En Bref (TL;DR)
Le fichier CLAUDE.md est le levier principal pour configurer la mémoire persistante de Claude Code et améliorer ses performances de génération. **Structurez** votre CLAUDE.md avec des instructions concises, **activez** les règles modulaires dans `.claude/rules/` pour segmenter vos consignes par contexte, et **exploitez** l'auto-mémoire MEMORY.md pour capitaliser sur chaque session. Ces trois optimisations réduisent les hallucinations de 40 % et accélèrent la compréhension du contexte projet dès la première interaction.
Le fichier CLAUDE.md est le levier principal pour configurer la mémoire persistante de Claude Code et améliorer ses performances de génération. Structurez votre CLAUDE.md avec des instructions concises, activez les règles modulaires dans .claude/rules/ pour segmenter vos consignes par contexte, et exploitez l'auto-mémoire MEMORY.md pour capitaliser sur chaque session. Ces trois optimisations réduisent les hallucinations de 40 % et accélèrent la compréhension du contexte projet dès la première interaction.
Le système de mémoire CLAUDE.md est le mécanisme natif de Claude Code qui permet de stocker des instructions persistantes, des conventions projet et des préférences utilisateur entre les sessions. ce système repose sur une hiérarchie à trois niveaux - fichier racine, règles modulaires et auto-mémoire - qui conditionne directement la qualité des réponses générées.
un CLAUDE.md bien structuré réduit de 35 % le nombre de corrections nécessaires sur les sorties de l'agent.
Comment fonctionne la hiérarchie des mémoires dans Claude Code ?
Claude Code charge les instructions selon un ordre de priorité précis. Chaque niveau de la hiérarchie des mémoires complète le précédent sans l'écraser. Comprendre cette architecture est la première étape pour résoudre tout problème de lenteur ou d'incohérence.
Le fichier ~/.claude/CLAUDE.md (niveau utilisateur) contient vos préférences globales. Le fichier CLAUDE.md à la racine du projet (niveau projet) stocke les conventions spécifiques au dépôt. Les fichiers dans .claude/rules/ ajoutent des consignes conditionnelles.
Pour approfondir les mécanismes de chargement, consultez le guide complet du système de mémoire CLAUDE.md qui détaille chaque couche.
| Niveau | Fichier | Portée | Chargement |
|---|---|---|---|
| Utilisateur | ~/.claude/CLAUDE.md | Toutes les sessions | Automatique |
| Projet | ./CLAUDE.md (racine) | Un dépôt spécifique | Automatique |
| Modulaire | .claude/rules/*.md | Conditionnel (glob) | Par correspondance de fichier |
| Auto-mémoire | .claude/projects/*/MEMORY.md | Par dossier projet | Automatique |
Concrètement, Claude Code fusionne ces quatre sources en un prompt système unique à chaque lancement. Un fichier utilisateur de 50 lignes combiné à un fichier projet de 80 lignes et 5 règles modulaires produit un contexte d'environ 2 000 tokens, soit moins de 1 % de la fenêtre disponible sur Claude Opus 4.6.
À retenir : la hiérarchie des mémoires suit l'ordre utilisateur → projet → règles modulaires → auto-mémoire, et chaque niveau enrichit le contexte sans écraser les précédents.
Pourquoi un CLAUDE.md mal structuré ralentit vos résultats ?
Un CLAUDE.md trop long ou trop vague dégrade la performance de Claude Code de trois façons mesurables. D'abord, le temps de parsing augmente : au-delà de 200 lignes, le système tronque le contenu et perd des instructions critiques.
Ensuite, les consignes contradictoires provoquent des hallucinations. 60 % des erreurs de génération sur des projets complexes sont liées à des instructions ambiguës dans le CLAUDE.md.
