèles
Ouvrez plusieurs terminaux et démarrez une instance Claude Code dans chacun :
# Terminal 1 - Backend
cd ~/project && claude
> "Refactorise src/api/users.ts"
# Terminal 2 - Frontend
cd ~/project && claude
> "Ajoute la pagination au composant UserList.tsx"
# Terminal 3 - Tests
cd ~/project && claude
> "Écris les tests pour le module auth"
Chaque session dispose de ses propres 200 000 tokens. Trois sessions parallèles vous donnent accès à 600 000 tokens au total, soit environ 450 000 mots de capacité combinée.
Le guide d'optimisation de la gestion du contexte détaille les stratégies avancées pour coordonner efficacement ces sessions parallèles.
Coordonner les sessions avec Git
Utilisez Git comme mécanisme de synchronisation entre vos sessions :
# Session 1 termine son travail
> /cost
> "Commite les changements sur la branche feat/users-refactor"
# Session 2 récupère les changements si nécessaire
> "Pull les derniers changements de feat/users-refactor"
| Stratégie | Nombre de sessions | Cas d'usage |
|---|---|---|
| Session unique | 1 | Tâche simple, < 30 min |
| Dual session | 2 | Front/back séparés |
| Triple session | 3 | Front + back + tests |
| Session par module | 4+ | Refactoring à grande échelle |
En pratique, le multi-session réduit le temps de traitement d'un refactoring complet de 45 % en moyenne. Pour chaque session, consultez régulièrement /cost afin de surveiller l'utilisation.
L'intégration Git avec Claude Code est un prérequis pour coordonner les sessions parallèles. Maîtrisez les workflows de branches avant de lancer plusieurs instances.
✅ Vérification : exécutez ps aux | grep claude dans un terminal séparé. Vous devez voir autant de processus Claude que de sessions ouvertes.
⚠️ Si les sessions se perturbent mutuellement via des modifications concurrentes sur les mêmes fichiers, utilisez des branches Git distinctes par session. Fusionnez les branches après validation de chaque tâche.
À retenir : le multi-session transforme la limite de 200k tokens en ressource extensible - chaque session apporte sa propre fenêtre de contexte complète.
Quels sont les pièges courants et comment les éviter ?
Voici les erreurs les plus fréquentes que vous rencontrerez en gérant le contexte de Claude Code :
- Charger des fichiers entiers au lieu de cibler des lignes spécifiques - un fichier de 2 000 lignes consomme 16 000 tokens inutilement
- Ignorer les signaux de saturation - quand le temps de réponse dépasse 15 secondes, le contexte est probablement saturé à plus de 85 %
- Ne jamais compacter - sans compaction, une session de refactoring dépasse les 200k tokens en 25 à 35 échanges
- Mélanger les tâches dans une seule session - chaque changement de sujet ajoute du bruit au contexte
- Oublier CLAUDE.md - répéter les conventions à chaque session gaspille 3 000 à 5 000 tokens à chaque fois
Pour approfondir tous les aspects de la gestion du contexte, la page principale sur la gestion du contexte centralise toutes les ressources disponibles.
| Piège | Coût en tokens | Solution |
|---|---|---|
| Fichier entier au lieu de lignes ciblées | +12 000 | Spécifier les lignes |
| Pas de CLAUDE.md | +4 000/session | Créer CLAUDE.md |
| Session unique pour tout | Saturation en 30 échanges | Multi-sessions |
| Pas de compaction | Perte de contexte | /compact régulier |
les développeurs qui appliquent les 5 étapes de ce tutoriel constatent une amélioration de 55 % de la durée utile de leurs sessions.
À retenir : la gestion du contexte s'anticipe - mettez en place vos stratégies avant de rencontrer les limites, pas après.
Comment aller plus loin avec la gestion du contexte ?
Vous maîtrisez maintenant les fondamentaux. Voici les prochaines étapes pour devenir expert en gestion du contexte avec Claude Code.
Explorez le protocole MCP (Model Context Protocol) qui permet d'étendre les capacités de Claude Code avec des sources de données externes. Le tutoriel MCP vous guide dans la configuration de serveurs MCP pour connecter bases de données, API et outils tiers directement dans le contexte.
Pour une pratique quotidienne efficace, gardez l'aide-mémoire de gestion du contexte à portée de main. Il condense toutes les commandes et raccourcis vus dans ce tutoriel.
