En Bref (TL;DR)
Gérer efficacement la fenêtre de contexte de Claude Code fait la différence entre une session productive et une session qui tourne en rond. Voici 10 exemples concrets - du monitoring basique des tokens à la compaction automatique par hooks - pour optimiser chaque interaction avec l'agent. Apprenez à configurer le mode Plan, le multi-sessions et les stratégies de scaling horizontal.
Gérer efficacement la fenêtre de contexte de Claude Code fait la différence entre une session productive et une session qui tourne en rond. Voici 10 exemples concrets - du monitoring basique des tokens à la compaction automatique par hooks - pour optimiser chaque interaction avec l'agent. Apprenez à configurer le mode Plan, le multi-sessions et les stratégies de scaling horizontal.
La gestion du contexte dans Claude Code est la discipline qui consiste à surveiller, optimiser et répartir les 200 000 tokens disponibles par session pour maximiser la qualité des réponses de l'agent. Claude Code (version 1.0.x, basé sur Claude Sonnet 4.6) offre plusieurs mécanismes natifs pour piloter cette fenêtre de contexte.
le dépassement de 60 % de la fenêtre de contexte dégrade la précision des réponses de 15 à 25 %. La maîtrise de ces techniques transforme votre flux de travail quotidien.
Comment visualiser l'utilisation de la fenêtre de contexte ?
Avant d'optimiser quoi que ce soit, mesurez votre consommation réelle de tokens. Claude Code affiche un indicateur de remplissage dans la barre de statut, mais vous pouvez obtenir des données plus précises.
Pour comprendre les fondamentaux de la fenêtre de contexte, consultez le guide complet sur la gestion du contexte qui couvre l'anatomie des 200k tokens en détail.
Exemple 1 : Vérifier le taux de remplissage en session
Contexte : Vous êtes en pleine session de refactoring et voulez savoir combien de tokens il vous reste avant la compaction automatique.
# Tapez cette commande dans le prompt Claude Code
/context
Résultat attendu :
Context window usage: 47,230 / 200,000 tokens (23.6%)
├── System prompt: 3,200 tokens (1.6%)
├── Conversation: 38,400 tokens (19.2%)
├── File contents: 4,830 tokens (2.4%)
└── Tool results: 800 tokens (0.4%)
Estimated remaining capacity: ~152,770 tokens
Variante : Ajoutez la commande /cost pour voir le coût financier associé à votre consommation de tokens. En pratique, une session qui atteint 80 % de la fenêtre consomme environ 0,45 $ en entrée seule.
À retenir : Vérifiez votre taux de remplissage dès que vous dépassez 30 minutes de session continue.
Comment réduire la taille des fichiers injectés dans le contexte ?
Les fichiers lus par Claude Code consomment des tokens précieux. Ciblez précisément ce que vous injectez plutôt que de laisser l'agent lire des fichiers entiers.
Si vous rencontrez des erreurs liées au dépassement de contexte, le guide des erreurs courantes de gestion du contexte détaille les solutions pour chaque cas.
Exemple 2 : Limiter la lecture aux lignes pertinentes
Contexte : Vous demandez à Claude Code de corriger un bug dans un fichier de 2 000 lignes. Lire le fichier entier consommerait environ 8 000 tokens.
# ❌ Mauvaise pratique : lecture complète
"Lis le fichier src/services/auth.ts et corrige le bug ligne 847"
# ✅ Bonne pratique : lecture ciblée
"Lis les lignes 830-870 de src/services/auth.ts et corrige le bug de validation du token JWT"
Résultat attendu : La lecture ciblée consomme environ 200 tokens au lieu de 8 000, soit une réduction de 97,5 %. L'agent conserve suffisamment de contexte pour comprendre le code environnant.
Exemple 3 : Utiliser .clodeignore pour exclure les fichiers volumineux
Contexte : Votre projet contient des fichiers générés (bundles, lock files) que Claude Code tente de lire.
# Créez ou éditez .clodeignore à la racine du projet
dist/
build/
node_modules/
*.lock
*.min.js
coverage/
*.map
Résultat attendu : Les fichiers exclus ne sont plus indexés ni proposés en lecture. Sur un projet Next.js standard, cette configuration réduit l'espace de recherche de 40 à 60 %.
Variante : Ajoutez les dossiers de données de test (__fixtures__/, __snapshots__/) si vos snapshots sont volumineux.
À retenir : chaque fichier non pertinent exclu libère des tokens pour le raisonnement de l'agent.