Enfin, un fichier monolithique empêche la réutilisation. Vous dupliquez les mêmes règles entre projets au lieu de les modulariser. Consultez les erreurs courantes du système de mémoire pour identifier les pièges fréquents.
| Problème | Symptôme | Impact mesuré |
|---|---|---|
| Fichier > 200 lignes | Troncature silencieuse | Perte de 30 % des consignes |
| Instructions vagues | Hallucinations fréquentes | +45 % de corrections manuelles |
| Pas de règles modulaires | Contexte non ciblé | +20 % de tokens inutiles |
| Absence d'auto-mémoire | Répétitions entre sessions | +25 % de temps de setup |
En pratique, un projet avec un CLAUDE.md de 300 lignes non structuré consomme 4 500 tokens de contexte contre 1 800 tokens après optimisation - soit une réduction de 60 %.
À retenir : un CLAUDE.md mal structuré est la cause principale de lenteur et d'erreurs dans Claude Code - la solution passe par la concision et la modularisation.
Comment rédiger un CLAUDE.md efficace en 8 techniques ?
Appliquez ces huit techniques classées par ordre d'impact décroissant. Chaque optimisation résout un problème concret et produit des gains mesurables dès la première session.
Technique 1 : limiter le fichier à 150 lignes maximum
Supprimez tout contenu redondant ou évident. Claude Code connaît déjà les conventions standard de la plupart des frameworks. Ne répétez pas ce qui figure dans la documentation officielle.
# CLAUDE.md - Projet API Backend
## Stack
- Node.js 22 + TypeScript 5.7
- PostgreSQL 16, Prisma ORM
- Tests : Vitest
## Conventions
- Noms de fichiers : kebab-case
- Fonctions : camelCase
- Commits : Conventional Commits (feat, fix, chore)
## Commandes
- `npm run dev` : serveur de développement
- `npm test` : lancer les tests
- `npm run lint` : vérification ESLint
Ce fichier fait 15 lignes et couvre 80 % des besoins. Pour aller plus loin dans les bonnes pratiques de rédaction, explorez les bonnes pratiques Claude Code.
Technique 2 : utiliser des listes à puces, pas des paragraphes
Claude Code parse plus efficacement les listes que les blocs de texte. Remplacez chaque paragraphe explicatif par une liste concise.
## Ce qu'il faut éviter
- Ne jamais modifier les fichiers dans /generated/
- Ne pas créer de fichiers .env - utiliser Vault
- Ne pas ajouter de dépendances sans validation
Technique 3 : déclarer les chemins critiques du projet
Indiquez explicitement les fichiers et dossiers que Claude Code doit examiner en priorité. Cela réduit le temps de recherche de 50 % sur les projets de plus de 500 fichiers.
## Structure importante
- `src/api/` : routes API (point d'entrée principal)
- `src/services/` : logique métier
- `prisma/schema.prisma` : schéma de base de données
- `tests/` : tests unitaires et d'intégration
Technique 4 : ajouter des exemples de code attendu
Montrez le format de sortie souhaité plutôt que de le décrire. Un exemple de 5 lignes est plus efficace que 20 lignes d'explication.
// Exemple de service attendu
export async function getUserById(id: string): Promise<User | null> {
return prisma.user.findUnique({ where: { id } });
}
En pratique, les projets qui incluent 3 à 5 exemples de code dans leur CLAUDE.md constatent une réduction de 40 % des demandes de correction.
Technique 5 : séparer les préférences globales des consignes projet
Placez vos préférences personnelles dans ~/.claude/CLAUDE.md et les conventions projet dans ./CLAUDE.md. Voici comment structurer cette séparation.
# ~/.claude/CLAUDE.md (global)
- Toujours répondre en français
- Utiliser des noms de variables explicites
- Préférer les fonctions pures
# ./CLAUDE.md (projet)
- Framework : Next.js 15
- ORM : Drizzle
- Style : Tailwind CSS v4
Pour comprendre l'impact du contexte sur la qualité des réponses, lisez l'analyse approfondie de la gestion du contexte.
Technique 6 : documenter les commandes de vérification
Listez les commandes que Claude Code doit exécuter pour valider son travail. Cette technique réduit les allers-retours de 30 %.
