Le contexte de 1M tokens arrive en GA partout
TL;DR Le contexte de 1M tokens est maintenant en GA chez les deux principaux fournisseurs. Gemini 3.1 Pro l'a proposé en premier (février 2026, 2-4$/M tokens). Claude Opus 4.6 et Sonnet 4.6 suivent en mars 2026 (3-5$/M tokens), sans surcoût long-context. Anthropic met en avant la qualité de retrieval (78.3% MRCR v2 vs 26.3% pour Gemini 3 Pro). Résultat concret : un LLM peut ingérer un codebase entier ou maintenir des sessions d'agents de plusieurs heures sans perte de contexte.
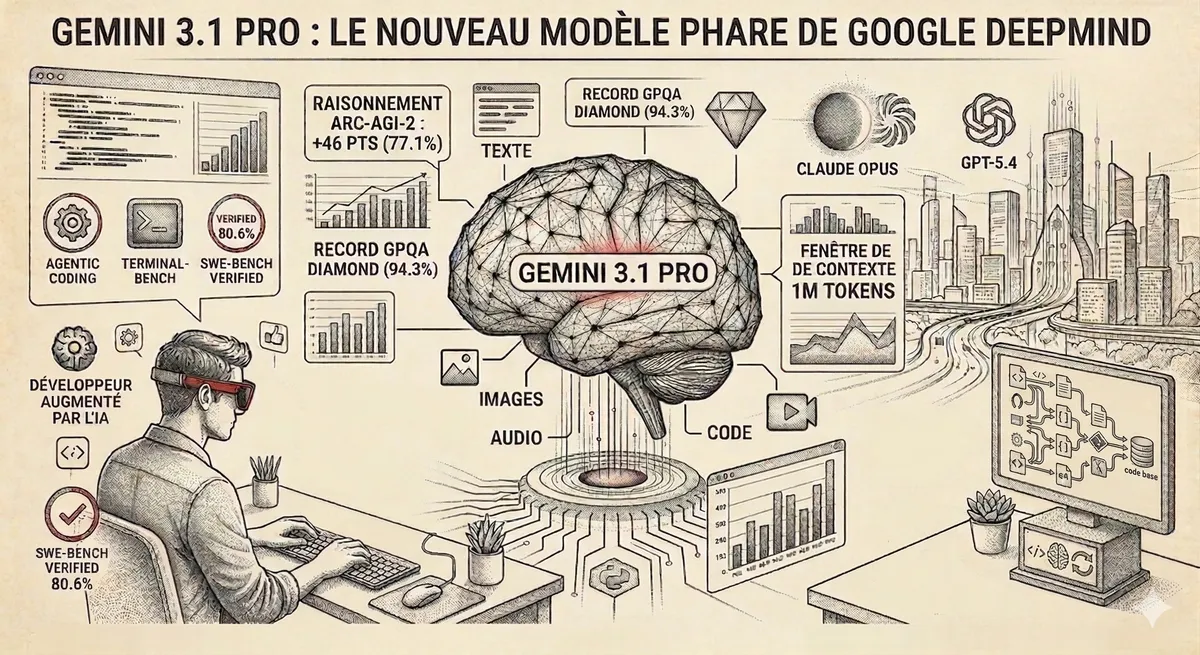
Gemini a ouvert la voie. Dès février 2026, Gemini 3.1 Pro proposait 1M tokens de contexte en GA sur Vertex AI et Google AI Studio. C'était le premier modèle frontier à offrir cette capacité en production, à un tarif compétitif de 2$/12$ par million de tokens.
Le 13 mars 2026, Anthropic suit en passant Claude Opus 4.6 et Sonnet 4.6 en GA avec la même fenêtre de 1M tokens. Trois changements concrets :
1. Plus de surcoût - une requête de 900K tokens est facturée au même tarif par token qu'une requête de 9K. Fini le multiplicateur long-context
2. Débit standard sur toute la fenêtre - les rate limits ne sont plus réduites au-delà de 200K tokens
3. 6x plus de médias - jusqu'à 600 images ou pages PDF par requête, contre 100 avant
Pas de header bêta requis. Pas de changement de code. Si vous êtes sur Max, Team ou Enterprise, c'est automatique.
