En Bref (TL;DR)
La gestion du contexte dans Claude Code détermine la qualité de chaque réponse générée. Maîtriser la fenêtre de 200 000 tokens, la compaction automatique et le mode Plan vous permet de maintenir des sessions productives sur des projets complexes. Voici comment optimiser chaque token pour un scaling horizontal efficace via les multi-sessions.
La gestion du contexte dans Claude Code détermine la qualité de chaque réponse générée. Maîtriser la fenêtre de 200 000 tokens, la compaction automatique et le mode Plan vous permet de maintenir des sessions productives sur des projets complexes. Voici comment optimiser chaque token pour un scaling horizontal efficace via les multi-sessions.
La gestion du contexte dans Claude Code est le mécanisme qui contrôle quelles informations l'agent conserve, compresse ou évacue au fil d'une session de travail. Claude Code exploite une fenêtre de 200 000 tokens - soit environ 150 000 mots - pour analyser votre codebase, générer du code et maintenir la cohérence de ses réponses.
la fenêtre de contexte de Claude représente l'un des plus grands espaces de travail disponibles parmi les modèles de langage actuels, avec 200 000 tokens contre 128 000 pour GPT-4 Turbo. Cette capacité influence directement la profondeur d'analyse possible sur un projet.
Comment fonctionne la fenêtre de 200 000 tokens dans Claude Code ?
La fenêtre de contexte est la mémoire de travail active de Claude Code pendant une session. Chaque élément consommé - prompt système, fichiers lus, réponses générées - occupe une portion mesurable de ces 200 000 tokens.
Décomposez cette fenêtre en quatre zones distinctes. Le prompt système et les instructions CLAUDE.md consomment entre 5 000 et 15 000 tokens selon votre configuration. Les fichiers de code lus occupent la majeure partie : un fichier TypeScript de 500 lignes représente environ 3 000 tokens.
Pour comprendre la répartition concrète, consultez le guide complet de gestion du contexte qui détaille chaque composant de la fenêtre.
| Zone de contexte | Tokens estimés | Pourcentage |
|---|---|---|
| Prompt système + CLAUDE.md | 5 000 – 15 000 | 3 – 8 % |
| Fichiers lus (code source) | 50 000 – 120 000 | 25 – 60 % |
| Historique de conversation | 30 000 – 80 000 | 15 – 40 % |
| Réponses générées | 20 000 – 50 000 | 10 – 25 % |
Un token correspond à environ 0,75 mot en anglais et 0,5 mot en français. En pratique, 200 000 tokens permettent de charger simultanément 40 à 60 fichiers de taille moyenne dans une seule session.
Vérifiez votre consommation en cours de session avec la commande /cost. Claude Code affiche le nombre de tokens utilisés et le coût associé en temps réel.
# Vérifier la consommation de tokens en session
$ claude --session mon-projet
> /cost
# Affiche : Tokens utilisés: 45,230 / 200,000 (22.6%)
À retenir : la fenêtre de 200 000 tokens se décompose en quatre zones dont la répartition varie selon votre usage - surveillez votre consommation avec /cost pour éviter les compactions prématurées.
Quelles stratégies d'optimisation du contexte appliquer ?
L'optimisation du contexte consiste à maximiser la quantité d'informations utiles par token consommé. Adoptez trois stratégies complémentaires pour y parvenir.
Première stratégie : le fichier CLAUDE.md. Ce fichier permet de fournir des instructions persistantes sans les répéter à chaque message. Créez un fichier CLAUDE.md à la racine de votre projet avec vos conventions de code, vos patterns architecturaux et vos règles de nommage.
# CLAUDE.md
## Conventions
- TypeScript strict, pas de `any`
- Tests avec Vitest, couverture > 80%
- Commits conventionnels (feat:, fix:, chore:)
## Architecture
- Clean architecture avec ports/adapters
- Services injectés via constructeur
le fichier CLAUDE.md réduit la consommation de tokens de 15 à 30 % sur les sessions longues en éliminant les instructions répétées. Pour approfondir les bonnes pratiques de configuration, consultez le guide des bonnes pratiques Claude Code.
