Qu'est-ce que Gemini 3.1 Pro ?
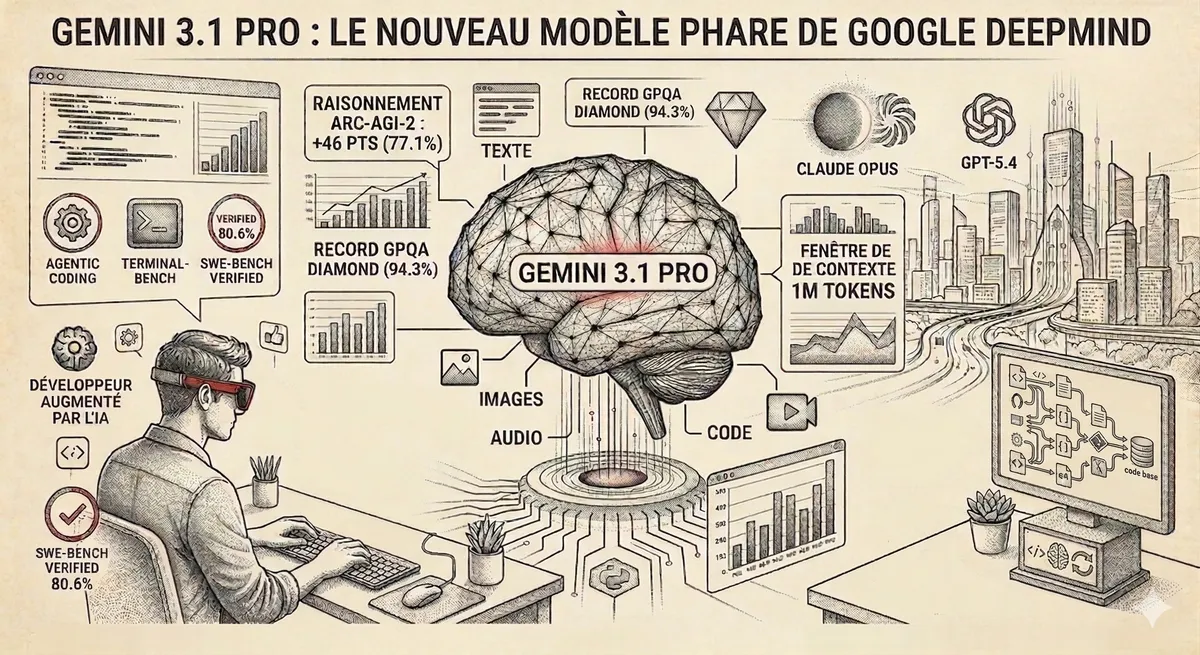
TL;DR Google lance Gemini 3.1 Pro le 19 février 2026. Le bond en raisonnement est massif : 77.1% sur ARC-AGI-2 contre 31.1% pour Gemini 3 Pro (+46 pts). Record sur GPQA Diamond (94.3%) et LiveCodeBench (2887 Elo). Fenêtre de contexte 1M tokens en production. Prix inchangé : 2$/12$ par million de tokens. Disponible sur Vertex AI, Gemini CLI, Google AI Studio et Gemini app.
Gemini 3.1 Pro est le modèle IA le plus avancé de Google DeepMind, lancé le 19 février 2026 et disponible sur Google Cloud le lendemain. Il accepte cinq modalités en entrée (texte, images, audio, vidéo, code), dispose d'une fenêtre de contexte de 1 million de tokens en entrée et 64 000 tokens en sortie.
Le saut par rapport à Gemini 3 Pro est le plus grand gain de raisonnement jamais observé entre deux générations d'un même modèle : +46 points sur ARC-AGI-2 (31.1% → 77.1%).
Quels sont les benchmarks ?
Raisonnement et science
| Benchmark | Gemini 3.1 Pro | Gemini 3 Pro | Catégorie |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | 31.1% | Raisonnement logique |
| GPQA Diamond | 94.3% (record) | - | Science niveau doctorat |
| MATH | 95.1% | - | Mathématiques |
| MMMLU | 93.6% | - | Connaissances générales |
| SciCode | 59% | - | Code scientifique |
Coding et ingénierie logicielle
| Benchmark | Score | Catégorie |
|---|---|---|
| LiveCodeBench Pro | 2887 Elo (record) | Coding compétitif |
| SWE-Bench Verified | 80.6% | Résolution d'issues GitHub |
| SWE-Bench Pro | 54.2% | Multi-langages |
| Terminal-Bench 2.0 | 68.5% | Exécution terminal/agentic |
Capacités agentiques
| Benchmark | Score | Catégorie |
|---|---|---|
| APEX-Agents | 33.5% | Exécution autonome multi-étapes |
| MCP Atlas | 69.2% | Coordination multi-outils |
| BrowseComp | 85.9% | Navigation web |
Le modèle est #1 sur 12 des 18 benchmarks suivis par les classements publics.
