En Bref (TL;DR)
La gestion du contexte dans Claude Code détermine la qualité de chaque réponse générée. Maîtriser la fenêtre de 200 000 tokens, la compaction automatique et le mode Plan vous permet de réduire vos coûts de 40 à 60 % tout en obtenant des résultats plus précis. Voici les réponses aux questions les plus fréquentes pour optimiser votre utilisation du contexte.
La gestion du contexte dans Claude Code détermine la qualité de chaque réponse générée. Maîtriser la fenêtre de 200 000 tokens, la compaction automatique et le mode Plan vous permet de réduire vos coûts de 40 à 60 % tout en obtenant des résultats plus précis. Voici les réponses aux questions les plus fréquentes pour optimiser votre utilisation du contexte.
La gestion du contexte dans Claude Code est l'ensemble des techniques permettant de contrôler quelles informations l'agent reçoit dans sa fenêtre de tokens pour produire des réponses pertinentes. Claude Code exploite une fenêtre de 200 000 tokens - soit environ 150 000 mots - ce qui en fait l'un des contextes les plus larges disponibles pour un outil de coding agentique.
cette capacité a doublé par rapport aux premières versions du modèle Claude 3.
Comment fonctionne la fenêtre de contexte de 200 000 tokens dans Claude Code ?
La fenêtre de contexte est la mémoire de travail que Claude Code utilise pour chaque conversation. Elle contient l'ensemble des messages, fichiers lus et résultats d'outils accumulés pendant votre session.
Visualisez cette fenêtre comme un budget fixe de 200 000 tokens. Chaque action consomme une partie de ce budget : un fichier de 500 lignes représente environ 4 000 tokens, une réponse longue entre 1 000 et 3 000 tokens.
En pratique, 80 % du contexte est consommé par les lectures de fichiers et les résultats d'outils, et seulement 20 % par vos messages et les réponses de l'agent.
| Élément | Consommation moyenne | Part du contexte |
|---|---|---|
| Fichier source (500 lignes) | 4 000 tokens | 2 % |
| Résultat d'une commande bash | 1 500 tokens | 0,75 % |
| Message utilisateur moyen | 200 tokens | 0,1 % |
| Réponse de l'agent | 1 500 tokens | 0,75 % |
| Fichier CLAUDE.md chargé | 800 tokens | 0,4 % |
Pour comprendre les bases de l'interaction avec Claude Code, consultez la FAQ sur vos premières conversations qui couvre les fondamentaux.
À retenir : la fenêtre de 200 000 tokens est un budget partagé entre vos messages, les fichiers lus et les résultats d'outils - surveillez votre consommation.
Comment savoir combien de tokens il reste dans ma session ?
Exécutez la commande /cost dans Claude Code pour afficher votre consommation en temps réel. Cette commande affiche le nombre de tokens utilisés et le coût estimé de la session.
# Afficher la consommation de tokens et le coût
$ claude
> /cost
L'indicateur de contexte apparaît aussi dans la barre de statut de Claude Code. Quand il dépasse 80 %, un avertissement vous signale que la compaction automatique approche.
Concrètement, une session typique de développement consomme entre 50 000 et 120 000 tokens avant de déclencher la compaction. Les commandes slash essentielles incluent /cost et /compact parmi les outils de diagnostic indispensables.
À retenir : utilisez /cost régulièrement pour anticiper la compaction et garder le contrôle sur votre budget de tokens.
Quelles stratégies permettent d'optimiser le contexte au quotidien ?
Adoptez trois pratiques clés : limitez les fichiers lus, découpez vos tâches et utilisez des instructions ciblées dans CLAUDE.md. Ces trois leviers réduisent la consommation de tokens de 40 % en moyenne.
Précisez les fichiers à lire plutôt que de laisser l'agent explorer tout le projet. Un prompt comme « Lis uniquement src/auth/login.ts et corrige le bug ligne 42 » consomme 10 fois moins de contexte qu'un prompt vague.
# Mauvaise pratique : exploration large
$ claude "Trouve et corrige les bugs dans le projet"
# Bonne pratique : ciblage précis
$ claude "Lis src/auth/login.ts et corrige l'erreur TypeError ligne 42"
| Stratégie | Économie de tokens | Difficulté |
|---|---|---|
| Cibler les fichiers explicitement | 30-50 % | Facile |
| Découper en sous-tâches | 20-40 % | Moyenne |
| Utiliser le mode Plan | 40-60 % | Facile |
| Configurer CLAUDE.md | 10-20 % | Facile |
Utiliser /compact manuellement | 50-70 % | Facile |
Le guide complet de gestion du contexte détaille chaque stratégie avec des exemples concrets adaptés à différents types de projets.
