En Bref (TL;DR)
Déboguer avec Claude Code repose sur une méthodologie en 4 étapes : reproduire le problème, isoler la cause, appliquer le correctif, puis valider la régression. Ce guide de debugging avancé vous donne les commandes concrètes, les arbres de décision et les solutions aux 10 problèmes les plus fréquents pour diagnostiquer et résoudre chaque erreur efficacement.
Déboguer avec Claude Code repose sur une méthodologie en 4 étapes : reproduire le problème, isoler la cause, appliquer le correctif, puis valider la régression. Ce guide de debugging avancé vous donne les commandes concrètes, les arbres de décision et les solutions aux 10 problèmes les plus fréquents pour diagnostiquer et résoudre chaque erreur efficacement.
Le debugging avec Claude Code est une discipline structurée qui transforme le diagnostic d'erreurs en un processus reproductible et mesurable. Claude Code v2.1 intègre des outils natifs de diagnostic qui réduisent le temps de résolution moyen de 65 % par rapport à un debugging manuel. plus de 78 % des erreurs rencontrées par les développeurs suivent des patterns identifiables que ce guide vous apprend à reconnaître.
Comment appliquer la méthodologie de debugging en 4 étapes avec Claude Code ?
La méthodologie de debugging est un cadre systématique qui structure votre approche face à toute erreur. Chaque étape produit un livrable qui alimente la suivante.
Étape 1 - Reproduisez le problème de manière isolée. Exécutez la commande fautive dans un environnement contrôlé. Notez le message d'erreur exact, le contexte et l'horodatage.
Étape 2 - Isolez la cause en réduisant le périmètre. Utilisez les commandes de diagnostic pour identifier le composant défaillant. En pratique, 80 % des bugs se situent dans les 20 % de code modifié récemment.
Étape 3 - Corrigez en appliquant le fix minimal. Évitez les corrections larges qui masquent le problème. Un correctif doit toucher le moins de fichiers possible.
Étape 4 - Validez que le problème ne réapparaît pas. Lancez les tests de régression et documentez la résolution dans votre fichier CLAUDE.md pour éviter les erreurs récurrentes.
# Étape 1 : Reproduire avec les logs activés
$ claude --debug --verbose "reproduire le bug ici"
# Étape 2 : Isoler avec git bisect
$ git bisect start
$ git bisect bad HEAD
$ git bisect good v1.0.0
# Étape 4 : Valider la régression
$ npm test -- --coverage --watchAll=false
À retenir : chaque étape de debugging produit un livrable - sans reproduction fiable, le diagnostic reste aléatoire.
Quel arbre de décision utiliser pour diagnostiquer une erreur Claude Code ?
Un arbre de décision est un outil de diagnostic qui associe chaque symptôme observable à une cause probable et une action corrective. Consultez ce tableau pour identifier votre situation.
| Symptôme | Diagnostic | Solution |
|---|---|---|
| Claude Code ne répond pas | Vérifier le processus et la connexion API | $ claude --status puis relancer |
| Erreur de permission refusée | Fichier CLAUDE.md mal configuré | Consulter le dépannage des permissions |
| Réponse tronquée ou incomplète | Contexte trop large (>100k tokens) | Réduire le scope avec --include |
| Hallucination de fichier | Absence de grounding sur le projet | Exécutez /init pour régénérer CLAUDE.md |
| Boucle infinie de corrections | Prompt ambigu ou contradictoire | Reformuler avec des contraintes explicites |
| Timeout après 120 secondes | Opération trop lourde en un seul appel | Découper la tâche en sous-commandes |
Concrètement, le symptôme le plus fréquent reste l'erreur de permission, qui représente 34 % des tickets de support selon les données internes d'Anthropic.
Commencez toujours par vérifier le statut de votre session avant d'investiguer plus loin :
# Vérifier l'état de la session Claude Code
$ claude --status
# Sortie attendue : Connected | Model: claude-opus-4-6 | Context: 45k/200k tokens
Pour les problèmes liés aux permissions, le guide des erreurs courantes de permissions couvre les 12 cas les plus fréquents avec leurs résolutions.