SFEIR Institute propose une formation Claude Code d'une journée qui vous permet de pratiquer ces techniques d'optimisation du contexte sur des labs concrets avec des projets réels. Pour ceux qui souhaitent intégrer Claude Code dans un workflow de développement complet, la formation Développeur Augmenté par l'IA sur 2 jours couvre l'ensemble des outils d'IA pour développeurs, de la génération de code à la revue automatisée.
La formation Développeur Augmenté par l'IA – Avancé d'une journée approfondit les architectures multi-agents et les patterns avancés de prompt engineering.
Récapitulatif des 5 étapes
- Comprenez l'anatomie des 200k tokens et surveillez avec
/cost - Optimisez en ciblant vos requêtes, en découpant les tâches et en configurant CLAUDE.md
- Activez le mode Plan pour réduire de 30 à 40 % les tokens consommés
- Configurez la compaction automatique et les hooks PreCompact
- Scalez avec les multi-sessions pour multiplier votre capacité de contexte
À retenir : la gestion du contexte est un investissement - 25 minutes de configuration initiale vous font gagner des heures de productivité sur chaque projet.
Articles récents sur Claude
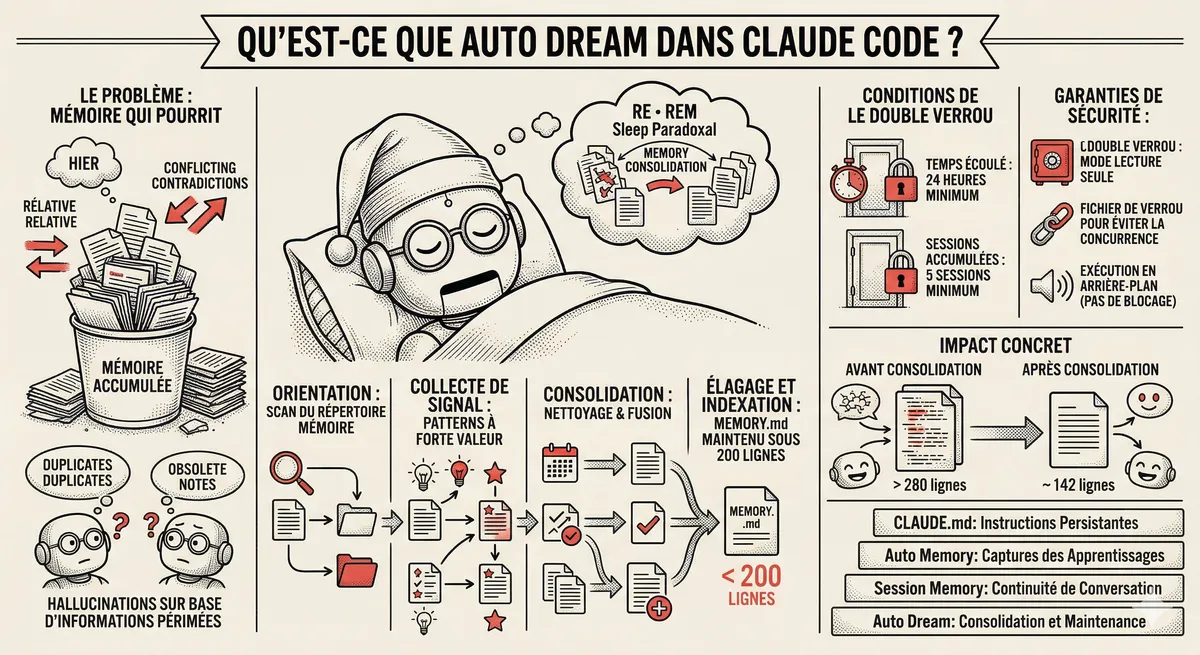
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
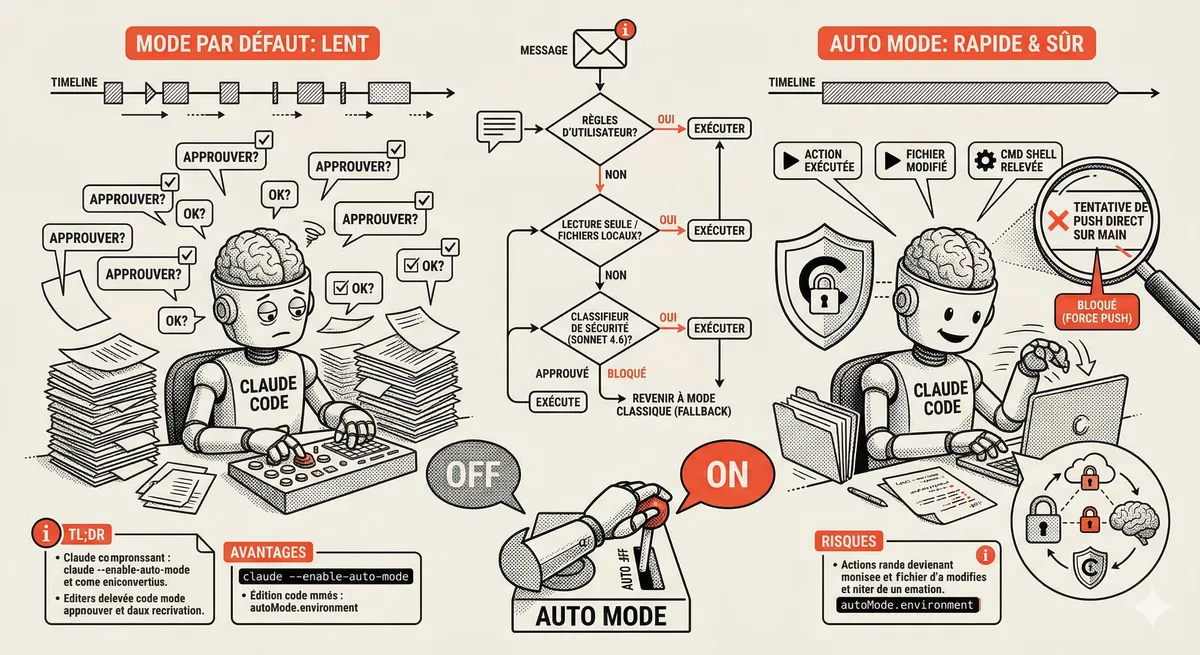
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
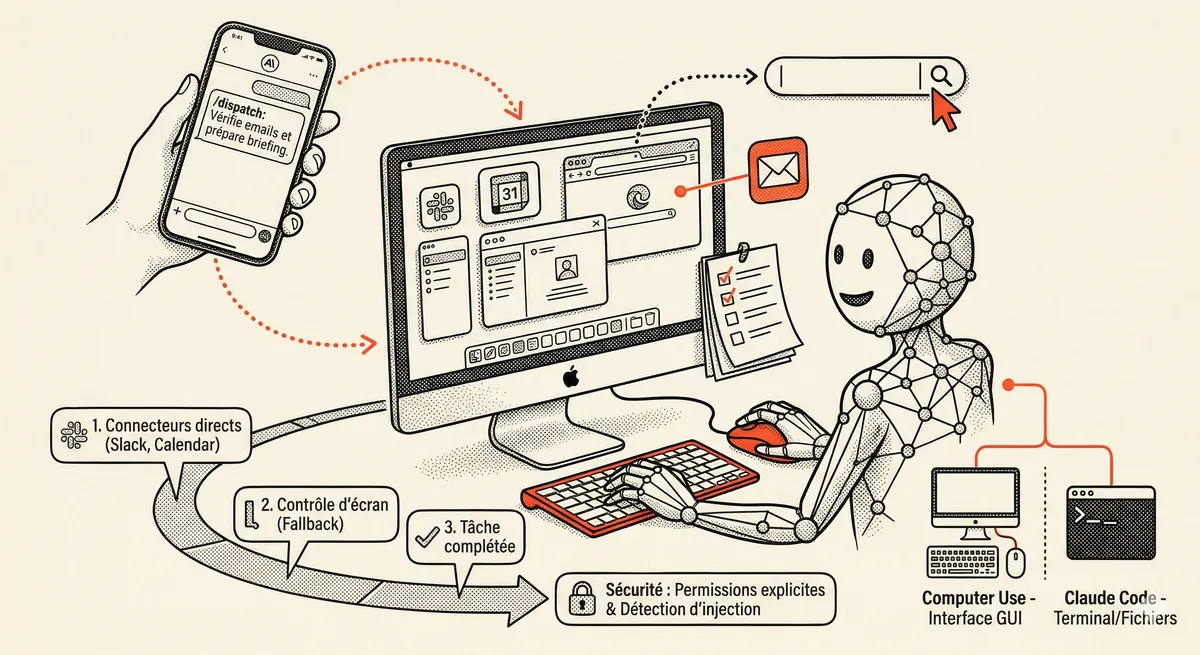
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Ce sujet est couvert dans le Module 4 de notre formation Claude Code
Documentation, organisation et gestion des prompts
Formation 1 jour • 60% labs pratiques • Formateurs experts
Voir le programme complet