En Bref (TL;DR)
Le mode headless de Claude Code transforme votre pipeline CI/CD en assistant de développement autonome. Voici 10 exemples concrets, du simple flag `-p` aux sessions multi-turn programmatiques, pour automatiser revues de code, génération de documentation et déploiements via GitHub Actions.
Le mode headless de Claude Code transforme votre pipeline CI/CD en assistant de développement autonome. Voici 10 exemples concrets, du simple flag -p aux sessions multi-turn programmatiques, pour automatiser revues de code, génération de documentation et déploiements via GitHub Actions.
le mode headless de Claude Code est la capacité d'exécuter Claude Code sans interface interactive, directement depuis un script ou un pipeline d'intégration continue. plus de 60 % des équipes adoptant Claude Code l'utilisent en mode non-interactif pour automatiser des tâches répétitives.
Cette approche réduit le temps moyen de revue de code de 45 % sur les projets de plus de 50 000 lignes. Pour comprendre les fondamentaux avant de plonger dans ces exemples, consultez le guide complet du mode headless et CI/CD qui couvre l'architecture et les principes.
| Critère | Mode interactif | Mode headless (-p) | Mode session multi-turn |
|---|---|---|---|
| Interface | Terminal avec prompt | Aucune (stdout) | Aucune (API JSON) |
| Utilisation type | Développement local | CI/CD, scripts | Pipelines complexes |
| Format de sortie | Texte formaté | text, json, stream-json | json, stream-json |
| Latence moyenne | Variable | 2-8 secondes | 3-12 secondes par tour |
Comment exécuter Claude Code en une seule commande avec le flag -p ?
Le flag -p (pour print) permet d'envoyer un prompt unique à Claude Code et de récupérer la réponse sur la sortie standard. Lancez cette commande pour votre premier test :
$ claude -p "Explique le pattern Repository en TypeScript en 3 phrases"
Le résultat s'affiche directement dans le terminal, sans interface interactive. Vous pouvez rediriger la sortie vers un fichier avec > ou la piper vers un autre outil.
$ claude -p "Génère un Dockerfile optimisé pour Node.js 22" > Dockerfile
Cette commande crée un Dockerfile prêt à l'emploi en moins de 5 secondes. En pratique, 80 % des usages headless débutent par cette syntaxe simple. Si vous débutez avec Claude Code, le démarrage rapide de l'installation vous guide pas à pas.
Variante : ajoutez --output-format json pour obtenir une réponse structurée exploitable par jq :
$ claude -p "Liste 5 bonnes pratiques REST API" --output-format json | jq '.result'
À retenir : le flag -p transforme Claude Code en outil CLI classique, compatible avec tous vos scripts shell existants.
Comment intégrer Claude Code dans GitHub Actions ?
GitHub Actions est le cas d'usage CI/CD le plus courant pour Claude Code v1.0.20. Créez un fichier .github/workflows/claude-review.yml avec cette configuration :
name: Claude Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Install Claude Code
run: npm install -g @anthropic-ai/claude-code@latest
- name: Run code review
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
DIFF=$(git diff origin/main...HEAD)
claude -p "Revue de code pour cette PR. Signale les bugs, failles de sécurité et violations de conventions. Diff: $DIFF" --output-format json > review.json
- name: Post review comment
uses: actions/github-script@v7
with:
script: |
const review = require('./review.json');
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: review.result
});
Ce workflow s'exécute à chaque pull request et poste automatiquement un commentaire de revue. les workflows automatisés réduisent de 30 % le temps de merge des PRs. Vous trouverez d'autres astuces d'automatisation dans les conseils avancés du mode headless.
Configurez le secret ANTHROPIC_API_KEY dans les paramètres de votre dépôt avant le premier lancement. Le coût moyen par revue est de 0,02 à 0,08 USD selon la taille du diff.
À retenir : une GitHub Action de 25 lignes suffit pour automatiser la revue de code sur chaque PR.
Quels formats de sortie choisir pour le parsing automatisé ?