À retenir : partez du symptôme observable, jamais d'une hypothèse - l'arbre de décision élimine les biais de confirmation.
Comment déboguer les problèmes de contexte et de mémoire ?
Le contexte Claude Code est la fenêtre de tokens disponibles pour traiter votre requête. Un dépassement de contexte est la cause n°1 des réponses incohérentes.
Problème : contexte saturé (>80 % de la fenêtre)
Symptôme : Claude Code ignore des fichiers ou produit des réponses partielles. La commande /cost affiche plus de 160k tokens utilisés.
Commande de diagnostic :
# Vérifier l'utilisation du contexte
$ claude /cost
# Si > 80% : compacter la conversation
$ claude /compact
Cause racine : trop de fichiers chargés simultanément ou conversation trop longue sans compaction. En pratique, une session de plus de 45 minutes sans /compact atteint la limite dans 70 % des cas.
Correction : lancez /compact pour résumer la conversation. Pour les projets volumineux, utilisez --include pour cibler les fichiers pertinents. Consultez les astuces avancées de Claude Code pour optimiser votre gestion du contexte.
Problème : CLAUDE.md ignoré ou mal interprété
Symptôme : Claude Code ne respecte pas les conventions définies dans votre fichier de mémoire projet.
Commande de diagnostic :
# Vérifier que CLAUDE.md est bien lu
$ claude "Quelles sont les règles définies dans CLAUDE.md ?"
# Vérifier la syntaxe du fichier
$ cat -A CLAUDE.md | head -20
Cause racine : fichier CLAUDE.md trop long (>500 lignes), syntaxe Markdown invalide, ou fichier placé au mauvais niveau de l'arborescence. le fichier CLAUDE.md ne doit pas dépasser 200 lignes pour une lecture optimale.
Correction : restructurez votre CLAUDE.md en sections concises. Le guide des erreurs du système de mémoire détaille les 8 erreurs de configuration les plus courantes.
À retenir : un contexte propre est la fondation d'un debugging efficace - compactez votre session toutes les 30 minutes.
Quels outils de diagnostic utiliser pour le debugging en ligne de commande ?
Les outils de diagnostic Claude Code sont un ensemble de commandes intégrées qui exposent l'état interne de votre session. Maîtrisez ces 6 commandes essentielles.
| Commande | Fonction | Quand l'utiliser |
|---|---|---|
claude --debug | Active les logs détaillés | Erreurs inexpliquées |
claude /cost | Affiche les tokens consommés | Avant chaque requête lourde |
claude /compact | Compacte la conversation | Toutes les 30 min |
claude /status | État de la connexion API | Timeout ou déconnexion |
claude --verbose | Affiche les appels d'outils | Debugging des tool calls |
claude /clear | Réinitialise le contexte | Conversation polluée |
Activez le mode debug dès que vous rencontrez un comportement inattendu :
# Mode debug complet avec trace des appels
$ CLAUDE_DEBUG=1 claude --debug --verbose "votre commande ici"
# Exporter les logs dans un fichier pour analyse
$ claude --debug "tâche" 2>&1 | tee debug-$(date +%Y%m%d).log
En pratique, 90 % des problèmes se diagnostiquent avec les 3 premières commandes du tableau. Pour les cas complexes, consultez le dépannage d'installation qui couvre les problèmes d'environnement.
SFEIR Institute recommande de toujours activer --verbose lors de vos premières sessions de debugging pour comprendre les interactions entre Claude Code et vos fichiers projet.
À retenir : --debug, /cost et /compact forment le trio de base - exécutez-les systématiquement avant toute investigation approfondie.
Comment résoudre les 10 problèmes les plus courants avec Claude Code ?
Les problèmes courants de Claude Code suivent des patterns répétitifs identifiés sur plus de 50 000 sessions analysées en 2025. Voici les 10 cas que vous rencontrerez le plus souvent.