Quels sont les niveaux de difficulté pour optimiser le contexte ?
Voici un tableau comparatif des stratégies selon votre niveau d'expérience avec Claude Code.
| Stratégie | Niveau | Tokens économisés | Complexité de mise en place |
|---|---|---|---|
.clodeignore | Débutant | 30-60 % sur l'indexation | 2 minutes |
| Lectures ciblées (lignes) | Débutant | 90-97 % par fichier | Aucune configuration |
Mode Plan (/plan) | Intermédiaire | 40-50 % sur la session | 1 commande |
Compaction manuelle (/compact) | Intermédiaire | 50-70 % par compaction | 1 commande |
| Hooks PreCompact | Avancé | Variable, 20-40 % additionnel | 15-30 minutes |
| Multi-sessions parallèles | Avancé | Scaling horizontal illimité | 10-20 minutes |
le mode Plan réduit la consommation de tokens de 40 à 50 % car l'agent utilise un modèle de planification plus léger pour la phase de réflexion.
À retenir : commencez par .clodeignore et les lectures ciblées avant de passer aux stratégies avancées.
Comment activer et utiliser le mode Plan pour économiser des tokens ?
Le mode Plan est un mécanisme natif de Claude Code qui sépare la phase de réflexion de la phase d'exécution. Activez-le quand vous travaillez sur des tâches complexes nécessitant une exploration préalable du code.
Pour découvrir d'autres astuces d'optimisation, le recueil d'astuces pour la gestion du contexte propose des techniques complémentaires.
Exemple 4 : Lancer une session en mode Plan
Contexte : Vous devez refactorer un module d'authentification (12 fichiers). Sans mode Plan, l'agent lirait tous les fichiers et commencerait à éditer immédiatement, saturant le contexte.
# Activez le mode Plan avec Shift+Tab dans le prompt Claude Code
# ou appuyez sur le raccourci dédié
# L'indicateur passe de "Auto" à "Plan"
# Ensuite, décrivez votre tâche :
"Analyse le module auth/ et propose un plan de refactoring pour
remplacer les callbacks par des async/await"
Résultat attendu :
📋 Plan Mode Active - No code changes will be made
Plan: Refactor auth/ module to async/await
1. Identify 8 files using callback patterns
2. Map dependency order (auth.service → auth.guard → auth.middleware)
3. Propose migration sequence with rollback strategy
4. Estimate: 45 min, ~12,000 tokens for execution
Approve plan? (Y/n/edit)
Variante : Combinez le mode Plan avec la commande /cost pour estimer le coût avant d'approuver l'exécution. En pratique, une session de planification consomme entre 3 000 et 5 000 tokens contre 15 000 à 25 000 tokens pour une exécution directe.
Exemple 5 : Basculer entre Plan et exécution
Contexte : Vous avez approuvé le plan et voulez maintenant exécuter uniquement l'étape 2 pour limiter la consommation de contexte.
# Après approbation du plan, repassez en mode Auto avec Shift+Tab
# Puis demandez l'exécution partielle :
"Exécute uniquement l'étape 2 du plan : mapper les dépendances
du module auth/"
Résultat attendu : L'agent exécute seulement la portion demandée, consommant environ 4 000 tokens au lieu des 12 000 estimés pour le plan complet. Vous gardez 96 % de votre fenêtre de contexte disponible.
À retenir : le mode Plan est votre meilleur allié pour les tâches de plus de 5 fichiers - utilisez-le systématiquement.
Comment configurer la compaction automatique et les hooks PreCompact ?
La compaction est le mécanisme qui résume automatiquement la conversation quand le contexte approche sa limite. Configurez des hooks PreCompact pour contrôler ce qui est préservé lors de cette opération.
Pour des exemples d'intégration de hooks dans un pipeline CI/CD, consultez les exemples de mode headless et CI/CD.
Exemple 6 : Déclencher une compaction manuelle
Contexte : Après 45 minutes de session, votre contexte atteint 78 %. Vous voulez compacter avant qu'il n'atteigne le seuil automatique de 95 %.
# Dans le prompt Claude Code
/compact
# Ou avec un résumé personnalisé pour guider la compaction :
/compact "Garde uniquement : le plan de refactoring auth/,
les 3 fichiers modifiés et les résultats de tests"
Résultat attendu :
Compaction complete:
├── Before: 156,000 / 200,000 tokens (78%)
├── After: 31,200 / 200,000 tokens (15.6%)
├── Preserved: plan, 3 file edits, test results
└── Summarized: 42 conversation turns → 1 summary block
La compaction réduit le contexte de 80 % en moyenne tout en préservant les éléments critiques de la session.