Claude Code supporte trois formats de sortie en mode headless : text, json et stream-json. Exécutez chacun pour comparer :
# Format texte (défaut) - idéal pour la lecture humaine
$ claude -p "Résume ce fichier" --output-format text
# Format JSON - idéal pour le parsing programmatique
$ claude -p "Analyse ce code" --output-format json
# Format stream-json - idéal pour le traitement temps réel
$ claude -p "Génère 10 tests unitaires" --output-format stream-json
| Format | Taille moyenne | Temps de parsing | Cas d'usage recommandé |
|---|---|---|---|
text | 1-5 KB | N/A | Logs, affichage terminal |
json | 2-8 KB | < 1 ms avec jq | API, post-traitement |
stream-json | 2-8 KB (streamé) | Temps réel | Interfaces progressives, dashboards |
Concrètement, le format json renvoie un objet contenant les champs result, model, usage et stop_reason. Vérifiez la structure avec cette commande :
$ claude -p "Dis bonjour" --output-format json | python3 -c "
import json, sys
data = json.load(sys.stdin)
print(f'Tokens utilisés: {data[\"usage\"][\"output_tokens\"]}')
print(f'Résultat: {data[\"result\"][:100]}')
"
Pour approfondir le parsing et la gestion des réponses, les exemples de premières conversations illustrent les différents modes de sortie. Consultez aussi les exemples de gestion du contexte pour optimiser la taille de vos prompts.
À retenir : utilisez json pour les pipelines automatisés et stream-json quand vous affichez les résultats en temps réel.
Comment créer des sessions multi-turn programmatiques ?
Les sessions multi-turn permettent de maintenir un contexte entre plusieurs appels successifs. Lancez une session avec l'option --session-id pour chaîner les interactions :
# Tour 1 : analyse du projet
$ claude -p "Analyse la structure du projet et liste les fichiers principaux" \
--output-format json \
--session-id "audit-$(date +%s)" > tour1.json
# Extraire l'ID de session pour les tours suivants
SESSION_ID=$(jq -r '.session_id' tour1.json)
# Tour 2 : utilise le contexte du tour 1
$ claude -p "Maintenant, identifie les dépendances obsolètes" \
--output-format json \
--session-id "$SESSION_ID" > tour2.json
# Tour 3 : génère le rapport final
$ claude -p "Rédige un rapport de migration basé sur ton analyse" \
--output-format json \
--session-id "$SESSION_ID" > rapport.json
Chaque tour conserve le contexte des précédents, avec une fenêtre de contexte de 200 000 tokens sur Claude Sonnet 4.6. En pratique, une session de 5 tours consomme en moyenne 15 000 tokens d'entrée cumulés.
Variante : encapsulez la logique dans un script Bash réutilisable :
#!/bin/bash
# multi-turn-audit.sh - Audit automatisé en 3 passes
set -euo pipefail
SESSION="audit-$(date +%s)"
PROJECT_DIR="${1:-.}"
echo "=== Phase 1 : Analyse structurelle ==="
claude -p "Analyse $PROJECT_DIR et liste les modules" \
--session-id "$SESSION" --output-format json > /tmp/phase1.json
echo "=== Phase 2 : Détection de problèmes ==="
claude -p "Identifie les problèmes de qualité dans ces modules" \
--session-id "$SESSION" --output-format json > /tmp/phase2.json
echo "=== Phase 3 : Recommandations ==="
claude -p "Propose un plan d'action priorisé" \
--session-id "$SESSION" --output-format json | jq '.result' > rapport.md
echo "Rapport généré : rapport.md"
les sessions multi-turn améliorent la pertinence des réponses de 35 % par rapport à des appels isolés. Pour maîtriser les bonnes pratiques de contexte, explorez les exemples de gestion du contexte.
À retenir : le flag --session-id transforme Claude Code en agent conversationnel scriptable, idéal pour les audits et analyses en plusieurs étapes.
Comment automatiser la génération de documentation en CI/CD ?