Deuxième stratégie : les instructions ciblées. Formulez vos prompts avec précision en indiquant le fichier exact, la fonction concernée et le résultat attendu. Un prompt précis consomme 60 % moins de tokens qu'un prompt vague, car Claude Code n'a pas besoin d'explorer pour comprendre votre intention.
| Type de prompt | Tokens consommés | Efficacité |
|---|---|---|
| Vague : "corrige le bug" | 8 000 – 15 000 | Faible |
Ciblé : "corrige le null check dans parseConfig() de src/config.ts" | 3 000 – 5 000 | Haute |
Ultra-ciblé avec contexte : "dans src/config.ts:42, ajoute ?? {} après JSON.parse()" | 1 500 – 2 500 | Maximale |
Troisième stratégie : la segmentation des tâches. Divisez les modifications complexes en sous-tâches indépendantes. Une refactorisation de 20 fichiers consomme moins de contexte quand elle est découpée en 4 sessions de 5 fichiers qu'en une seule session massive.
Découvrez des exemples concrets d'optimisation du contexte pour appliquer ces stratégies sur vos projets réels.
À retenir : combinez CLAUDE.md, prompts ciblés et segmentation des tâches pour réduire votre consommation de tokens de 30 à 50 %.
Comment le mode Plan permet-il d'économiser du contexte ?
Le mode Plan est une fonctionnalité de Claude Code qui sépare la phase de réflexion de la phase d'exécution. Activez-le avec la touche Shift+Tab ou en tapant la commande dédiée dans votre session.
En mode Plan, Claude Code analyse votre demande, explore le code et propose une stratégie - sans exécuter de modifications. Concrètement, cette séparation économise entre 20 et 40 % de tokens sur les tâches complexes.
# Activer le mode Plan dans Claude Code
$ claude
> [Shift+Tab] # Bascule en mode Plan
> Refactorise le module d'authentification pour utiliser JWT
# Claude Code analyse et propose un plan sans modifier de fichiers
Le fonctionnement interne repose sur un modèle de raisonnement étendu (extended thinking). Claude Code utilise des tokens de réflexion qui ne comptent pas dans la fenêtre de contexte principale. En pratique, 10 000 tokens de réflexion en mode Plan remplacent 25 000 tokens d'exploration en mode normal.
| Mode | Tokens exploration | Tokens exécution | Total |
|---|---|---|---|
| Normal (sans Plan) | 25 000 | 15 000 | 40 000 |
| Avec mode Plan | 10 000 (réflexion) | 12 000 | 22 000 |
| Économie | - | - | 45 % |
Utilisez le mode Plan systématiquement pour les tâches impliquant plus de 3 fichiers. Avant toute refactorisation, lancez une analyse en mode Plan pour identifier les fichiers impactés et les dépendances, puis validez le plan avant l'exécution.
Le guide d'optimisation du contexte de SFEIR Institute détaille des workflows avancés combinant le mode Plan et les sessions segmentées.
L'arbre de décision est simple. Si votre tâche touche 1 à 2 fichiers → mode normal. Si elle touche 3 fichiers ou plus → mode Plan. Si elle implique une refactorisation transverse → mode Plan + multi-sessions.
À retenir : le mode Plan économise 45 % de tokens en moyenne sur les tâches complexes en séparant réflexion et exécution.
Comment fonctionne la compaction automatique dans Claude Code ?
La compaction automatique est le mécanisme par lequel Claude Code compresse l'historique de conversation quand la fenêtre de contexte approche sa limite. Ce processus se déclenche automatiquement à environ 95 % de remplissage, soit environ 190 000 tokens.
Comprenez le processus en trois étapes. D'abord, Claude Code identifie les messages les plus anciens dans la conversation. Ensuite, il résume ces échanges en conservant les décisions clés, les fichiers modifiés et les erreurs rencontrées. Enfin, il remplace les messages originaux par ce résumé compressé.