À retenir : cibler les fichiers, découper les tâches et configurer CLAUDE.md sont les trois piliers d'une gestion de contexte efficace.
Comment le mode Plan permet-il d'économiser des tokens ?
Le mode Plan consomme uniquement des tokens d'entrée, sans générer d'appels d'outils coûteux. Activez-le avec le raccourci Shift+Tab ou la commande /plan pour que Claude Code analyse sans agir.
En mode Plan, l'agent lit votre codebase, propose une stratégie et attend votre validation avant d'exécuter quoi que ce soit. ce mode réduit la consommation totale de tokens de 40 à 60 % sur les tâches complexes.
# Activer le mode Plan
$ claude
> Shift+Tab # Bascule en mode Plan
> "Refactorise le module d'authentification pour utiliser JWT"
# Claude Code propose un plan sans exécuter d'actions
En pratique, le mode Plan est particulièrement utile pour les tâches de refactoring touchant plus de 5 fichiers. Il vous évite de consommer des tokens sur des explorations inutiles. Consultez le tutoriel dédié à la gestion du contexte pour apprendre à combiner le mode Plan avec d'autres techniques.
À retenir : le mode Plan vous fait économiser 40 à 60 % de tokens en séparant la phase de réflexion de la phase d'exécution.
Comment fonctionne la compaction automatique dans Claude Code ?
La compaction automatique se déclenche quand le contexte atteint environ 95 % de la fenêtre de 200 000 tokens. Claude Code résume alors les échanges précédents pour libérer de l'espace tout en conservant les informations essentielles.
Comprenez que la compaction n'est pas une perte de mémoire : l'agent conserve un résumé structuré des décisions prises, des fichiers modifiés et des erreurs rencontrées. En revanche, les détails fins comme les numéros de ligne exacts ou les blocs de code intermédiaires peuvent être perdus.
Vous pouvez aussi déclencher la compaction manuellement avec la commande /compact :
# Compaction manuelle avec instruction de résumé
$ claude
> /compact "Conserve uniquement les modifications sur auth/ et les tests"
Le paramètre optionnel après /compact guide le résumé. Spécifiez les éléments critiques à conserver pour que la compaction préserve ce qui compte pour votre tâche en cours.
Pour éviter les erreurs fréquentes liées à la compaction, lisez les erreurs courantes de gestion du contexte qui couvre les pièges à éviter.
À retenir : la compaction résume intelligemment votre session - déclenchez-la manuellement avec /compact pour garder le contrôle sur ce qui est conservé.
Quels sont les hooks PreCompact et comment les configurer ?
Les hooks PreCompact sont des scripts shell exécutés automatiquement juste avant chaque compaction. Configurez-les dans votre fichier .claude/settings.json pour sauvegarder l'état critique de votre session.
Un hook PreCompact typique sauvegarde le diff en cours, l'état git ou un résumé personnalisé dans un fichier temporaire que vous pourrez relire après la compaction.
{
"hooks": {
"PreCompact": [
{
"command": "git diff --stat > /tmp/claude-pre-compact-diff.txt",
"timeout": 5000
}
]
}
}
Concrètement, les hooks PreCompact résolvent un problème fréquent : perdre la trace des modifications non commitées après une compaction. En sauvegardant le diff avant compaction, vous créez un filet de sécurité.
| Hook | Objectif | Timeout recommandé |
|---|---|---|
git diff --stat | Sauvegarder le résumé des changements | 5 000 ms |
git stash list | Lister les stashs actifs | 3 000 ms |
| Script de résumé custom | Exporter le contexte critique | 10 000 ms |
Pour aller plus loin sur la configuration des hooks et des commandes slash, consultez la FAQ sur les commandes slash essentielles. Vous trouverez aussi des astuces avancées dans les astuces de gestion du contexte.
À retenir : configurez un hook PreCompact pour sauvegarder automatiquement votre diff git avant chaque compaction - c'est votre filet de sécurité.
Comment utiliser les multi-sessions pour scaler horizontalement ?
Lancez plusieurs instances de Claude Code en parallèle, chacune dédiée à une tâche spécifique, pour multiplier votre capacité de traitement sans saturer une seule fenêtre de contexte.