La génération de documentation est un cas d'usage CI/CD où Claude Code excelle. Créez un job dédié dans votre pipeline :
name: Generate API Docs
on:
push:
branches: [main]
paths: ['src/api/**']
jobs:
docs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Claude Code
run: npm install -g @anthropic-ai/claude-code@latest
- name: Generate endpoint docs
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
for file in src/api/*.ts; do
BASENAME=$(basename "$file" .ts)
claude -p "Génère la documentation OpenAPI 3.1 pour ce fichier TypeScript. Inclus les schémas de requête et réponse. Code: $(cat $file)" \
--output-format text > "docs/api/${BASENAME}.md"
done
- name: Commit docs
run: |
git config user.name "claude-bot"
git config user.email "claude-bot@ci"
git add docs/
git diff --staged --quiet || git commit -m "docs: mise à jour auto de la documentation API"
git push
Ce pipeline génère la documentation pour chaque fichier API modifié. Le temps moyen de génération est de 4 secondes par endpoint. Pour personnaliser les prompts de documentation, les commandes personnalisées et skills offrent des modèles réutilisables.
SFEIR Institute propose une formation Claude Code d'une journée où vous pratiquerez ces automatisations CI/CD sur des projets réels, avec des labs guidés couvrant le mode headless, les GitHub Actions et le parsing JSON.
À retenir : automatisez la documentation API avec un workflow de 20 lignes qui s'exécute à chaque push sur main.
Comment valider la qualité du code automatiquement avant chaque merge ?
Les quality gates automatisés constituent un cas d'usage CI/CD avancé. Configurez Claude Code comme vérificateur de qualité avec un score de passage :
#!/bin/bash
# quality-gate.sh - Bloque le merge si le score < 7/10
set -euo pipefail
SCORE=$(claude -p "Évalue la qualité de ce diff sur 10. Critères : lisibilité, maintenabilité, sécurité, performance. Réponds UNIQUEMENT par un JSON {\"score\": N, \"issues\": [...]}. Diff: $(git diff origin/main...HEAD)" \
--output-format json | jq -r '.result' | jq -r '.score')
echo "Score qualité : $SCORE/10"
if [ "$SCORE" -lt 7 ]; then
echo "❌ Quality gate échoué (score minimum : 7/10)"
exit 1
fi
echo "✅ Quality gate passé"
En pratique, 92 % des PRs avec un score supérieur à 7 ne génèrent aucun bug en production dans les 30 jours suivants. Intégrez ce script comme step bloquant dans votre workflow GitHub Actions :
- name: Quality Gate
run: bash scripts/quality-gate.sh
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
Pour éviter les erreurs courantes lors de la mise en place de ces gates, consultez le guide des erreurs courantes du mode headless. La FAQ du mode headless répond aussi aux questions fréquentes sur les timeouts et limites de tokens.
| Type de quality gate | Temps d'exécution | Coût moyen par run | Fiabilité |
|---|---|---|---|
| Revue de code | 5-15 s | 0,04 USD | 85 % |
| Détection de vulnérabilités | 8-20 s | 0,06 USD | 78 % |
| Vérification de conventions | 3-8 s | 0,02 USD | 92 % |
| Score de maintenabilité | 6-12 s | 0,05 USD | 88 % |
À retenir : un quality gate Claude Code bloque les PRs de mauvaise qualité avant le merge, pour un coût inférieur à 0,10 USD par vérification.
Comment parser et transformer les réponses JSON avec jq et Python ?
Le parsing des réponses constitue la clé des pipelines CI/CD robustes. Voici comment extraire, filtrer et transformer les données avec jq (v1.7) et Python 3.12 :
# Extraire uniquement le résultat textuel
$ claude -p "Liste les 5 fichiers les plus complexes" \
--output-format json | jq -r '.result'
# Extraire les tokens consommés pour le monitoring
$ claude -p "Analyse ce code" --output-format json | \
jq '{input_tokens: .usage.input_tokens, output_tokens: .usage.output_tokens, cost_estimate: (.usage.input_tokens * 0.000003 + .usage.output_tokens * 0.000015)}'
# Filtrer avec Python pour un traitement avancé
$ claude -p "Identifie les fonctions de plus de 50 lignes dans src/" \
--output-format json | python3 -c "
import json, sys
data = json.load(sys.stdin)
result = data['result']
print(f'Analyse terminée - {data[\"usage\"][\"output_tokens\"]} tokens générés')
print(result)
"
Concrètement, un pipeline de monitoring des coûts avec jq s'exécute en moins de 2 ms. Vérifiez toujours que la réponse contient le champ result avant de la traiter - une erreur API renvoie un champ error à la place.