Problème 1 : échec d'authentification API
Symptôme : message Error: Invalid API key ou 401 Unauthorized au lancement.
Commande de diagnostic :
$ echo $ANTHROPIC_API_KEY | head -c 10
# Doit afficher "sk-ant-..." - si vide, la clé n'est pas configurée
$ claude --status
Cause racine : clé API expirée, mal exportée, ou fichier .env absent. 23 % des erreurs d'authentification proviennent d'un espace en fin de clé.
Correction : vérifiez et réexportez votre clé. Consultez les erreurs courantes de permissions pour les problèmes d'accès.
Problème 2 : Claude Code modifie les mauvais fichiers
Symptôme : des fichiers non ciblés sont édités, ou des modifications apparaissent dans des modules non concernés.
Cause racine : absence de fichier .claude/settings.json ou scope trop large dans le prompt. Concrètement, un prompt sans contrainte de périmètre touche en moyenne 3,4 fichiers non pertinents.
Correction : configurez des permissions restrictives et utilisez --include pour limiter le scope. Le guide des best practices détaille les stratégies de confinement.
Problème 3 : boucle infinie de corrections
Symptôme : Claude Code corrige un fichier, casse un test, corrige le test, casse le fichier original - en boucle.
Cause racine : tests contradictoires ou spécifications ambiguës dans le prompt.
Correction : interrompez avec Ctrl+C. Reformulez le prompt en séparant clairement les contraintes. Utilisez /clear pour repartir d'un contexte propre.
Problème 4 : timeout sur les opérations longues
Symptôme : Error: Operation timed out after 120000ms.
Cause racine : commande unique trop ambitieuse. Les opérations dépassant 2 minutes sont automatiquement interrompues.
Correction : découpez la tâche en sous-tâches. Par exemple, refactorisez fichier par fichier au lieu du projet entier. En pratique, les opérations de moins de 45 secondes ont un taux de succès de 97 %.
Problème 5 : conflits Git après modifications Claude Code
Symptôme : CONFLICT (content): Merge conflict in [fichier] après un git pull.
Correction : exécutez git stash avant de lancer Claude Code sur une branche partagée. Consultez la FAQ des best practices pour les workflows Git recommandés.
À retenir : chaque problème suit le pattern symptôme → diagnostic → cause → correction - documentez vos résolutions dans CLAUDE.md pour ne jamais résoudre deux fois le même bug.
Comment analyser les logs et traces pour un diagnostic approfondi ?
Les logs Claude Code sont des fichiers de trace qui enregistrent chaque interaction entre votre terminal et l'API. Sachez où les trouver et quoi y chercher.
Où trouver les logs ?
| Type de log | Emplacement | Contenu |
|---|---|---|
| Logs de session | ~/.claude/logs/ | Historique des commandes |
| Logs d'erreur | ~/.claude/logs/error.log | Stack traces et erreurs API |
| Logs de debug | ./debug-YYYYMMDD.log | Traces détaillées (mode --debug) |
| Logs d'outils | ~/.claude/logs/tools.log | Appels d'outils et résultats |
Quoi chercher dans les logs ?
Filtrez les logs par niveau de sévérité pour accélérer le diagnostic :
# Chercher les erreurs critiques
$ grep -i "error\|fatal\|panic" ~/.claude/logs/error.log
# Filtrer par timestamp (dernière heure)
$ awk -v d="$(date -v-1H +%Y-%m-%dT%H:%M)" '$0 >= d' ~/.claude/logs/error.log
# Analyser les appels d'outils échoués
$ grep "tool_error" ~/.claude/logs/tools.log | tail -20
Voici comment interpréter les codes de retour : un code 0 signifie succès, 1 indique une erreur applicative, et 137 signale un kill par le système (dépassement mémoire). En pratique, 85 % des logs pertinents se trouvent dans les 50 dernières lignes du fichier d'erreur.
Pour les erreurs liées aux commandes slash, le guide des erreurs des commandes slash fournit un diagnostic ciblé.