{
"compaction": {
"trigger_threshold": 0.95,
"target_reduction": 0.50,
"preserved_elements": [
"file_modifications",
"error_messages",
"user_decisions",
"current_task_context"
]
}
}
En pratique, une compaction réduit le contexte de 50 % tout en conservant 85 à 90 % des informations pertinentes. la perte de qualité post-compaction reste inférieure à 5 % pour les tâches de codage standard.
Le hook PreCompact vous donne un contrôle supplémentaire. Configurez ce hook dans votre fichier .claude/settings.json pour exécuter des actions avant chaque compaction - par exemple sauvegarder l'état du projet ou journaliser les décisions.
// .claude/settings.json
{
"hooks": {
"PreCompact": [
{
"command": "echo 'Compaction déclenchée à $(date)' >> .claude/compaction.log"
}
]
}
}
Pour maîtriser la compaction manuelle, consultez l'aide-mémoire sur la gestion du contexte qui liste toutes les commandes disponibles.
La commande /compact déclenche une compaction manuelle avec un prompt personnalisé. Exécutez /compact gardez le focus sur le module auth pour orienter la compression vers les informations pertinentes pour votre tâche en cours.
# Compaction manuelle ciblée
> /compact conserve les décisions d'architecture et les erreurs TypeScript
# Réduit le contexte de ~50% en gardant les informations spécifiées
À retenir : la compaction automatique se déclenche à 95 % de remplissage et compresse 50 % du contexte - utilisez le hook PreCompact et la commande /compact pour garder le contrôle.
Comment configurer les hooks PreCompact pour un contrôle avancé ?
Les hooks PreCompact sont des scripts shell exécutés automatiquement avant chaque opération de compaction. Configurez-les dans le fichier .claude/settings.json au niveau projet ou dans ~/.claude/settings.json au niveau global.
Un hook PreCompact reçoit en entrée un objet JSON contenant le nombre de tokens actuels, le seuil de déclenchement et la liste des fichiers modifiés pendant la session. Exploitez ces données pour automatiser vos workflows.
#!/bin/bash
# .claude/hooks/pre-compact.sh
# Sauvegarde automatique avant compaction
# Lire les données de compaction depuis stdin
COMPACTION_DATA=$(cat)
TOKEN_COUNT=$(echo $COMPACTION_DATA | jq '.tokenCount')
FILES_MODIFIED=$(echo $COMPACTION_DATA | jq -r '.filesModified[]')
# Créer un snapshot git
git stash push -m "pre-compact-$(date +%s)" $FILES_MODIFIED
echo "Snapshot créé avec $TOKEN_COUNT tokens en contexte"
Voici un cas d'usage concret : vous travaillez sur une migration de base de données avec 15 fichiers de migration. Configurez un hook PreCompact qui sauvegarde l'état de progression pour le restaurer après compaction.
Pour aller plus loin sur les workflows automatisés, le guide sur le coding agentique en profondeur explore les patterns avancés d'orchestration avec Claude Code.
| Hook | Déclencheur | Cas d'usage |
|---|---|---|
| PreCompact | Avant compaction | Sauvegarde d'état, logging |
| PostCompact | Après compaction | Vérification de cohérence |
| PreToolUse | Avant un outil | Validation de sécurité |
| PostToolUse | Après un outil | Audit des modifications |
En pratique, les équipes qui utilisent des hooks PreCompact rapportent une réduction de 70 % des pertes d'information lors des sessions longues dépassant 2 heures.
À retenir : les hooks PreCompact automatisent la sauvegarde d'état avant compaction - configurez-les pour ne jamais perdre le fil d'une session longue.
Comment mettre en place les multi-sessions et le scaling horizontal ?
Le scaling horizontal avec Claude Code consiste à distribuer le travail sur plusieurs sessions parallèles plutôt que de surcharger une seule fenêtre de contexte. Lancez plusieurs instances de Claude Code, chacune focalisée sur un sous-ensemble de votre projet.
L'architecture multi-sessions repose sur le flag --session-id qui identifie chaque session de manière unique. Créez des sessions dédiées par domaine fonctionnel pour maintenir un contexte spécialisé et réduit.