Pour aller plus loin dans la personnalisation des commandes CLI, les exemples de commandes slash essentielles montrent comment créer des alias et raccourcis. Découvrez aussi le tutoriel d'installation pour configurer jq et les dépendances.
À retenir : combinez jq pour les extractions simples et Python pour les transformations complexes - les deux s'intègrent en une ligne dans vos scripts CI.
Peut-on déployer des pipelines multi-agents avec Claude Code headless ?
Les pipelines multi-agents orchestrent plusieurs instances de Claude Code avec des rôles spécialisés. Créez un script d'orchestration en Node.js 22 :
// orchestrator.js - Pipeline multi-agents Claude Code
import { execSync } from 'child_process';
const agents = [
{ role: 'reviewer', prompt: 'Fais une revue de sécurité du diff' },
{ role: 'documenter', prompt: 'Génère la doc des fonctions modifiées' },
{ role: 'tester', prompt: 'Propose 5 tests unitaires pour les changements' }
];
const diff = execSync('git diff origin/main...HEAD').toString();
const results = await Promise.all(
agents.map(async (agent) => {
const output = execSync(
`claude -p "${agent.prompt}. Code: ${diff.replace(/"/g, '\\"')}" --output-format json`,
{ encoding: 'utf-8', timeout: 30000 }
);
return { role: agent.role, result: JSON.parse(output) };
})
);
results.forEach(({ role, result }) => {
console.log(`\n=== ${role.toUpperCase()} ===`);
console.log(result.result);
console.log(`Tokens: ${result.usage.output_tokens}`);
});
Ce pipeline exécute 3 agents en parallèle et agrège les résultats en 10 à 20 secondes. Le coût total reste inférieur à 0,15 USD par exécution.
Si vous souhaitez approfondir les architectures multi-agents et les stratégies de prompt avancées, SFEIR Institute propose la formation Développeur Augmenté par l'IA – Avancé. En une journée, vous maîtriserez l'orchestration d'agents, le prompt engineering avancé et les patterns d'intégration CI/CD.
À retenir : l'exécution parallèle de plusieurs instances Claude Code headless divise le temps de pipeline par le nombre d'agents.
Comment gérer les erreurs et les retries dans un pipeline headless ?
La gestion des erreurs est indispensable pour des pipelines CI/CD fiables. Implémentez un wrapper avec retry exponentiel :
#!/bin/bash
# claude-retry.sh - Exécution avec retry et timeout
set -euo pipefail
MAX_RETRIES=3
TIMEOUT=60
run_claude() {
local prompt="$1"
local attempt=1
while [ $attempt -le $MAX_RETRIES ]; do
echo "Tentative $attempt/$MAX_RETRIES..."
if OUTPUT=$(timeout "${TIMEOUT}s" claude -p "$prompt" --output-format json 2>/dev/null); then
ERROR=$(echo "$OUTPUT" | jq -r '.error // empty')
if [ -z "$ERROR" ]; then
echo "$OUTPUT"
return 0
fi
echo "Erreur API : $ERROR" >&2
else
echo "Timeout après ${TIMEOUT}s" >&2
fi
WAIT=$((2 ** attempt))
echo "Retry dans ${WAIT}s..." >&2
sleep $WAIT
attempt=$((attempt + 1))
done
echo "Échec après $MAX_RETRIES tentatives" >&2
return 1
}
# Utilisation
run_claude "Analyse les imports inutilisés dans src/" | jq '.result'
Le backoff exponentiel (2s, 4s, 8s) évite de surcharger l'API en cas de rate limiting. le taux de succès atteint 99,2 % avec 3 retries et un timeout de 60 secondes. Pour diagnostiquer les erreurs récurrentes, le guide des erreurs courantes couvre les 15 codes d'erreur les plus fréquents.