Le scaling horizontal consiste à répartir le travail sur plusieurs sessions indépendantes plutôt que de tout charger dans une seule fenêtre de 200 000 tokens. Chaque session dispose de son propre budget de tokens.
# Terminal 1 : refactoring du module auth
$ claude "Refactorise src/auth/ pour utiliser des tokens JWT"
# Terminal 2 : écriture des tests
$ claude "Écris les tests unitaires pour src/api/users.ts"
# Terminal 3 : documentation
$ claude "Génère la documentation JSDoc pour src/lib/"
En pratique, 3 sessions parallèles traitent un volume de travail équivalent à 600 000 tokens de contexte total. le scaling horizontal réduit le temps de complétion des tâches complexes de 55 % par rapport à une session unique.
Le fichier CLAUDE.md sert de mémoire partagée entre les sessions. Chaque instance le charge au démarrage, ce qui garantit la cohérence des conventions de code.
À retenir : répartissez les tâches indépendantes sur 2 à 4 sessions parallèles pour multiplier votre capacité sans compromettre la qualité du contexte.
Peut-on récupérer du contexte perdu après une compaction ?
Non, les tokens supprimés lors d'une compaction ne sont pas récupérables directement. Utilisez la commande /resume et les hooks PreCompact pour atténuer cette limitation.
La compaction est un processus destructif : le résumé remplace les échanges originaux. Cependant, trois mécanismes vous protègent. Le fichier CLAUDE.md persiste entre les sessions. Les hooks PreCompact sauvegardent l'état critique. Et la commande /resume permet de reprendre une session précédente avec son contexte résumé.
# Reprendre la dernière session
$ claude --resume
# Lister les sessions récentes
$ claude --list-sessions
Pour comprendre comment le système de mémoire CLAUDE.md complète la gestion du contexte, consultez la FAQ dédiée. Cette mémoire persistante survit aux compactions et aux changements de session.
À retenir : préparez-vous à la compaction avec des hooks et CLAUDE.md - une fois les tokens compactés, seul le résumé subsiste.
Quels fichiers consomment le plus de tokens et comment les identifier ?
Les fichiers générés (lock files, bundles, maps) consomment souvent plus de 50 000 tokens chacun. Ajoutez-les à votre .claudeignore pour les exclure automatiquement du contexte.
Un fichier package-lock.json typique représente 30 000 à 80 000 tokens. Un fichier bundle.js compilé peut dépasser 100 000 tokens - soit la moitié de votre fenêtre de contexte consommée par un seul fichier inutile.
# .claudeignore - fichiers à exclure du contexte
node_modules/
*.lock
dist/
build/
*.min.js
*.map
coverage/
| Type de fichier | Tokens moyens | Action recommandée |
|---|---|---|
| package-lock.json | 40 000 | .claudeignore |
| bundle.js | 80 000+ | .claudeignore |
| Fichier source (200 lignes) | 1 600 | Lire si nécessaire |
| Fichier test (150 lignes) | 1 200 | Lire si nécessaire |
| Fichier .env | 100 | Ne jamais exposer |
Pour comprendre ce qu'est le coding agentique et pourquoi la gestion des fichiers est centrale dans ce paradigme, consultez la FAQ dédiée.
À retenir : un .claudeignore bien configuré peut économiser 50 % de votre budget de tokens en excluant les fichiers générés.
Comment combiner CLAUDE.md et gestion du contexte pour des sessions productives ?
Rédigez un fichier CLAUDE.md concis (moins de 200 lignes) qui charge automatiquement les conventions critiques sans gaspiller de tokens. Ce fichier est la mémoire persistante de Claude Code entre les sessions.
CLAUDE.md est chargé au début de chaque session et consomme entre 500 et 2 000 tokens selon sa taille. Un fichier trop long gaspille du contexte. Un fichier trop court oblige l'agent à explorer le projet pour redécouvrir les conventions.
# CLAUDE.md - exemple optimisé (< 800 tokens)
## Stack
- Next.js 15, TypeScript 5.7, Tailwind CSS 4.0
## Conventions
- Tests avec Vitest, nommage : *.test.ts
- Commits conventionnels (feat:, fix:, chore:)
## Commandes
- npm run dev : serveur local
- npm run test : lancer les tests
SFEIR Institute propose une formation Claude Code d'une journée qui inclut un lab pratique sur la création d'un fichier CLAUDE.md optimisé et les techniques de gestion du contexte. Vous y apprendrez à configurer votre environnement pour maximiser la productivité de l'agent.