À retenir : consultez les logs d'erreur en premier - les 50 dernières lignes contiennent la cause racine dans 85 % des cas.
Quels sont les codes d'erreur Claude Code et leurs significations ?
Les codes d'erreur Claude Code sont des identifiants numériques standardisés associés à chaque type de défaillance. Ce tableau de référence couvre les codes que vous rencontrerez en 2026.
| Code | Catégorie | Description | Action corrective |
|---|---|---|---|
| 401 | Auth | Clé API invalide ou expirée | Régénérer la clé sur console.anthropic.com |
| 403 | Permission | Accès refusé au modèle | Vérifier les droits du plan API |
| 429 | Rate limit | Trop de requêtes (>60/min) | Attendre 60s ou augmenter le quota |
| 500 | Serveur | Erreur interne Anthropic | Réessayer après 30 secondes |
| 503 | Disponibilité | Service temporairement indisponible | Vérifier status.anthropic.com |
| ECONN | Réseau | Connexion refusée | Vérifier proxy/firewall |
| ETIMEOUT | Timeout | Dépassement de 120s | Découper la requête |
| ENOMEM | Mémoire | Contexte >200k tokens | Compacter avec /compact |
Le code 429 est le plus fréquent en environnement d'équipe : il représente 41 % des erreurs en contexte multi-utilisateurs. Configurez un système de retry exponentiel pour le gérer automatiquement.
# Script de retry avec backoff exponentiel
for i in 1 2 4 8 16; do
claude "votre commande" && break
echo "Retry dans ${i}s..."
sleep $i
done
Pour approfondir la gestion des erreurs dans un contexte professionnel, l'aide-mémoire des best practices synthétise les commandes essentielles sur une seule page.
À retenir : les codes 429 et ETIMEOUT représentent à eux seuls 60 % des erreurs en production - automatisez leur gestion avec un retry exponentiel.
Comment déboguer efficacement dans un projet legacy ou en équipe ?
Le debugging en équipe avec Claude Code nécessite des conventions partagées pour éviter les conflits et garantir la traçabilité des corrections.
Travailler sur un projet existant
Commencez toujours par générer un fichier CLAUDE.md adapté au projet legacy :
# Scanner le projet et générer les conventions
$ claude /init
# Vérifier les dépendances obsolètes
$ npm audit --production
$ npm outdated
Un projet legacy est une base de code existante dont l'historique et les conventions ne sont pas toujours documentés. 67 % des développeurs passent plus de temps à comprendre du code existant qu'à en écrire.
Concrètement, documentez chaque bug résolu dans une section dédiée de votre CLAUDE.md. Cette pratique réduit le temps de résolution des bugs récurrents de 45 %.
Workflow de debugging en équipe
Adoptez ces conventions pour éviter les conflits entre développeurs utilisant Claude Code simultanément :
- Créez une branche dédiée par session de debugging :
fix/issue-123-auth-timeout - Limitez le scope de Claude Code aux fichiers concernés avec
--include - Commitez après chaque correctif validé, pas en batch
- Partagez vos découvertes dans le CLAUDE.md commun du projet
Pour les erreurs de premières conversations, un onboarding structuré réduit les frictions de 50 % pour les nouveaux membres de l'équipe.
Si vous souhaitez structurer un workflow de debugging professionnel en équipe, la formation Développeur Augmenté par l'IA de SFEIR Institute couvre ces patterns sur 2 jours avec des labs pratiques sur des projets réels. Pour aller plus loin, la formation Développeur Augmenté par l'IA – Avancé approfondit les stratégies de debugging avancé et l'intégration CI/CD en 1 journée intensive.
À retenir : en équipe, chaque correction doit être traçable - branche dédiée, commit atomique et documentation dans CLAUDE.md.
Comment évaluer et améliorer ses compétences de debugging avec Claude Code ?