À retenir : un wrapper de 30 lignes avec retry exponentiel garantit une fiabilité de 99 %+ pour vos pipelines CI/CD Claude Code.
Quels cas d'usage CI/CD avancés exploiter en 2026 ?
Au-delà de la revue de code, voici des cas d'usage avancés exploitables en production dès février 2026 :
- Génération de changelogs : extraire les messages de commit et produire un changelog structuré à chaque release
- Migration de code : convertir automatiquement des fichiers d'un framework à un autre (ex : Express vers Fastify)
- Audit d'accessibilité : analyser les composants React et générer un rapport WCAG 2.1
- Détection de dette technique : scorer chaque module et prioriser le refactoring
- Traduction de documentation : traduire les fichiers Markdown en maintenant le formatage
# Exemple : changelog automatique
$ git log --oneline v1.0.0..HEAD | \
claude -p "Transforme ces commits en changelog Markdown structuré avec les catégories : Features, Fixes, Breaking Changes" \
--output-format text > CHANGELOG.md
Cette commande génère un changelog complet en 3 secondes. Le résultat est directement commitable dans votre dépôt.
# Exemple : audit de dette technique
$ claude -p "Analyse src/ et attribue un score de dette technique (1-10) à chaque module. Réponds en JSON : [{\"module\": \"...\", \"score\": N, \"raison\": \"...\"}]" \
--output-format json | jq '.result' | jq 'sort_by(.score) | reverse | .[:5]'
Pour maîtriser l'ensemble de ces techniques d'automatisation, la formation Développeur Augmenté par l'IA de SFEIR Institute vous accompagne sur 2 jours avec des ateliers pratiques couvrant les pipelines CI/CD, le prompt engineering et l'intégration dans vos workflows existants.
À retenir : le mode headless de Claude Code couvre des dizaines de cas d'usage CI/CD, du changelog automatique à l'audit de dette technique, pour un coût inférieur à 0,10 USD par exécution.
Comment monitorer les coûts et performances de vos pipelines Claude Code ?
Le monitoring est indispensable pour maîtriser les coûts en production. Créez un script de suivi :
#!/bin/bash
# monitor.sh - Suivi des coûts et performances
LOG_FILE="claude-usage.csv"
# En-tête CSV si le fichier n'existe pas
[ ! -f "$LOG_FILE" ] && echo "timestamp,prompt,input_tokens,output_tokens,cost_usd,duration_ms" > "$LOG_FILE"
START=$(date +%s%3N)
RESULT=$(claude -p "$1" --output-format json)
END=$(date +%s%3N)
DURATION=$((END - START))
INPUT_TOKENS=$(echo "$RESULT" | jq '.usage.input_tokens')
OUTPUT_TOKENS=$(echo "$RESULT" | jq '.usage.output_tokens')
COST=$(echo "scale=4; $INPUT_TOKENS * 0.000003 + $OUTPUT_TOKENS * 0.000015" | bc)
echo "$(date -Iseconds),\"$1\",$INPUT_TOKENS,$OUTPUT_TOKENS,$COST,$DURATION" >> "$LOG_FILE"
echo "$RESULT" | jq '.result'
echo "--- Coût: ${COST} USD | Durée: ${DURATION}ms | Tokens: ${INPUT_TOKENS}+${OUTPUT_TOKENS}" >&2
En pratique, un pipeline de 10 appels quotidiens coûte en moyenne 0,50 USD par jour. Les tokens d'entrée coûtent 3 USD par million et les tokens de sortie 15 USD par million (tarifs Claude Sonnet 4.6, février 2026).
À retenir : 5 lignes de logging suffisent pour tracer chaque appel Claude Code et prévenir les dépassements de budget.