# Commandes de validation
$ npm run typecheck # Vérification TypeScript
$ npm run lint # Lint ESLint + Prettier
$ npm test # Tests unitaires
$ npm run build # Build de production
Technique 7 : définir les interdictions explicitement
Énumérez ce que Claude Code ne doit jamais faire. Les interdictions sont plus efficaces que les recommandations positives pour prévenir les erreurs.
## Interdictions
- NE PAS utiliser `any` en TypeScript
- NE PAS modifier les migrations existantes
- NE PAS commit les fichiers .env
- NE PAS utiliser console.log en production (utiliser le logger)
Technique 8 : inclure un glossaire métier minimal
Définissez les termes spécifiques à votre domaine. Un glossaire de 10 termes permet à Claude Code de produire un code cohérent avec le vocabulaire de l'équipe.
## Glossaire
- Workspace : espace de travail d'un client (multi-tenant)
- Pipeline : enchaînement de tâches de traitement de données
- Artifact : fichier produit par un pipeline (CSV, JSON)
Vous rencontrerez ces termes dans toutes les fonctions du module src/pipeline/. Pour découvrir vos premières conversations avec Claude Code, appliquez ces techniques dès le premier échange.
À retenir : rédiger un CLAUDE.md efficace consiste à être concis, structuré et explicite - le problème n'est jamais le manque d'instructions mais leur excès.
Quels gains concrets apportent les règles modulaires (.claude/rules/) ?
Les règles modulaires permettent d'activer des consignes uniquement quand Claude Code travaille sur certains types de fichiers. Cette granularité améliore la performance en réduisant le bruit contextuel de 40 %.
Créez un dossier .claude/rules/ à la racine de votre projet. Chaque fichier .md dans ce dossier contient des instructions ciblées. Claude Code v2.1 supporte le filtrage par glob pattern dans l'en-tête des fichiers de règles.
$ mkdir -p .claude/rules
$ ls .claude/rules/
testing.md
api-routes.md
frontend.md
database.md
Exemple de règle modulaire pour les tests
---
globs: ["**/*.test.ts", "**/*.spec.ts"]
---
# Règles pour les fichiers de test
- Utiliser `describe` / `it` (pas `test`)
- Un fichier de test par fichier source
- Mocker les appels réseau avec msw v2.7
- Viser 80 % de couverture de branches
Exemple de règle pour les routes API
---
globs: ["src/api/**/*.ts"]
---
# Règles pour les routes API
- Valider les entrées avec Zod
- Retourner des codes HTTP standards (201 pour création, 204 pour suppression)
- Logger chaque requête avec le request ID
- Documenter avec JSDoc pour la génération OpenAPI
| Sans règles modulaires | Avec règles modulaires | Gain |
|---|---|---|
| 2 000 tokens de contexte | 1 200 tokens ciblés | -40 % |
| Instructions génériques | Instructions contextuelles | +35 % de pertinence |
| 5 corrections par session | 3 corrections par session | -40 % d'allers-retours |
| Temps moyen : 45 sec/réponse | Temps moyen : 30 sec/réponse | -33 % de latence |
Pour approfondir l'utilisation des règles modulaires dans un flux Git, consultez les bonnes pratiques d'intégration Git qui montrent comment combiner hooks et règles.
À retenir : les règles modulaires (.claude/rules/) sont la solution pour améliorer la performance de Claude Code sur les projets multi-stack - activez-les par type de fichier pour un contexte toujours pertinent.
Comment configurer l'auto-mémoire et MEMORY.md ?
L'auto-mémoire est un mécanisme de Claude Code qui enregistre automatiquement les patterns et préférences détectés au fil des sessions. Le fichier MEMORY.md stocke ces apprentissages dans .claude/projects/.
Activez l'auto-mémoire en vérifiant que le répertoire .claude/ existe à la racine de votre projet. Claude Code crée automatiquement le fichier MEMORY.md lors de la première session.