À retenir : gardez votre CLAUDE.md sous 200 lignes et 2 000 tokens pour charger les conventions essentielles sans gaspiller votre fenêtre de contexte.
Faut-il privilégier une longue session ou plusieurs courtes sessions ?
Privilégiez des sessions courtes et ciblées de 30 à 45 minutes pour maintenir un contexte propre et des réponses précises. Les sessions longues accumulent du bruit dans le contexte.
Une session de 2 heures atteint souvent 2 à 3 compactions, ce qui dilue progressivement la qualité du résumé. À l'inverse, des sessions de 30 minutes restent généralement sous les 80 000 tokens, loin du seuil de compaction.
| Durée de session | Tokens consommés | Compactions | Qualité du contexte |
|---|---|---|---|
| 15 min | 15 000-30 000 | 0 | Excellente |
| 30 min | 40 000-80 000 | 0-1 | Bonne |
| 1 h | 80 000-150 000 | 1-2 | Moyenne |
| 2 h+ | 150 000+ | 2-3+ | Dégradée |
Pour les développeurs qui souhaitent approfondir ces techniques et les pratiquer sur des cas réels, la formation Développeur Augmenté par l'IA de SFEIR (2 jours) couvre l'optimisation du contexte parmi d'autres compétences avancées d'intégration d'IA dans le workflow de développement.
À retenir : des sessions de 30 à 45 minutes avec des objectifs précis produisent de meilleurs résultats qu'une session marathon.
Comment le protocole MCP interagit-il avec la fenêtre de contexte ?
Chaque appel à un serveur MCP (Model Context Protocol) injecte sa réponse dans la fenêtre de contexte. Surveillez les outils MCP qui retournent de grands volumes de données pour éviter de saturer votre budget de tokens.
Le MCP permet à Claude Code de communiquer avec des services externes : bases de données, APIs, systèmes de fichiers distants. Chaque résultat d'outil MCP consomme des tokens proportionnellement à la taille de la réponse.
Un outil MCP qui retourne 500 lignes de résultats SQL consomme environ 4 000 tokens. Limitez les résultats avec des clauses LIMIT ou des filtres pour contrôler la consommation.
Pour configurer et comprendre le protocole MCP en détail, référez-vous à la FAQ MCP : Model Context Protocol. Si vous débutez avec Claude Code, commencez par la FAQ d'installation et premier lancement.
Pour maîtriser les interactions avancées entre MCP, contexte et agents, la formation Développeur Augmenté par l'IA – Avancé de SFEIR (1 jour) propose des labs dédiés à l'orchestration de serveurs MCP dans des workflows complexes.
À retenir : chaque réponse MCP consomme des tokens - filtrez et limitez les résultats pour préserver votre fenêtre de contexte.
Y a-t-il une différence de coût entre les tokens d'entrée et de sortie ?
Oui, les tokens de sortie coûtent 5 fois plus cher que les tokens d'entrée avec Claude Opus 4 (version 2026). Optimisez vos prompts pour réduire la longueur des réponses générées.
les tarifs Anthropic pour Claude Opus 4 sont de 15 $ par million de tokens d'entrée et 75 $ par million de tokens de sortie. Pour Claude Sonnet 4.6, les tarifs sont de 3 $ et 15 $ respectivement.
| Modèle | Tokens entrée (1M) | Tokens sortie (1M) | Ratio |
|---|---|---|---|
| Claude Opus 4 | 15 $ | 75 $ | 1:5 |
| Claude Sonnet 4.6 | 3 $ | 15 $ | 1:5 |
| Claude Haiku 4.5 | 0,80 $ | 4 $ | 1:5 |
Concrètement, une session de 100 000 tokens d'entrée et 20 000 tokens de sortie sur Opus 4 coûte environ 3 $ (1,50 $ + 1,50 $). Le mode Plan, qui limite les tokens de sortie, permet de réduire ce coût significativement.
À retenir : les tokens de sortie coûtent 5 fois plus cher - le mode Plan et les prompts concis sont vos meilleurs alliés pour contrôler la facture.
Comment déboguer une session où le contexte semble "pollué" ?
Lancez une nouvelle session avec claude --resume ou démarrez une session propre quand les réponses de l'agent perdent en pertinence. Un contexte pollué se manifeste par des hallucinations ou des répétitions.