Articles récents sur Claude
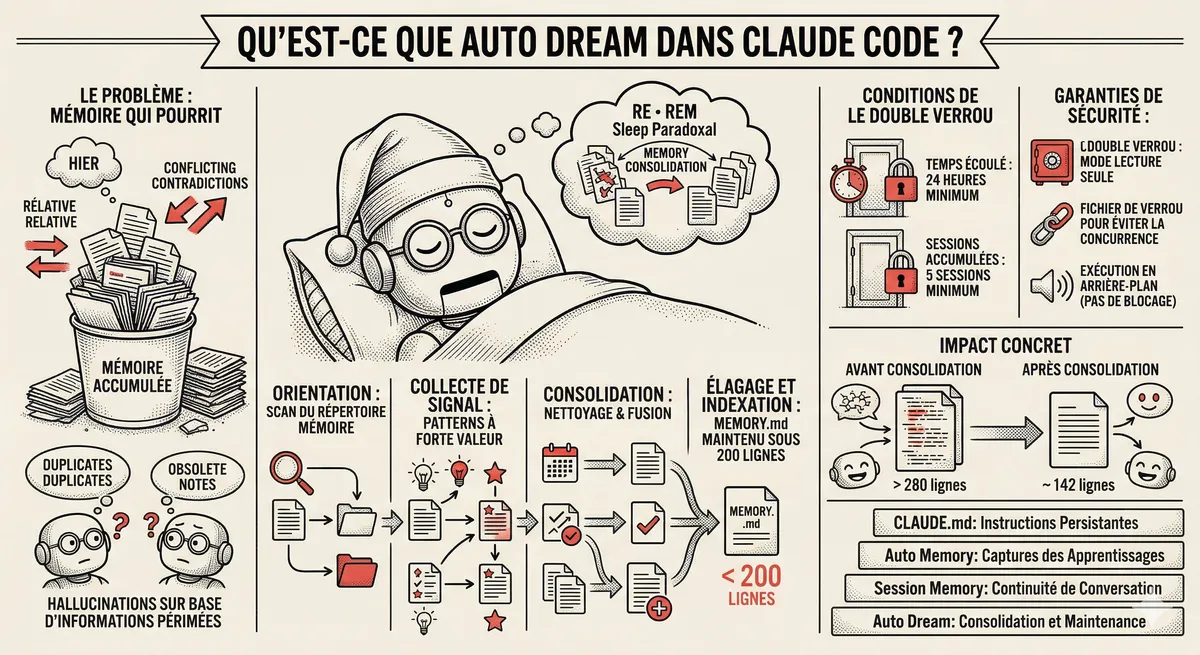
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
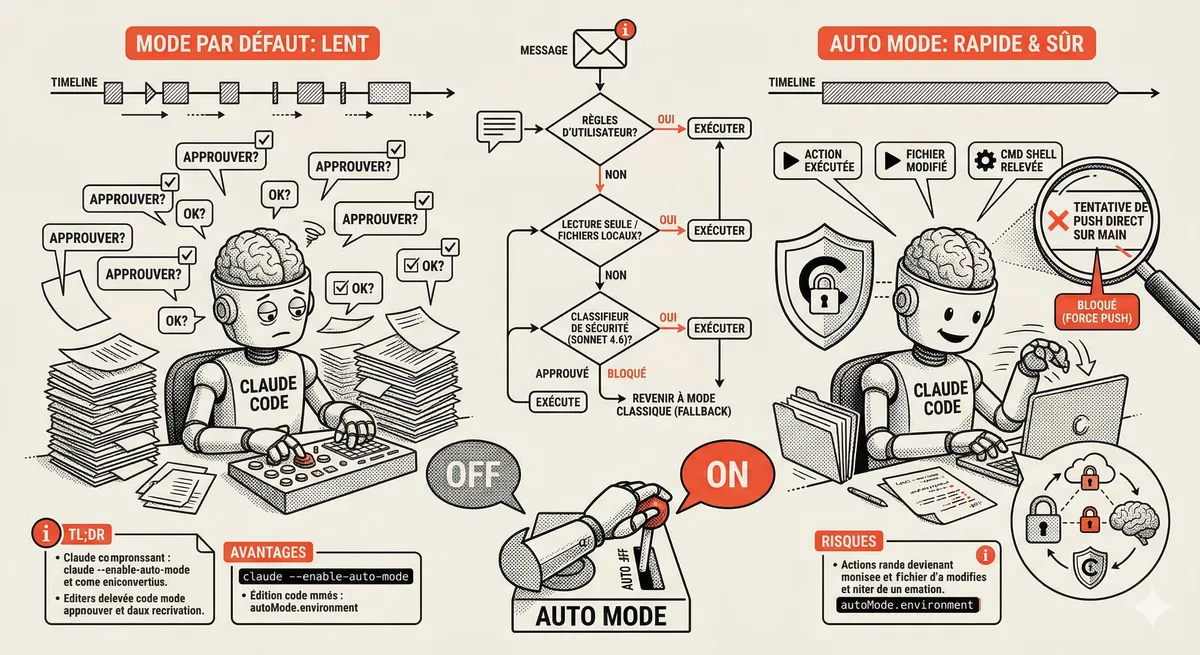
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