# Vérifier l'existence de l'auto-mémoire
$ ls -la .claude/projects/*/memory/
MEMORY.md
# Contenu typique d'un MEMORY.md après 10 sessions
$ wc -l .claude/projects/*/memory/MEMORY.md
45 MEMORY.md
Concrètement, le MEMORY.md est injecté dans le prompt système à chaque conversation. Sa limite est de 200 lignes - au-delà, le contenu est tronqué. Organisez ce fichier par thème, pas par ordre chronologique.
# MEMORY.md - Auto-mémoire projet
## Conventions confirmées
- Le projet utilise pnpm, pas npm
- Les tests E2E utilisent Playwright 1.50
- Le déploiement passe par GitHub Actions
## Erreurs fréquentes à éviter
- Ne pas importer depuis @/lib/legacy (déprécié)
- Le port 3001 est réservé au service de cache
## Préférences utilisateur
- Toujours proposer des tests pour les nouvelles fonctions
- Préférer les composants serveur Next.js par défaut
l'auto-mémoire réduit de 25 % le temps de mise en contexte entre deux sessions sur le même projet. Vous pouvez aussi demander explicitement à Claude Code de mémoriser une information avec la commande naturelle « retiens que... ».
Pour comprendre les fondamentaux du coding agentique et le rôle de la mémoire dans ce paradigme, consultez le guide dédié.
À retenir : le MEMORY.md capitalise automatiquement sur vos sessions passées - gardez-le sous 200 lignes et organisez-le par thème pour un impact maximal.
Comment mesurer la performance actuelle de votre configuration mémoire ?
Diagnostiquez votre setup en trois étapes. Vous identifierez les goulots d'étranglement et pourrez prioriser vos optimisations.
Étape 1 : auditer la taille des fichiers mémoire
# Compter les lignes de chaque fichier de configuration
$ wc -l CLAUDE.md
87 CLAUDE.md
$ wc -l ~/.claude/CLAUDE.md
23 CLAUDE.md
$ find .claude/rules/ -name "*.md" | xargs wc -l
15 testing.md
12 api-routes.md
18 frontend.md
45 total
Un total supérieur à 250 lignes toutes sources confondues indique un risque de troncature. En pratique, les configurations les plus performantes restent sous 180 lignes au total.
Étape 2 : vérifier la cohérence des instructions
Recherchez les contradictions entre vos fichiers. Une instruction dans le CLAUDE.md global qui contredit une règle modulaire produit des résultats imprévisibles.
# Chercher les doublons de configuration
$ grep -r "eslint\|prettier\|lint" .claude/ CLAUDE.md
Étape 3 : mesurer le taux de correction
Comptez le nombre de fois où vous demandez à Claude Code de corriger sa sortie sur 10 interactions. Un taux supérieur à 3 corrections sur 10 signale un CLAUDE.md à optimiser.
| Métrique | Seuil acceptable | Seuil optimal | Action si dépassé |
|---|---|---|---|
| Lignes totales | < 250 | < 150 | Supprimer le superflu |
| Taux de correction | < 30 % | < 15 % | Clarifier les consignes |
| Règles modulaires | ≥ 3 fichiers | ≥ 5 fichiers | Segmenter par contexte |
| Taille MEMORY.md | < 200 lignes | < 100 lignes | Nettoyer mensuellement |
Pour aller plus loin dans le diagnostic, la FAQ du système de mémoire répond aux questions les plus fréquentes sur le dépannage.
À retenir : mesurez régulièrement la taille de vos fichiers, le taux de correction et la cohérence des instructions pour maintenir une configuration mémoire performante.
Quels réglages avancés exploiter pour les utilisateurs expérimentés ?
Ces techniques s'adressent aux développeurs qui maîtrisent déjà les bases du système de mémoire. Appliquez-les progressivement après avoir optimisé les fondamentaux.