# Lancer 3 sessions parallèles spécialisées
$ claude --session-id auth-module &
$ claude --session-id api-routes &
$ claude --session-id frontend-components &
graph TD
A[Projet principal] --> B[Session 1: Auth]
A --> C[Session 2: API]
A --> D[Session 3: Frontend]
B --> E[CLAUDE.md partagé]
C --> E
D --> E
B --> F[Contexte: 60k tokens]
C --> G[Contexte: 45k tokens]
D --> H[Contexte: 55k tokens]
Le modèle de données partagé entre sessions passe par le fichier CLAUDE.md et le système de fichiers. Documentez les décisions prises dans chaque session via des commentaires de code ou un fichier de décisions partagé. Consultez les bonnes pratiques d'intégration Git pour coordonner les commits entre sessions parallèles.
| Approche | Contexte par session | Fichiers gérés | Risque de conflit |
|---|---|---|---|
| Session unique | 200 000 tokens | Tous | Aucun |
| 2 sessions | 100 000 tokens chacune | Répartis par module | Faible |
| 4+ sessions | 50 000 tokens chacune | Par domaine métier | Modéré |
| Sessions + worktrees Git | 50 000 tokens chacune | Isolés physiquement | Minimal |
Pour un isolation complète, combinez les multi-sessions avec les Git worktrees. Chaque session opère sur sa propre copie de travail, éliminant les conflits de fichiers.
# Créer des worktrees isolés pour chaque session
$ git worktree add ../projet-auth feature/auth
$ git worktree add ../projet-api feature/api
# Lancer Claude Code dans chaque worktree
$ cd ../projet-auth && claude --session-id auth
$ cd ../projet-api && claude --session-id api
En pratique, le scaling sur 3 sessions parallèles multiplie le débit de modifications par 2,5 tout en réduisant les compactions de 80 %. cette approche devient indispensable sur les projets dépassant 50 000 lignes de code.
À retenir : distribuez le travail sur 2 à 4 sessions parallèles avec des Git worktrees pour maximiser le débit sans sacrifier la cohérence du contexte.
Quand ne pas utiliser l'optimisation poussée du contexte ?
Toutes les situations ne justifient pas une stratégie complexe de gestion du contexte. Identifiez les cas où la simplicité l'emporte sur l'optimisation.
Pour les tâches courtes - moins de 10 000 tokens - l'overhead de configuration d'un mode Plan ou de sessions multiples dépasse le bénéfice. Restez en mode normal pour les corrections de bugs ponctuels, les modifications de 1 à 2 fichiers ou les questions exploratoires.
Le prototypage rapide ne bénéficie pas du scaling horizontal. Quand vous explorez des idées, la compaction automatique suffit. Laissez Claude Code gérer le contexte automatiquement pendant les phases d'expérimentation. Consultez les recommandations pour vos premières conversations avant de complexifier votre workflow.
Voici l'arbre de décision complet :
- Si votre tâche touche 1 à 3 fichiers et dure moins de 30 minutes → mode normal, pas d'optimisation
- Si votre tâche touche 4 à 10 fichiers → activez le mode Plan, utilisez
/compactmanuellement - Si votre tâche touche plus de 10 fichiers ou dure plus de 2 heures → multi-sessions avec worktrees
- Si vous travaillez en équipe sur le même projet → multi-sessions + CLAUDE.md partagé + hooks PreCompact
- Si votre codebase dépasse 100 000 lignes → considérez le coding agentique avec orchestration
| Situation | Stratégie recommandée | Complexité de setup |
|---|---|---|
| Bug fix ponctuel | Mode normal | Aucune |
| Feature < 5 fichiers | Mode Plan | 1 minute |
| Refactoring transverse | Multi-sessions | 5 minutes |
| Migration de codebase | Sessions + worktrees + hooks | 15 minutes |
En pratique, 70 % des tâches quotidiennes d'un développeur se résolvent en mode normal sans optimisation du contexte. L'optimisation apporte ses gains sur les 30 % restants - les tâches longues, complexes ou multi-fichiers.