Combien ça coûte ?
| Modèle | Input | Output |
|---|---|---|
| Opus 4.6 | 5$ / M tokens | 25$ / M tokens |
| Sonnet 4.6 | 3$ / M tokens | 15$ / M tokens |
Le prix est identique quelle que soit la longueur du contexte. Une requête de 1M tokens d'entrée sur Sonnet coûte 3$. Sur Opus, 5$.
Pour comparaison, Gemini 3.1 Pro facture 2$/12$ par million de tokens jusqu'à 200K, puis 4$/18$ au-delà. Sur les contextes longs, Gemini reste moins cher en input mais Anthropic a supprimé son multiplicateur.
La taille ne fait pas tout : la qualité du retrieval
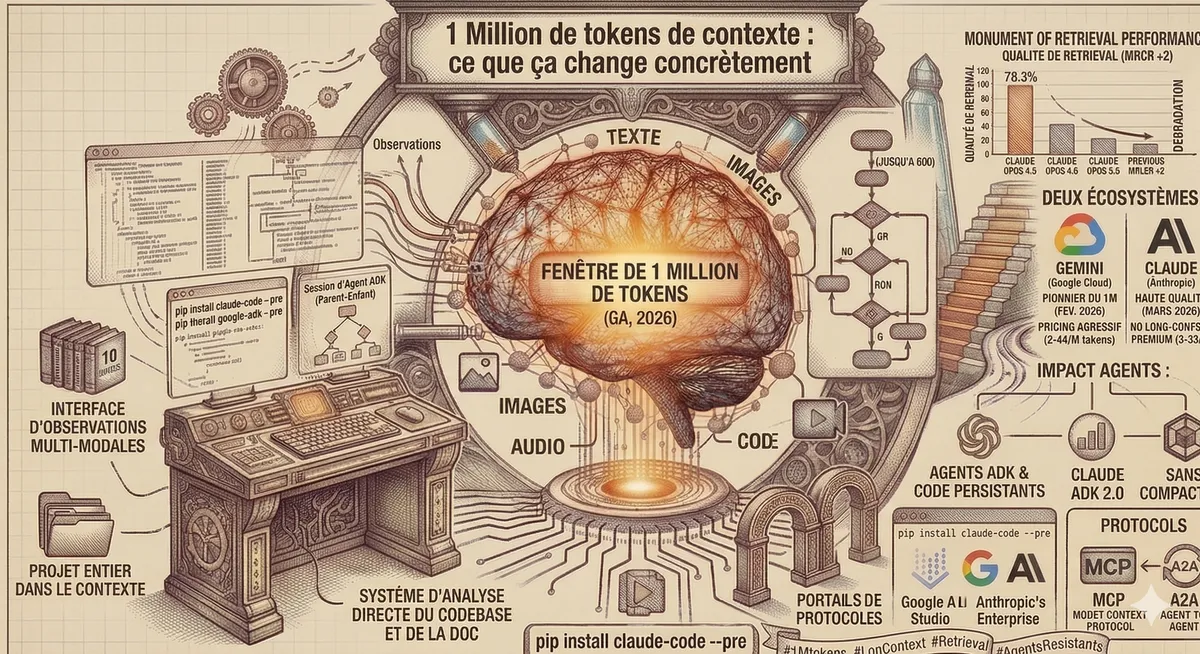
Avoir 1M tokens de contexte ne sert à rien si le modèle oublie ce qu'il a lu à la page 50. C'est le problème historique du "lost in the middle" : les modèles perdent en précision sur les informations situées au milieu de la fenêtre.
Le benchmark MRCR v2 (Multi-needle Retrieval over Complex Reasoning) mesure spécifiquement cette capacité : retrouver et raisonner sur des informations dispersées dans un long contexte.
| Modèle | MRCR v2 |
|---|---|
| Claude Opus 4.6 | 78.3% (record) |
| Gemini 3 Pro | 26.3% |
| Claude précédent (meilleur) | 18.5% |
Sur ce benchmark, Opus 4.6 se dégrade nettement moins que ses concurrents quand le contexte s'allonge. C'est l'argument principal d'Anthropic : la fenêtre est non seulement grande, mais la qualité de retrieval tient sur toute sa longueur. A noter que ce benchmark compare Gemini 3 Pro (pas 3.1 Pro), et que Google n'a pas encore publié de score MRCR v2 pour 3.1 Pro.