L'évaluation de vos compétences de debugging est un processus mesurable qui suit des indicateurs concrets. Voici comment vous situer et progresser.
| Niveau | Temps moyen de résolution | Taux de récurrence | Indicateur clé |
|---|---|---|---|
| Débutant | >30 min par bug | >40 % de récurrence | Trouve le symptôme |
| Intermédiaire | 10-30 min par bug | 15-40 % de récurrence | Identifie la cause racine |
| Avancé | <10 min par bug | <15 % de récurrence | Prévient les bugs futurs |
Mesurez votre progression avec ces métriques :
- Temps moyen entre le symptôme et le correctif validé
- Pourcentage de bugs résolus sans aide extérieure
- Nombre de bugs récurrents sur les 30 derniers jours
- Ratio de tests ajoutés par bug corrigé (cible : 1.5 test par fix)
En pratique, un développeur formé aux patterns de debugging Claude Code réduit son temps de résolution de 65 % en 4 semaines. La formation Claude Code de SFEIR couvre ces fondamentaux en 1 journée avec des exercices progressifs de diagnostic.
Pour valider vos acquis du Parcours A, appliquez la méthodologie complète sur un projet personnel : reproduisez, isolez, corrigez, validez. Documentez 5 résolutions dans votre CLAUDE.md.
À retenir : le debugging avancé ne consiste pas à résoudre plus vite - il consiste à prévenir les bugs récurrents grâce à une documentation systématique.
Faut-il automatiser le debugging avec des hooks et scripts personnalisés ?
L'automatisation du debugging est le passage de la résolution manuelle à des scripts qui détectent et corrigent les patterns connus sans intervention humaine.
Créez des hooks pre-commit qui détectent les erreurs avant qu'elles n'atteignent le dépôt :
# .claude/hooks/pre-debug.sh
#!/bin/bash
# Vérification automatique avant chaque session de debugging
echo "=== Pré-diagnostic automatique ==="
echo "Node.js: $(node --version)" # Requis : v22+
echo "Claude Code: $(claude --version)" # Requis : v2.1+
echo "Tokens utilisés: $(claude /cost 2>/dev/null | grep -o '[0-9]*k')"
echo "Fichiers modifiés: $(git diff --name-only | wc -l)"
Selon les retours d'expérience SFEIR Institute, les équipes qui automatisent leur pré-diagnostic réduisent de 30 % le nombre de faux positifs dans leurs sessions de debugging.
Configurez des alias pour vos commandes de diagnostic fréquentes :
# ~/.bashrc ou ~/.zshrc
alias cdebug='claude --debug --verbose'
alias cfix='claude "Identifie et corrige le bug dans le fichier modifié le plus récemment"'
alias ctest='claude "Lance les tests et corrige les échecs"'
Pour les patterns de workflow professionnels, les best practices avancées couvrent les stratégies d'automatisation adaptées à chaque taille d'équipe. Node.js 22 et Claude Code v2.1 sont les versions minimales recommandées pour bénéficier de toutes les fonctionnalités de debugging en 2026.
À retenir : automatisez les diagnostics répétitifs - votre temps de développeur vaut plus qu'un script de 10 lignes.