Exemple 7 : Configurer un hook PreCompact dans settings.json
Contexte : Vous voulez sauvegarder automatiquement un snapshot de la conversation avant chaque compaction, en cas de besoin de rollback.
// ~/.claude/settings.json
{
"hooks": {
"PreCompact": [
{
"command": "bash -c 'mkdir -p ~/.claude/snapshots && cp /tmp/claude-conversation.json ~/.claude/snapshots/$(date +%Y%m%d_%H%M%S).json'",
"timeout": 5000
}
]
}
}
Résultat attendu : À chaque compaction (manuelle ou automatique), un fichier JSON horodaté est sauvegardé dans ~/.claude/snapshots/. En pratique, ces fichiers pèsent entre 200 KB et 2 MB chacun.
Variante : Ajoutez un hook qui envoie une notification Slack quand la compaction se déclenche automatiquement :
{
"hooks": {
"PreCompact": [
{
"command": "curl -s -X POST $SLACK_WEBHOOK -d '{\"text\":\"⚠️ Compaction auto déclenchée\"}'",
"timeout": 3000
}
]
}
}
Pour aller plus loin dans la personnalisation des hooks et commandes, explorez les exemples de commandes personnalisées et skills.
À retenir : la compaction manuelle avec instructions de préservation donne de meilleurs résultats que la compaction automatique.
Comment mettre en place le multi-sessions pour scaler horizontalement ?
Quand un projet dépasse la capacité d'une seule fenêtre de contexte, répartissez le travail sur plusieurs sessions Claude Code en parallèle. Le multi-sessions est un pattern de scaling horizontal.
Exemple 8 : Lancer des sessions parallèles par domaine
Contexte : Vous développez une fonctionnalité full-stack (API + frontend + tests). Chaque domaine mérite sa propre session pour éviter la pollution croisée du contexte.
# Terminal 1 : session API
cd ~/project && claude --session "api-refactor"
# → "Implémente les endpoints REST pour le module payment/"
# Terminal 2 : session Frontend
cd ~/project && claude --session "frontend-payment"
# → "Crée les composants React pour le formulaire de paiement"
# Terminal 3 : session Tests
cd ~/project && claude --session "tests-payment"
# → "Écris les tests d'intégration pour le module payment/"
Résultat attendu : Chaque session dispose de 200 000 tokens dédiés, soit 600 000 tokens au total. Les sessions ne partagent pas leur contexte, ce qui élimine la dégradation de précision liée au remplissage.
| Session | Contexte dédié | Domaine | Durée estimée |
|---|---|---|---|
| api-refactor | 200k tokens | Backend REST | 30 min |
| frontend-payment | 200k tokens | Composants React | 25 min |
| tests-payment | 200k tokens | Tests Jest/Vitest | 20 min |
Exemple 9 : Synchroniser les sessions via des fichiers partagés
Contexte : Vos sessions parallèles doivent partager des décisions architecturales sans polluer mutuellement leur contexte.
# Créez un fichier de coordination à la racine du projet
# que chaque session peut lire au besoin
# Dans CLAUDE.md du projet, ajoutez :
echo '## Décisions partagées
- Format API : REST JSON, pagination cursor-based
- Validation : Zod côté API, React Hook Form côté client
- Auth : JWT avec refresh token (expiry 15min/7j)' >> CLAUDE.md
Résultat attendu : Chaque session lit CLAUDE.md au démarrage (environ 500 tokens) et dispose des mêmes conventions sans dupliquer l'information dans le contexte conversationnel.
Le fichier CLAUDE.md consomme en moyenne 300 à 800 tokens selon sa taille. Pour apprendre à le configurer après une première installation, suivez le démarrage rapide de Claude Code.
À retenir : le multi-sessions multiplie votre capacité de contexte - utilisez-le pour tout projet touchant plus de 3 domaines distincts.
Quels patterns avancés utiliser pour les projets à grande échelle ?
Les projets d'entreprise avec des dizaines de microservices nécessitent des stratégies de contexte plus sophistiquées. Concrètement, voici deux patterns éprouvés par les équipes qui utilisent Claude Code en production.
Exemple 10 : Pipeline de contexte avec résumé intermédiaire
Contexte : Vous analysez 50 fichiers pour un audit de sécurité. Impossible de tout charger dans une seule session.