Pourquoi 1M de contexte change la donne ?
La fin du "context engineering"
Jusqu'ici, une part importante du travail avec les LLMs consistait à gérer le contexte : découper les documents, résumer les passages clés, choisir quoi inclure et quoi exclure, compresser les conversations longues. Avec 1M de tokens, ce travail disparaît pour la majorité des cas d'usage.
1 million de tokens, c'est environ :
- ~750 000 mots - l'équivalent de 10 livres
- Un codebase complet - la plupart des projets tiennent dans 1M de tokens
- Des milliers de pages de contrats, de documentation technique, de rapports
Les agents peuvent enfin fonctionner longtemps
C'est l'impact le plus concret pour les deux écosystèmes. Un agent IA qui exécute une tâche complexe accumule du contexte : appels d'outils, résultats d'observation, raisonnement intermédiaire. Avec une fenêtre limitée, l'agent doit compresser (compaction) et perd de l'information.
Chez Anthropic, Jon Bell (CPO) rapporte "une baisse de 15% des événements de compaction. Nos agents maintiennent maintenant tout le contexte et tournent pendant des heures sans oublier ce qu'ils ont lu en page 1."
Côté Google, Gemini CLI et les agents ADK bénéficient du même avantage. Un agent ADK 2.0 qui orchestre plusieurs sous-agents sur Gemini 3.1 Pro peut maintenir l'intégralité du contexte de la tâche sans compression.
Côté Anthropic, dans Claude Code, les sessions utilisent automatiquement la fenêtre complète sur Opus 4.6. Anton Biryukov (Software Engineer) : "Claude Code peut brûler 100K+ tokens en recherche. Avec 1M de contexte, je cherche, re-cherche, agrège les edge cases et propose des fixes, le tout dans une seule fenêtre."
Le codebase complet en une seule requête
Avant, analyser un projet de taille moyenne nécessitait de sélectionner les fichiers pertinents, de naviguer entre les modules, de reconstruire mentalement les dépendances. Maintenant, on charge tout. Le modèle voit l'ensemble du projet : les imports, les types, les tests, la configuration, la documentation.
Les implications pour le développement :
- Code review : le modèle lit tout le code touché par une PR, plus le code adjacent
- Refactoring : le modèle comprend les impacts à travers tout le codebase
- Debugging : traces complètes, logs, code source, tout dans la même fenêtre
- Documentation : le modèle génère de la documentation en ayant lu l'intégralité du projet
Gemini vs Claude : deux approches du 1M tokens
Les deux offrent 1M tokens en GA. Les stratégies diffèrent.
| Gemini 3.1 Pro | Claude Opus 4.6 | Claude Sonnet 4.6 | |
|---|---|---|---|
| Contexte | 1M in / 64K out | 1M in | 1M in |
| GA depuis | Février 2026 | Mars 2026 | Mars 2026 |
| Input pricing | 2-4$ / M tokens | 5$ / M tokens | 3$ / M tokens |
| Output pricing | 12-18$ / M tokens | 25$ / M tokens | 15$ / M tokens |
| MRCR v2 | 26.3%* | 78.3% | - |
| Médias par requête | - | 600 | 600 |
*Score de Gemini 3 Pro. Pas de benchmark MRCR v2 publié pour Gemini 3.1 Pro.
Gemini a été le pionnier du 1M en production, avec un pricing plus agressif. C'est le choix logique pour les équipes Google Cloud et les cas d'usage où le volume d'appels prime.
Claude arrive un mois plus tard mais met en avant la qualité de retrieval : Opus 4.6 se dégrade moins sur les contextes longs, selon MRCR v2. C'est l'argument pour les cas où la précision sur l'ensemble de la fenêtre est critique (code review, analyse juridique, debugging).
En pratique, les deux fonctionnent. Le choix se fait sur l'écosystème cloud, le pricing et le cas d'usage.
Pour aller plus loin
Le contexte de 1M tokens transforme la façon de travailler avec les LLMs. Notre formation Claude Code enseigne comment exploiter cette capacité : sessions longues, chargement de codebases complets, agents persistants. La formation Développeur Augmenté par l'IA couvre plus largement l'intégration des LLMs dans le workflow de développement, y compris la gestion du contexte et le prompt engineering.