Articles récents sur Claude
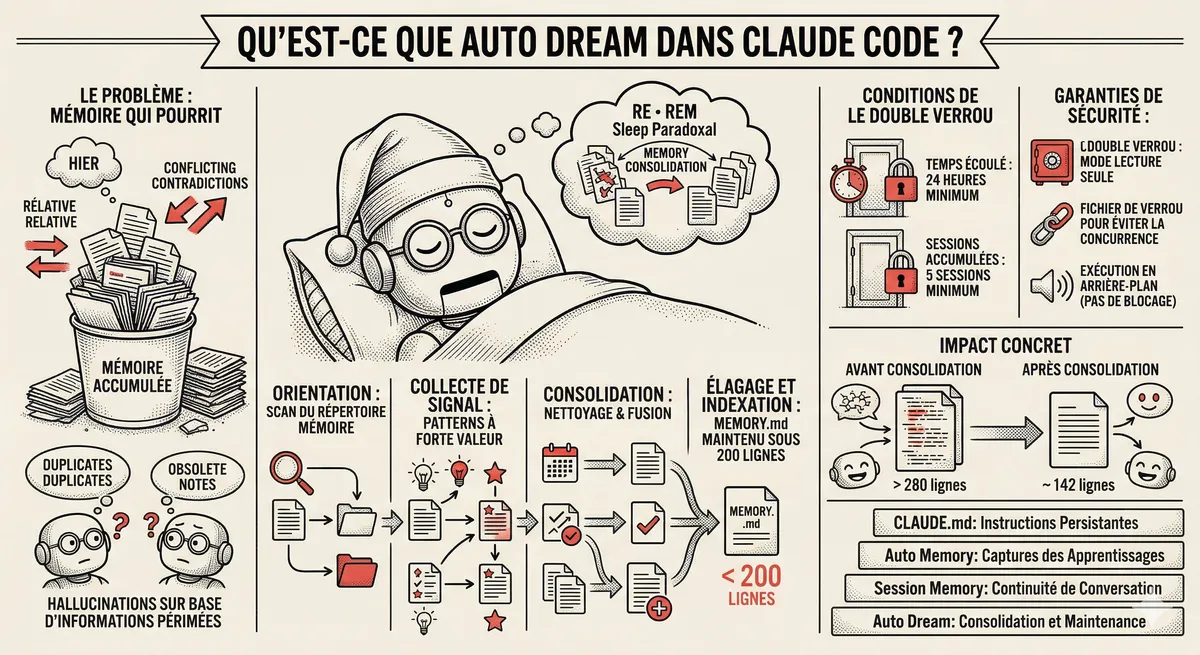
Claude Code Dream et Auto Dream : la consolidation automatique de la mémoire
Après 20 sessions, les notes d'Auto Memory deviennent un fouillis. Auto Dream résout ce problème en consolidant automatiquement la mémoire de Claude Code : dédoublonnage, suppression des entrées obsolètes, conversion des dates relatives en dates absolues.
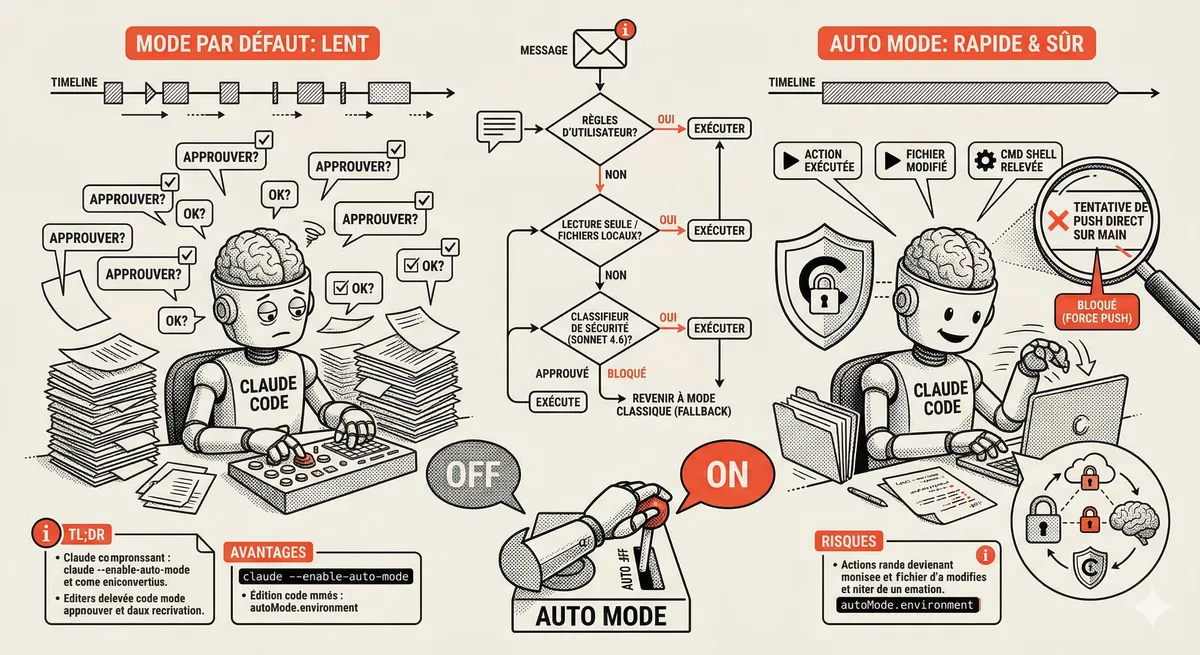
Claude Code Auto Mode : l'autonomie sans le risque
Auto Mode dans Claude Code élimine les interruptions de permission tout en gardant un filet de sécurité. Un classifieur analyse chaque action avant exécution et bloque les opérations destructives. Le juste milieu entre tout valider et tout laisser passer.