Combien ça coûte ?
Le prix reste identique à Gemini 3 Pro :
| Contexte | Input | Output |
|---|---|---|
| ≤ 200K tokens | 2$ / M tokens | 12$ / M tokens |
| > 200K tokens | 4$ / M tokens | 18$ / M tokens |
Le rapport performance/prix est le point fort de ce lancement. Le gain de +46 points sur ARC-AGI-2 à prix constant place Gemini 3.1 Pro parmi les modèles les plus compétitifs du marché en termes de coût par unité de raisonnement.
Où est-il disponible ?
- Vertex AI - pour les déploiements entreprise sur Google Cloud
- Google AI Studio - pour le prototypage et les tests
- Gemini CLI - pour les développeurs en terminal
- Gemini app - pour les utilisateurs grand public
- NotebookLM - pour l'analyse de documents
- Android Studio - pour le développement mobile
- Google Antigravity - plateforme de développement agentique
Le contexte de 1M tokens est en production, pas en bêta. C'est actuellement le seul modèle frontier offrant 1M de contexte en GA.
Ce qu'en disent les premiers utilisateurs
Les retours des entreprises en accès anticipé confirment les benchmarks.
JetBrains (Vladislav Tankov, Director of AI) : "Nous avons observé jusqu'à 15% d'amélioration par rapport aux meilleurs runs de Gemini 3 Pro Preview. Le modèle est plus fort, plus rapide, et plus efficient, avec moins de tokens en sortie pour des résultats plus fiables."
Databricks (Hanlin Tang, CTO Neural Networks) : "Gemini 3.1 Pro a montré un raisonnement impressionnant pour les tâches spécifiques à l'entreprise, avec des résultats best-in-class sur OfficeQA, notre benchmark pour le raisonnement ancré combinant données tabulaires et non structurées."
Cartwheel (Andrew Carr, Co-Founder & Chief Scientist) : "Gemini 3.1 Pro a une compréhension substantiellement améliorée des transformations 3D. Nous avons pu corriger un bug de longue date dans un de nos pipelines d'export d'animation grâce à ce modèle."
Hostinger (Dainius Kavoliunas, Head of Product) : "Ce qui distingue Gemini 3.1 Pro, c'est sa compréhension profonde de l'intention derrière le prompt. L'amélioration du raisonnement est immédiatement perceptible."
Quelles sont les améliorations en coding ?
Gemini 3.1 Pro apporte des améliorations spécifiques pour le développement logiciel :
- Instruction following amélioré pour les workflows agentiques
- Tool use renforcé - meilleure coordination avec les outils externes (MCP Atlas : 69.2%)
- Nouveau niveau de thinking - le paramètre
thinking_level: MEDIUMpermet d'optimiser le compromis coût/performance/vitesse - 80.6% sur SWE-Bench Verified - le modèle comprend une issue, navigue dans le codebase, écrit le correctif et vérifie qu'il ne casse rien
Le score Terminal-Bench de 68.5% montre que le modèle gère la navigation dans les systèmes de fichiers, les dépendances et l'exécution de builds dans des environnements terminaux réels.
Comment se positionne-t-il face à la concurrence ?
En mars 2026, trois modèles se disputent le haut du classement : Gemini 3.1 Pro, Claude Opus 4.6 et GPT-5.4.
Sur SWE-Bench Verified, les trois modèles sont à moins de 0.8 point d'écart, statistiquement équivalents pour la résolution d'issues GitHub. Les différences se jouent ailleurs :
- Gemini 3.1 Pro domine en raisonnement pur (ARC-AGI-2, MATH, GPQA) et offre le meilleur rapport qualité/prix
- Claude excelle en instruction following, en sortie structurée et en tâches d'écriture nuancée
- Le contexte 1M tokens de Gemini est en GA, celui de Claude est encore en bêta
Pour les équipes Google Cloud, Gemini 3.1 Pro est le choix naturel : intégration native Vertex AI, pricing compétitif, et accès via Gemini CLI pour les workflows de développement.
Pour aller plus loin
SFEIR Institute est Google Cloud Training Partner of the Year 2025. Nos formations couvrent l'ensemble de l'écosystème Google Cloud et IA. La formation Développeur Augmenté par l'IA enseigne comment intégrer les modèles comme Gemini dans votre workflow quotidien, et la formation AI Engineer va plus loin sur la construction de systèmes autonomes.