SFEIR Institute propose la formation Claude Code d'une journée pour maîtriser ces techniques de gestion du contexte en conditions réelles avec des labs pratiques. Pour aller plus loin, la formation Développeur Augmenté par l'IA sur 2 jours couvre l'ensemble du workflow agentique, y compris le scaling horizontal sur des projets d'entreprise. Les profils confirmés peuvent suivre la formation Développeur Augmenté par l'IA – Avancé d'une journée pour approfondir les hooks, la compaction et les architectures multi-agents.
À retenir : n'optimisez pas par défaut - réservez les stratégies avancées aux 30 % de tâches qui dépassent 4 fichiers ou 30 minutes de travail.
Quels outils comparer pour la gestion du contexte entre agents IA ?
Claude Code n'est pas le seul agent IA à proposer une gestion du contexte. Comparez les approches pour choisir l'outil adapté à votre besoin. Avant de commencer, consultez le guide d'installation et premier lancement pour vérifier vos prérequis.
| Critère | Claude Code (v2.x, 2026) | GitHub Copilot Workspace | Cursor (v0.45+) | Aider (v0.75+) |
|---|---|---|---|---|
| Fenêtre de contexte | 200 000 tokens | 128 000 tokens | 128 000 tokens | Variable (selon modèle) |
| Compaction automatique | Oui, configurable | Non | Partielle | Oui, map/repository |
| Mode Plan | Oui (Shift+Tab) | Non | Partielle (Composer) | Non |
| Multi-sessions | Oui (--session-id) | Non | Non | Oui (--session) |
| Hooks personnalisés | Oui (Pre/Post) | Non | Non | Non |
| Coût moyen par session (1h) | 0,50 – 2,00 $ | Inclus abonnement | Inclus abonnement | Variable |
Claude Code se distingue par trois avantages : la fenêtre de contexte la plus large (200 000 tokens), les hooks personnalisables et le mode Plan natif. Son principal compromis est le modèle de tarification à l'usage, qui incite à optimiser chaque token consommé.
Concrètement, pour les projets Node.js 22 et TypeScript 5.4, Claude Code traite en moyenne 3 500 tokens par seconde en lecture et génère 80 tokens par seconde en écriture. Ces métriques impactent directement le temps de réponse sur les sessions chargées.
À retenir : Claude Code offre la fenêtre de contexte la plus large et le meilleur contrôle via les hooks - choisissez-le pour les projets nécessitant des sessions longues et un contrôle fin.
Comment mesurer et surveiller la performance du contexte ?
Surveiller la consommation de contexte est une pratique essentielle pour maintenir des sessions productives. Mesurez trois métriques clés : le taux de remplissage, la fréquence de compaction et le ratio tokens utiles/tokens totaux.
# Script de monitoring du contexte
#!/bin/bash
# monitor-context.sh
SESSION_ID=$1
while true; do
USAGE=$(claude --session-id $SESSION_ID --status | jq '.contextUsage')
echo "$(date): $USAGE tokens utilisés" >> context-monitor.log
sleep 60
done
Un taux de remplissage supérieur à 80 % pendant plus de 10 minutes indique qu'une compaction imminente va interrompre votre flux de travail. Anticipez en déclenchant /compact manuellement avec un prompt ciblé.
Pour consolider vos connaissances sur ces métriques, le guide d'optimisation du contexte de SFEIR fournit des tableaux de bord prêts à l'emploi.
Les indicateurs de santé d'une session se résument ainsi :
- Taux de remplissage < 70 % → session saine, continuez normalement
- Taux entre 70 et 85 % → planifiez une compaction manuelle ou un découpage en sous-tâches
- Taux > 85 % → déclenchez
/compactimmédiatement ou démarrez une nouvelle session - Plus de 3 compactions en 1 heure → votre tâche nécessite un scaling horizontal
En pratique, les développeurs formés chez SFEIR Institute atteignent un ratio de 85 % de tokens utiles contre 60 % en moyenne sans formation, soit un gain d'efficacité de 42 % sur les sessions longues.
À retenir : surveillez le taux de remplissage et déclenchez /compact avant 85 % - visez un ratio de tokens utiles supérieur à 80 %.