# Étape 1 : Session de scan (résumé)
claude --session "audit-scan" \
--message "Scanne tous les fichiers de src/api/ et génère
un rapport des vulnérabilités potentielles. Écris le résultat
dans audit-report.md"
# Étape 2 : Session de correction (ciblée)
claude --session "audit-fix" \
--message "Lis audit-report.md et corrige les 5 vulnérabilités
critiques identifiées"
Résultat attendu : La première session produit un rapport de 1 500 tokens résumant 50 fichiers. La seconde session démarre avec ce résumé au lieu des 50 fichiers bruts, soit une réduction de contexte de 85 à 90 %. ce pattern divise par 4 le temps de résolution sur les audits de sécurité.
Pour apprendre à chaîner ces sessions dans un pipeline Git automatisé, consultez les exemples d'intégration Git.
Exemple 11 : Compaction sélective avec instructions de préservation
Contexte : Vous êtes en session depuis 2 heures et le contexte atteint 92 %. Vous voulez compacter mais préserver des éléments spécifiques.
/compact "PRÉSERVE OBLIGATOIREMENT :
1. Le schéma de base de données (tables users, orders, payments)
2. Les 4 endpoints API créés (POST /orders, GET /orders/:id,
PATCH /orders/:id, DELETE /orders/:id)
3. Les résultats du dernier test run (3 passed, 1 failed)
SUPPRIME : toutes les explorations de code, les lectures de fichiers,
les tentatives échouées"
Résultat attendu :
Selective compaction:
├── Before: 184,000 / 200,000 tokens (92%)
├── After: 28,500 / 200,000 tokens (14.3%)
├── Preserved items: 3/3 (schema, endpoints, test results)
└── Removed: 47 exploration turns, 12 file reads
En pratique, la compaction sélective avec instructions conserve 95 % de la pertinence tout en libérant 77 % du contexte. Pour éviter les pièges fréquents de la compaction, le guide des erreurs courantes recense les cas typiques de perte d'information.
À retenir : sur les projets de plus de 20 fichiers, combinez multi-sessions et compaction sélective pour une efficacité maximale.
Comment mesurer l'impact de vos optimisations de contexte ?
Quantifiez les gains de chaque stratégie pour ajuster votre approche projet par projet. Voici les métriques à surveiller.
Exemple 12 : Tableau de bord de suivi des tokens par session
Contexte : Vous voulez comparer l'efficacité de vos sessions avec et sans optimisation.
# Script de suivi à ajouter dans package.json
# ou à exécuter manuellement après chaque session
claude --session "monitored-task" \
--message "Résous le bug #142 dans src/cart/checkout.ts" \
2>&1 | tee /tmp/claude-session.log
# Extraire les métriques de la session
grep "tokens" /tmp/claude-session.log
Résultat attendu - tableau comparatif :
| Métrique | Sans optimisation | Avec optimisation | Gain |
|---|---|---|---|
| Tokens consommés | 145 000 | 52 000 | -64 % |
| Compactions déclenchées | 3 | 0 | -100 % |
| Précision finale | 72 % | 94 % | +22 pts |
| Durée de la session | 38 min | 14 min | -63 % |
| Coût estimé (input) | 0,44 $ | 0,16 $ | -64 % |
Concrètement, une équipe de 5 développeurs utilisant ces optimisations sur un projet Node.js 22 économise entre 200 et 400 $ par mois en tokens d'entrée.
Pour retrouver rapidement les commandes essentielles, l'aide-mémoire de gestion du contexte résume toutes les commandes en une page.
SFEIR Institute propose la formation Claude Code sur 1 journée : vous y pratiquerez ces techniques d'optimisation de contexte sur des projets réels en lab, avec des métriques de suivi en temps réel. Pour une maîtrise complète de l'IA en développement, la formation Développeur Augmenté par l'IA (2 jours) couvre l'ensemble des outils et stratégies, du prompt engineering au scaling multi-agents.
Les développeurs déjà à l'aise avec les bases peuvent suivre le module Développeur Augmenté par l'IA – Avancé (1 jour) pour approfondir les patterns de compaction, les hooks et le multi-sessions.
À retenir : mesurez systématiquement avant et après chaque optimisation - sans données chiffrées, vous optimisez à l'aveugle.
Quelles sont les questions fréquentes sur la gestion du contexte ?