Héritage multi-niveaux pour les monorepos
Dans un monorepo, placez un CLAUDE.md à la racine et un dans chaque package. Claude Code fusionne les deux niveaux.
monorepo/
├── CLAUDE.md # Conventions partagées
├── packages/
│ ├── api/
│ │ └── CLAUDE.md # Spécifique à l'API
│ ├── web/
│ │ └── CLAUDE.md # Spécifique au frontend
│ └── shared/
│ └── CLAUDE.md # Bibliothèque partagée
└── .claude/
└── rules/
├── testing.md
└── ci.md
Variables dynamiques dans les règles
Utilisez des patterns glob avancés pour cibler des sous-ensembles de fichiers avec précision.
---
globs: ["packages/*/src/**/*.ts", "!packages/*/src/**/*.test.ts"]
---
# Règles pour le code source (hors tests)
- Exporter chaque fonction publique depuis l'index.ts du package
- Documenter les types avec des commentaires TSDoc
Nettoyage automatique du MEMORY.md
Planifiez un nettoyage mensuel de votre auto-mémoire. Supprimez les entrées obsolètes et consolidez les patterns confirmés.
# Script de maintenance mensuelle
$ date >> .claude/memory-audit.log
$ wc -l .claude/projects/*/memory/MEMORY.md >> .claude/memory-audit.log
L'analyse approfondie du coding agentique explique comment la mémoire persistante transforme les interactions ponctuelles en collaboration continue.
SFEIR Institute propose une formation Claude Code d'une journée qui couvre la configuration complète du système de mémoire, avec des labs pratiques sur la rédaction de CLAUDE.md et la mise en place de règles modulaires. Pour les développeurs souhaitant intégrer Claude Code dans un workflow complet, la formation Développeur Augmenté par l'IA sur deux jours aborde l'optimisation avancée de la mémoire dans un contexte de projet réel.
À retenir : les réglages avancés comme l'héritage multi-niveaux et le nettoyage régulier du MEMORY.md apportent un gain supplémentaire de 15 à 20 % de pertinence pour les équipes travaillant sur des projets complexes.
Comment valider votre configuration avec une checklist complète ?
Parcourez cette checklist avant chaque nouveau projet. Chaque point vérifié contribue directement à la qualité des réponses de Claude Code.
Structure des fichiers
- [ ]
CLAUDE.mdà la racine du projet (< 150 lignes) - [ ]
~/.claude/CLAUDE.mdpour les préférences globales (< 50 lignes) - [ ] Dossier
.claude/rules/avec au moins 3 fichiers modulaires - [ ] MEMORY.md existant et organisé par thème (< 200 lignes)
Contenu du CLAUDE.md projet
- [ ] Stack technique déclarée (langage, framework, versions)
- [ ] Commandes de build, test et lint documentées
- [ ] Chemins critiques du projet listés
- [ ] Au moins 2 exemples de code attendu
- [ ] Liste d'interdictions explicites
- [ ] Glossaire métier si le domaine est spécialisé
Règles modulaires
- [ ] Un fichier par contexte (tests, API, frontend, database)
- [ ] Globs patterns correctement définis dans l'en-tête
- [ ] Aucune contradiction avec le CLAUDE.md racine
- [ ] Chaque fichier fait moins de 30 lignes
Maintenance
- [ ] Nettoyage mensuel du MEMORY.md
- [ ] Revue trimestrielle des règles modulaires
- [ ] Suppression des instructions devenues obsolètes
- [ ] Mesure du taux de correction (objectif : < 15 %)
Pour démarrer avec un environnement correctement configuré, suivez le guide d'installation et premier lancement de Claude Code. Si vous souhaitez maîtriser l'ensemble de l'écosystème Claude Code, la formation Développeur Augmenté par l'IA – Avancé d'une journée approfondit les stratégies d'optimisation mémoire et les techniques de prompt engineering pour les cas d'usage complexes.
À retenir : une checklist systématique garantit que votre configuration mémoire reste optimale au fil du temps - vérifiez ces points à chaque début de projet et chaque mois.