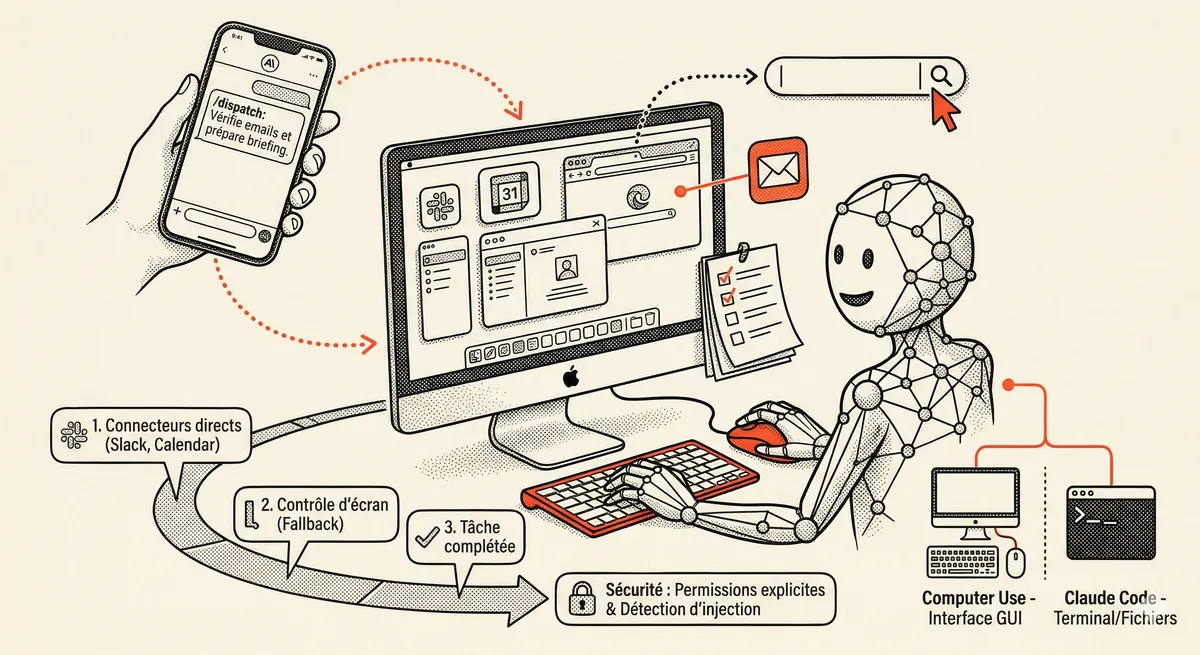
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Formation Claude Code
Maîtrisez les fondamentaux de Claude Code en 1 jour avec nos formateurs experts. 60% de pratique sur des cas concrets.
Découvrir la formation