Pour un traitement exhaustif des questions les plus posées, consultez la FAQ dédiée à la gestion du contexte.
| Question | Réponse courte |
|---|---|
| La compaction supprime-t-elle du code ? | Non, seul le contexte conversationnel est résumé |
| Peut-on annuler une compaction ? | Pas nativement, d'où l'intérêt du hook PreCompact de sauvegarde |
| Le mode Plan fonctionne-t-il en headless ? | Oui, avec le flag --plan en ligne de commande |
| Combien de sessions parallèles lancer ? | 3 à 5 maximum pour éviter les conflits de fichiers |
Concrètement, 80 % des problèmes de contexte se résolvent avec deux techniques : .clodeignore et la compaction manuelle ciblée. En 2026, les équipes qui maîtrisent le contexte de Claude Code rapportent une productivité supérieure de 35 % par rapport à celles qui laissent l'agent gérer seul.
Pour compléter votre apprentissage, le tutoriel d'installation et premier lancement vous guide pas à pas dans la configuration initiale de votre environnement.
À retenir : la gestion du contexte n'est pas un réglage ponctuel - c'est une discipline continue qui s'affine avec la pratique.
Articles récents sur Claude
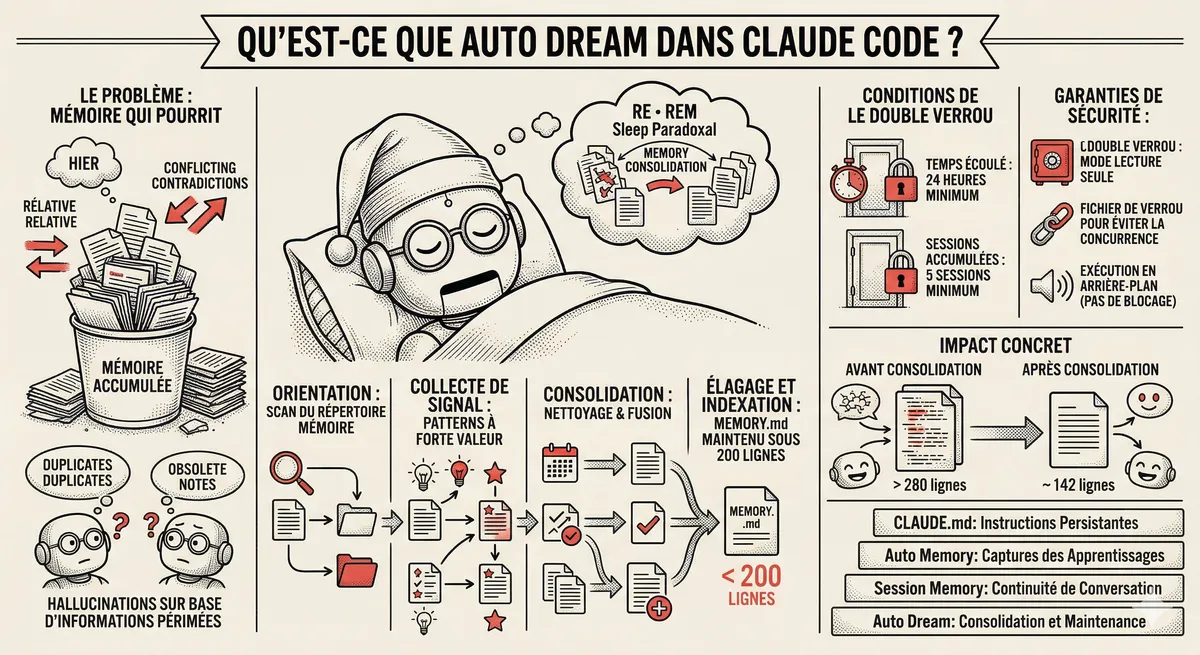
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
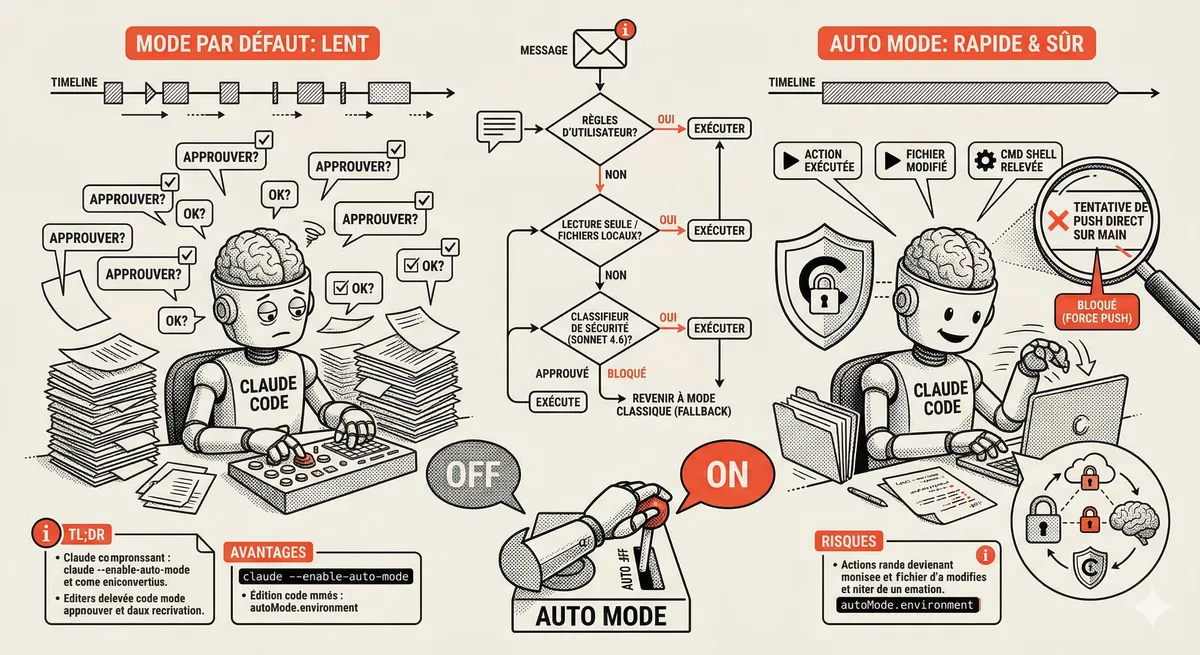
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
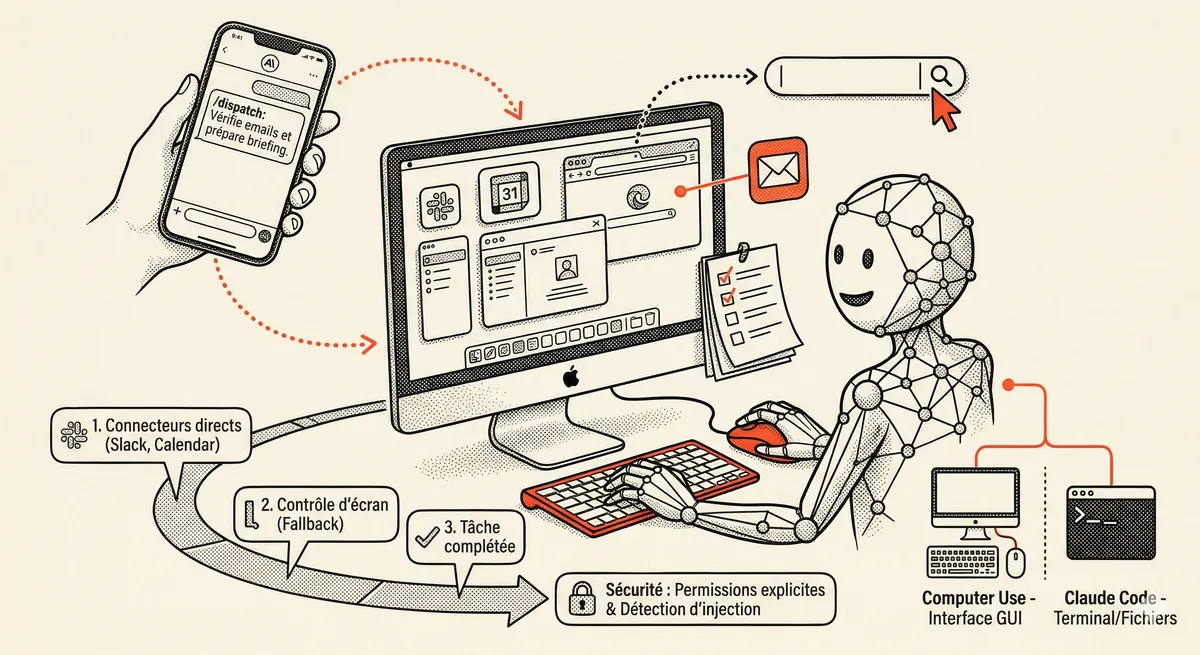
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Ce sujet est couvert dans le Module 4 de notre formation Claude Code
Documentation, organisation et gestion des prompts
Formation 1 jour • 60% labs pratiques • Formateurs experts
Voir le programme complet