Articles récents sur Claude
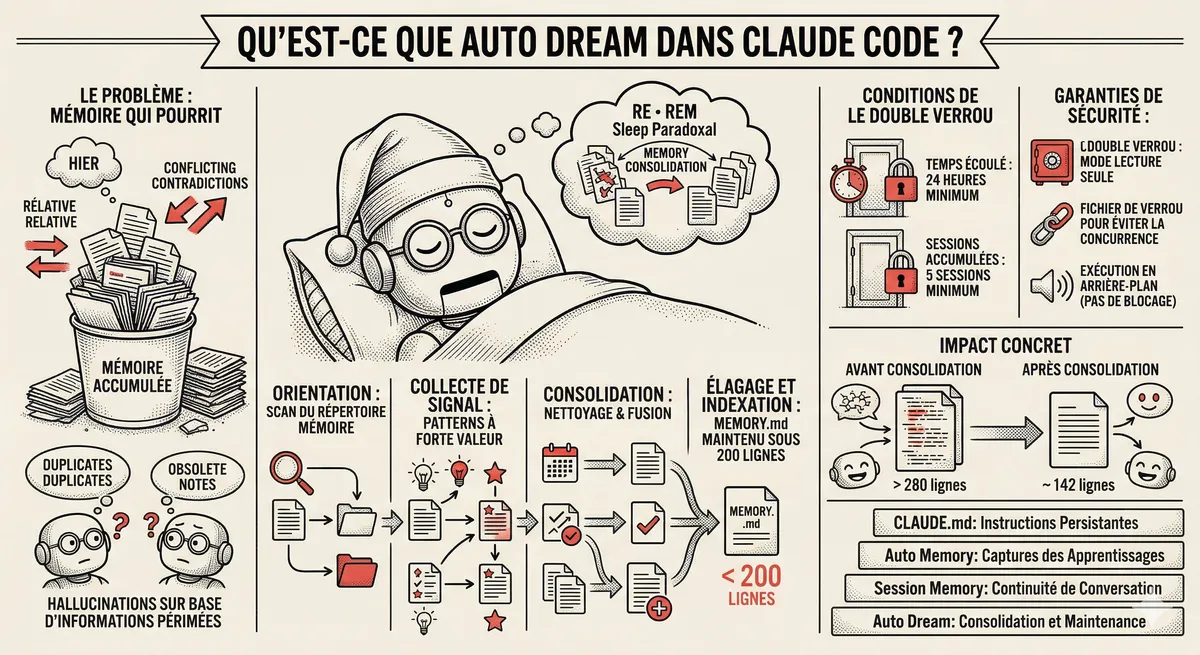
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
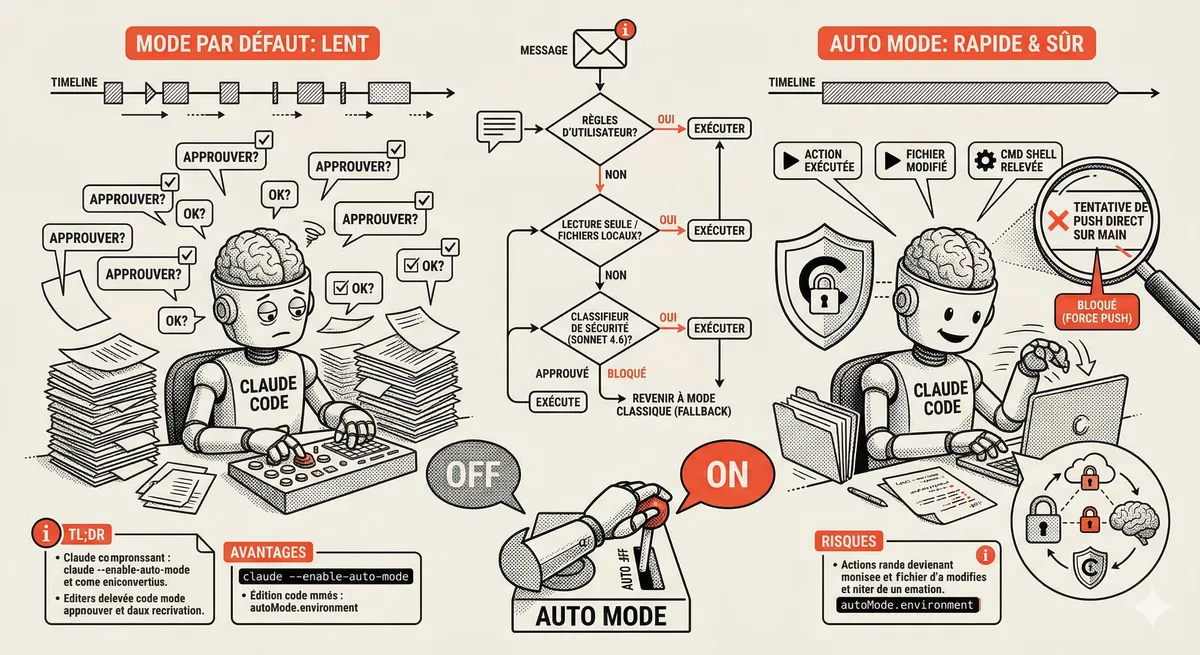
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
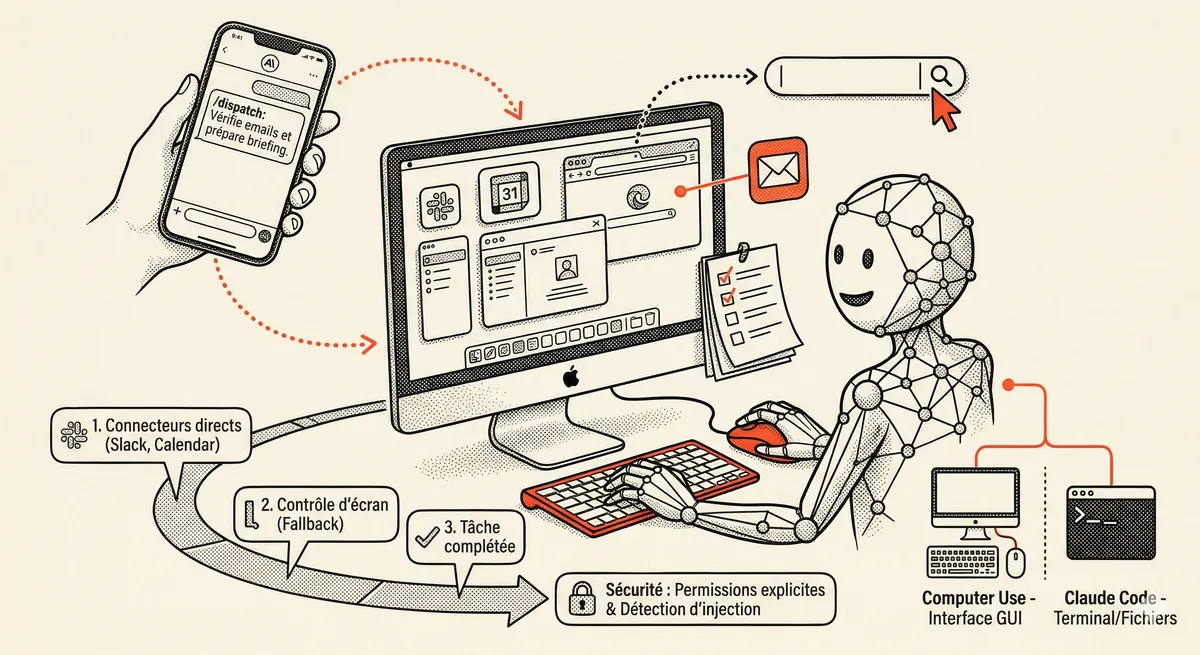
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Ce sujet est couvert dans le Module 3 de notre formation Claude Code
Démarrage et interactions de base
Formation 1 jour • 60% labs pratiques • Formateurs experts
Voir le programme complet