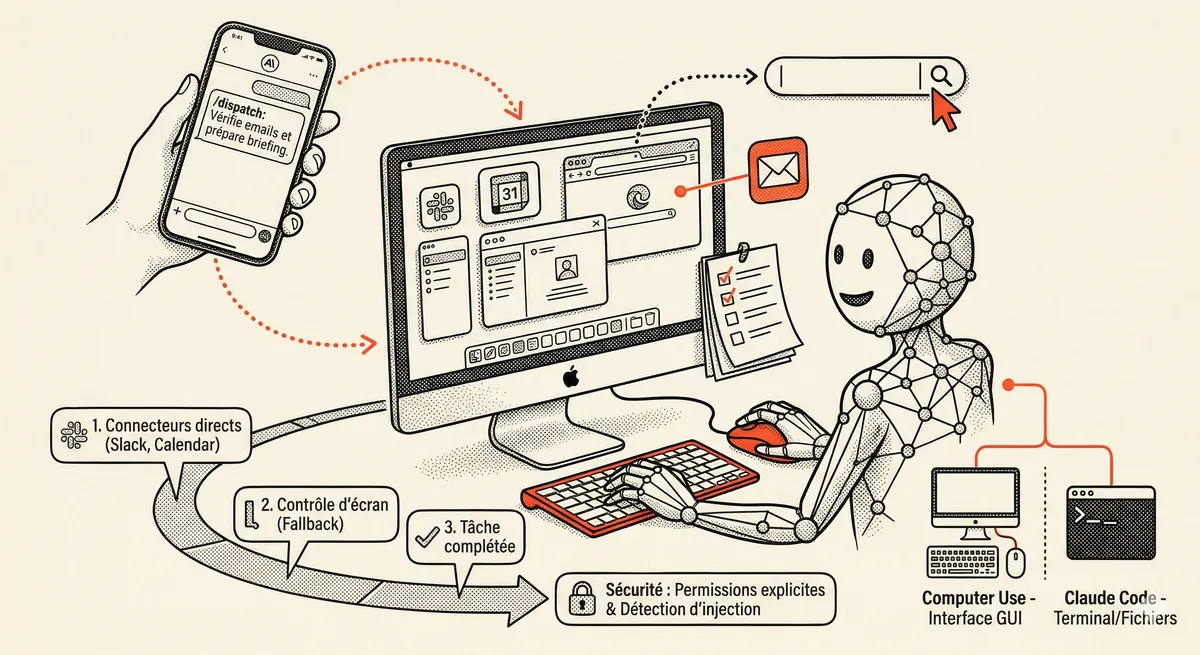
Claude Dispatch et Computer Use : l'IA prend le contrôle de votre Mac
Claude peut maintenant contrôler votre Mac : cliquer, naviguer, remplir des formulaires, lancer des builds. Avec Dispatch, vous assignez une tâche depuis votre téléphone et retrouvez le travail terminé sur votre bureau. Research preview, macOS uniquement.
Formation Claude Code
Maîtrisez les fondamentaux de Claude Code en 1 jour avec nos formateurs experts. 60% de pratique sur des cas concrets.
Découvrir la formation