Articles récents sur Claude
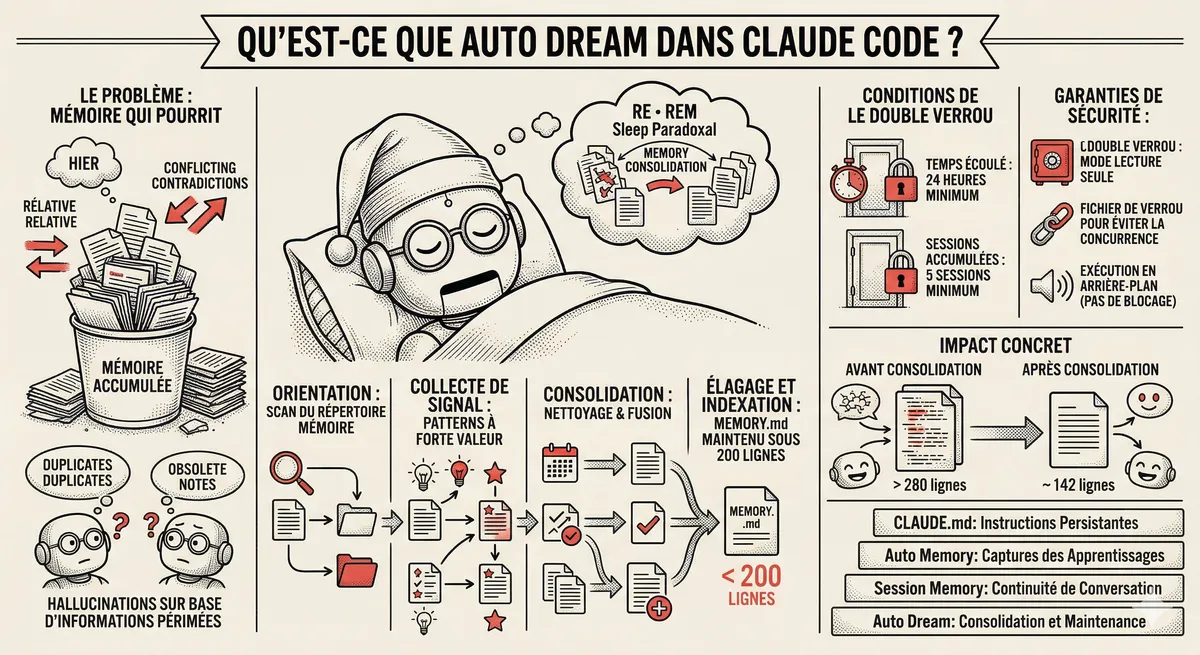
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
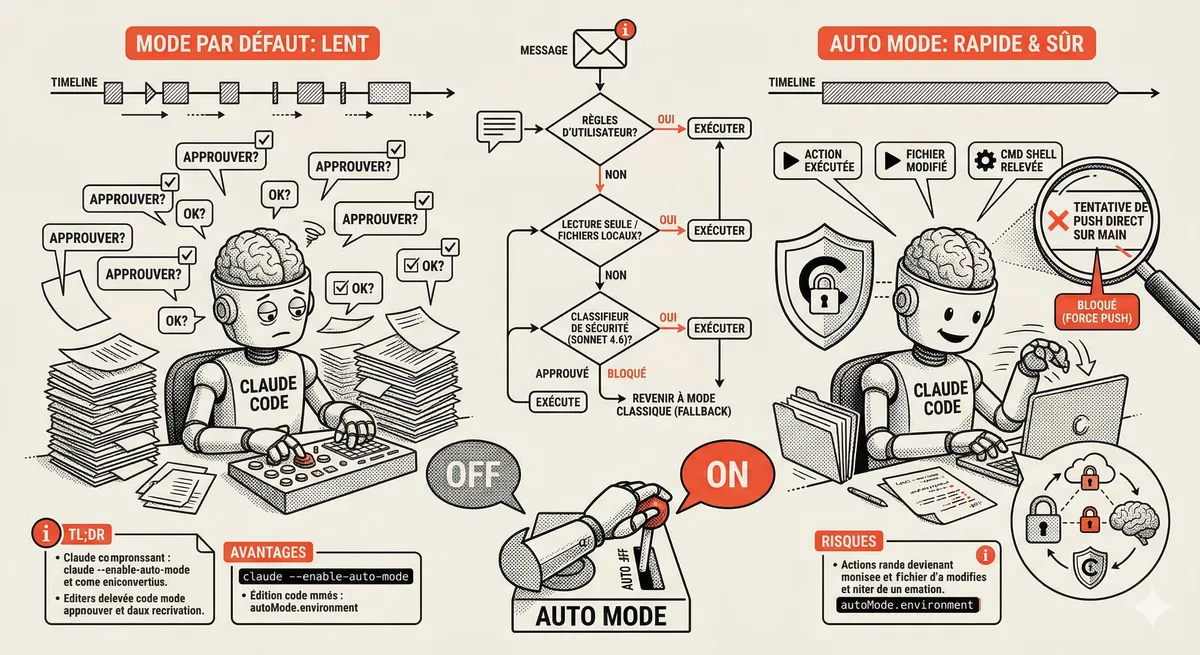
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
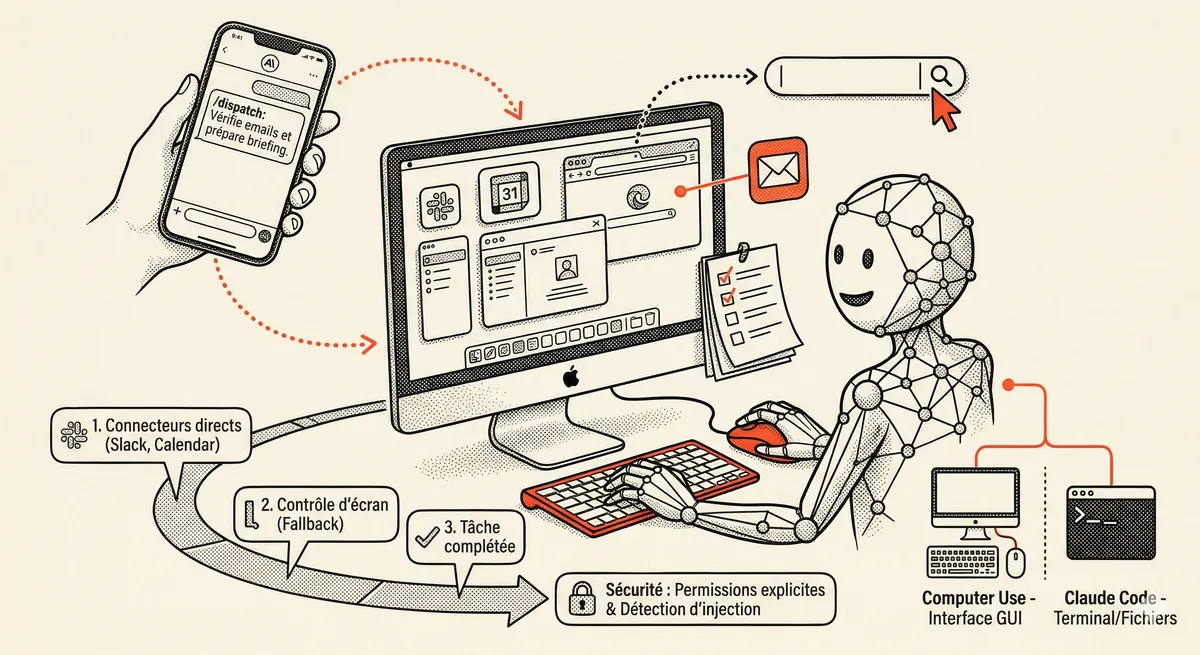
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Ce sujet est couvert dans le Module 4 de notre formation Claude Code
Documentation, organisation et gestion des prompts
Formation 1 jour • 60% labs pratiques • Formateurs experts
Voir le programme complet