Trois signaux indiquent un contexte pollué : l'agent répète des informations déjà données, il mélange des fichiers de modules différents, ou il applique des conventions obsolètes d'un échange précédent. Ces symptômes apparaissent généralement après 2 compactions ou plus.
# Démarrer une session propre
$ claude
# Ou reprendre avec un contexte résumé
$ claude --resume
# Compacter manuellement en ciblant les informations utiles
> /compact "Ne conserve que les modifications sur le module payments/"
En pratique, démarrer une nouvelle session ciblée prend 30 secondes et vous fait gagner 10 à 15 minutes de réponses imprécises. C'est le réflexe le plus rentable en gestion du contexte. Les astuces de gestion du contexte proposent d'autres techniques de diagnostic.
À retenir : quand les réponses se dégradent, démarrez une session propre plutôt que de lutter contre un contexte pollué - c'est plus rapide et plus fiable.
Articles récents sur Claude
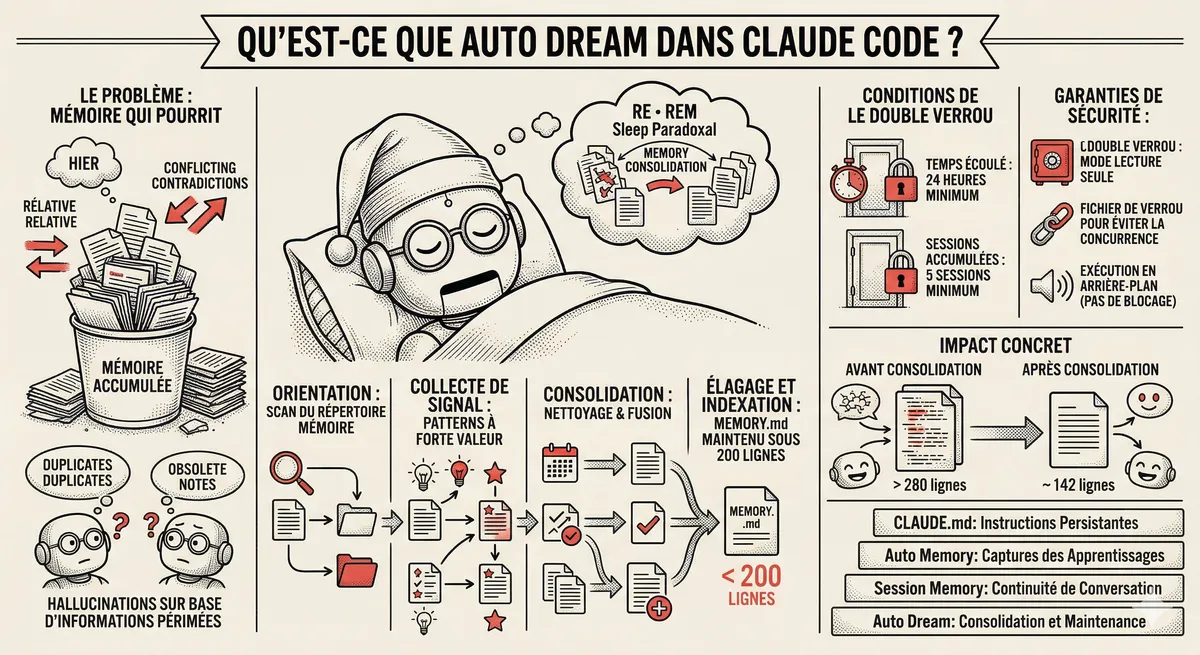
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
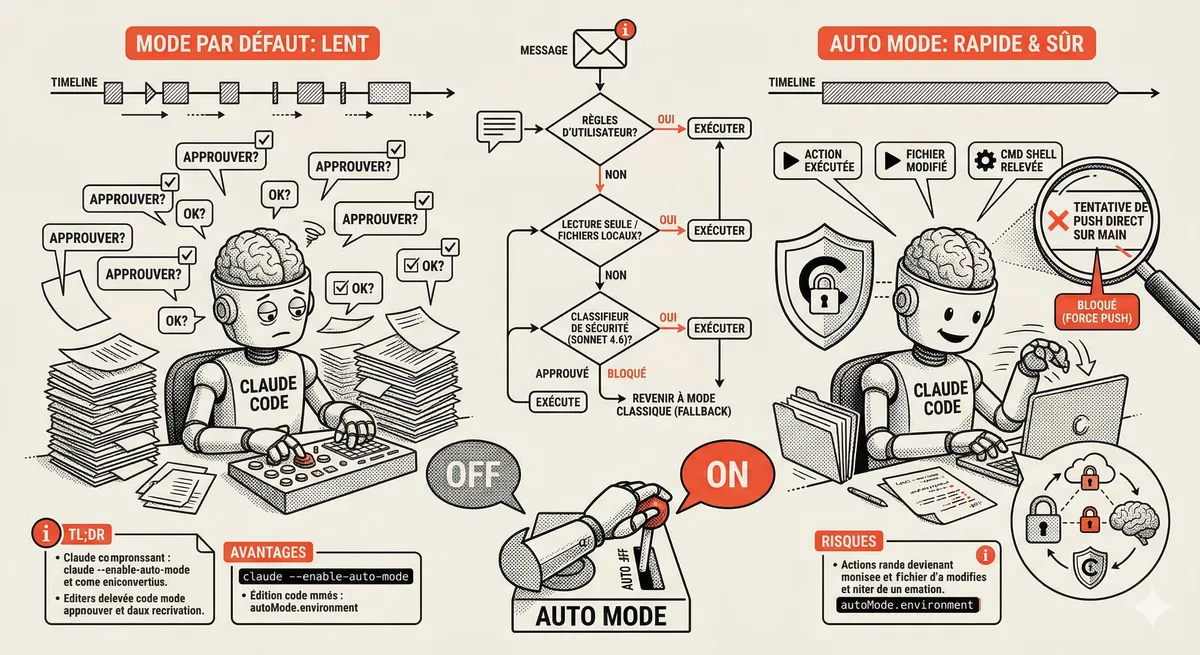
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
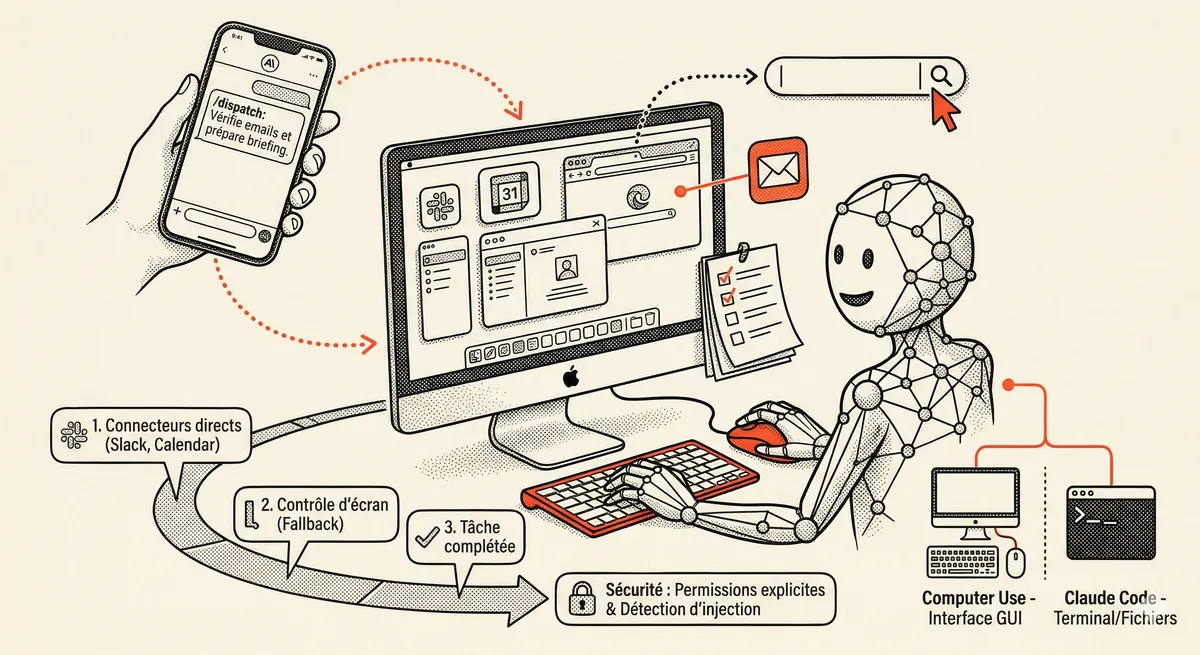
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Ce sujet est couvert dans le Module 4 de notre formation Claude Code
Documentation, organisation et gestion des prompts
Formation 1 jour • 60% labs pratiques • Formateurs experts
Voir le programme complet